









搭建环境:
jdk1.7.0
ubuntu 14.0.4
hadoop 2.4.0
因为涉及系统的修改很多,所以一开始就请登录root权限,省去很多麻烦。
1. 安装ssh
apt-get install ssh
apt-get install rsync
2. To get a Hadoop distribution,我下载的是2.4.0版本
3. 解压文件放置到常用路径并添加软链
tar xvf hadoop-2.4.0
mv hadoop-2.4.0 /usr/local
ln -s hadoop-2.4.0 hadoop
4. 打开etc/hadoop/hadoop-env.sh文件
修改如下两句话:
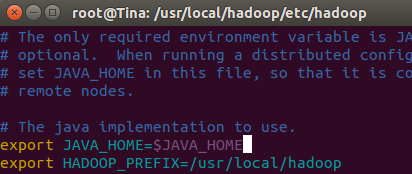
其中$JAVA_HOME是在/etc/profile文件中设置好的。第二句话要自己加上去。
========================================================
后来在进行hdfs启动工作时报错0.0.0.0: Error: JAVA_HOME is not set and could not be found.
说找不到JAVA_HOME,所以后来我直接把第一行给成了绝对路径:
就没有报错了。
========================================================
编辑后我的/etc/profile文件添加了如下语句:

5. 因为我们把Hadoop添加到了PATH中,所以在配置好了文件后我们可以直接输入hadoop
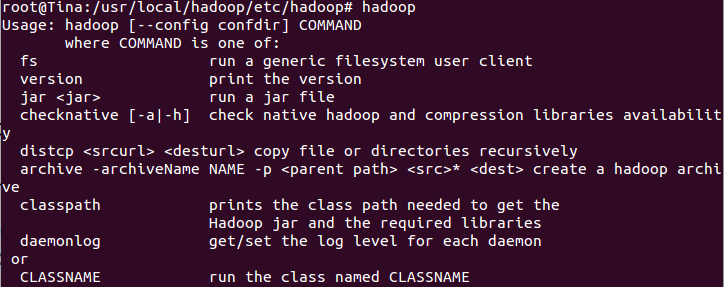
本次搭建我只用了一台电脑,所以我搭建的是伪分布模式(“Hadoop can also be run on a single-node in a pseudo-distributed mode where each Hadoop daemon runs in a separate Java process.”——Apache Hadoop)。
6. 编辑配置文件:
etc/hadoop/core-site.xml:

etc/hadoop/hdfs-site.xml:
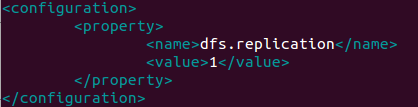
7.创建密钥:
$ ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
$ cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys ssh localhost
8. 现在我们可以尝试一下hadoop上的mapreduce了
8.1 格式化文件系统
hdfs namenode -format
8.2 Start NameNode daemon and DataNode daemon(The hadoop daemon log output is written to the$HADOOP_LOG_DIRdirectory (defaults to $HADOOP_HOME/logs).)
进入$HADOOP_HOME路径下:
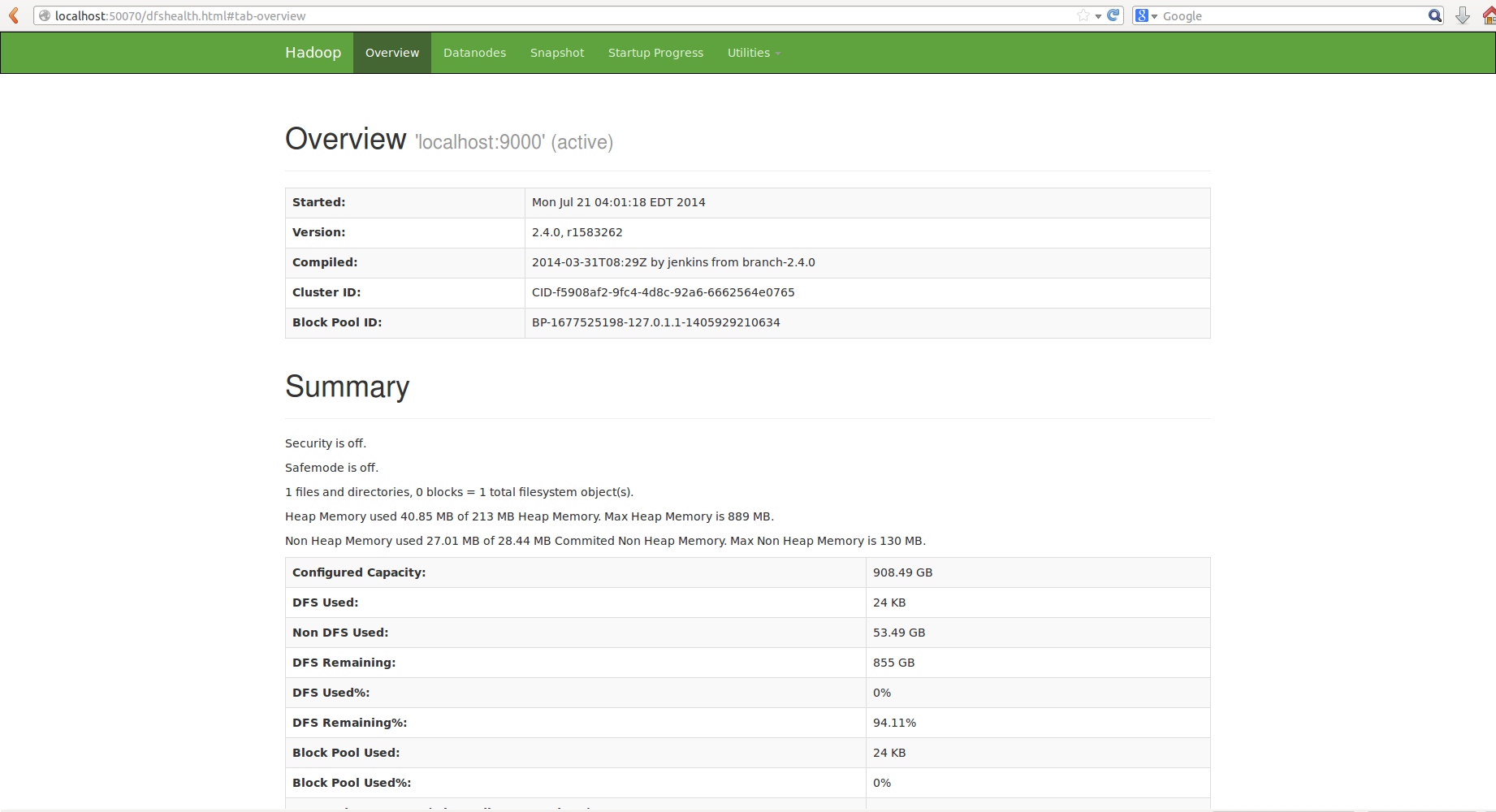
sbin/start-dfs.sh8.3 我们可以通过http://localhost:50070/进入网页接口查看节点状况:
8.4 创建运行Mapreduce任务的文件夹:
hdfs dfs -mkdir /user
hdfs dfs -mkdir /user/tina8.5 将input文件放入我们的分布式系统:
在$HADOOP_HOME路径下建立input文件夹:
mkdir input
cp etc/hadoop/*.xml input
hdfs dfs -put $HADOOP_HOME/input /input
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.4.0.jar grep /input/input /output 'dfs[a-z.]+'
成功。
8.6 下载output文件夹到本地文件系统:
hdfs dfs -get output output
cd /
cd output
cat part-r-00000
8.7 结束进程:
sbin/stop-dfs.sh
===============================================================================================================================
心得:路径的辨识是一件很重要的事情,我是照着官网的指示一步一步做的,但是做到hdfs上传文件时还是一而再再而三地报错,学长说大概因为官网用的和我不一样的系统所以路径的表达方式会不一样。本次亲手实践后觉得,虽然hadoop确实很精妙,但是它有很大的局限性,比如它原生态的版本基本就只有hdfs和mapreduce,功能相当局限。这样一来就很能理解yarn,hbase,hive等等出现的原因了。大数据架构深似海阿。















 687
687

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









