







一、CART决策树和ID3决策树的区别在哪里:
区别主要体现在对于连续型特征的处理方式,ID3决策树完全根据特征值等于几,做决策分支,这肯定容易出现很多很多分支,即所谓过拟合。
CART决策树在一定程度上缓解了这个问题,比如对于样本S的特征A的特征值1、2、3、4、5、6,如果是ID3决策树,那么可能会有6个分支,而对于CART决策树,只会有2个分支,如"特征A是否大于3.5",这也就是所谓CART决策树是一个二叉树,他对于连续型特征,只做二分切分。
CART和ID3的另一个区别是,CART使用基尼系数而不是熵,作为判断概率分布是否集中的标准。
二、CART决策树实现:
区别于ID3的主要是两个内容,一个是基尼系数,一个是连续型特征如何做分叉
1、基尼系数:
gini(A = AX) = 1 - sum(p(i) * p(i))
即特征A在取值AX时,1减去各个结果i的概率p(i)的乘积
基尼系数越小,反映概率分布越平稳,应优先作为分叉的特征。
2、连续型特征如何分叉:
对该特征A的所有特征值A1-AN排序,每两个特征值获取平均值,取得N-1个有序平均值,计算每个平均值的样本数据子集的基尼系数,取其中最小者,对所有特征均做此计算,基尼系数最小的特征及其最小基尼系数的平均值,作为分叉条件
如样本S的特征A的特征值1、2、3、4、5、6,并计算得平均值3,.5的样本数据子集的基尼系数最低,特征B的特征值1、2、3、4、5、6,并计算得平均值1,.5的样本数据子集的基尼系数最低,特征C的特征值1、2、3、4、5、6,并计算得平均值2,.5的样本数据子集的基尼系数最低.........最后得出最低基尼系数为特征A的平均值3.5,那么特征A是否大于3.5,作为分叉特征条件。
本例中,离散型特征同样计算基尼系数并和连续型特征一起参与比较,计算方式和ID3一样。
3、实现
#coding: utf8
from numpy import *
import pandas as pd
from math import log
import operator
from treeplot import *
import sys
def vote (dataset):
map = {}
for data in dataset:
if map.has_key(data):
map[data] += 1
else:
map[data] = 1
max = -1
best = 0
for data in map:
cnt = map[data]
if max < cnt:
max = cnt
best = data
return best
def calcgini (dataset):
results = [data[-1] for data in dataset]
map = {}
for result in results:
if map.has_key(result):
map[result] += 1
else:
map[result] = 1
gini = 1.0
for result in map:
cnt = map[result]
p = float(cnt) / len(dataset)
gini -= p * p
return gini
def splitdata_disper (dataset, i, value):
splitdata = []
for data in dataset:
curvalue = data[i]
if curvalue == value:
tmp = data[:i]
tmp.extend(data[i + 1:])
splitdata.append(tmp)
return splitdata
def splitdata_contigus (dataset, i, value, flag):
splitdata = []
for data in dataset:
curvalue = data[i]
if flag == 0:
if curvalue > value:
leftpart = data[:i]
leftpart.extend(data[i + 1:])
splitdata.append(leftpart)
else:
if curvalue <= value:
leftpart = data[:i]
leftpart.extend(data[i + 1:])
splitdata.append(leftpart)
return splitdata
def getaverages (values):
sorted_values = sorted(values)
averages = []
for i in range(len(sorted_values) - 1):
average = float(sorted_values[i] + sorted_values[i + 1]) / 2
averages.append(average)
return averages
def get_type (data):
if type(data).__name__ in ['float', 'int', 'long']:
return 1
else:
return 0
def choose_bestfeature (dataset, labels):
sum = len(dataset)
bestgini = 100000.0
bestfeatureidx = -1
bestvalue_contigus = 0.0
type = 0
#遍历每一种特征
for i in range(len(labels)):
values = [data[i] for data in dataset]
type = get_type(values[0])
#如果是连续型,首先计算出所有连续特征值的排序后交叉均值
#然后按这些均值为界,依次计算不同拆分结果的基尼系数,取基尼系数最小者
if type == 1:
averages = getaverages(values)
mingini_contigus = 100000.0
bestvalue = 0.0
for average in averages:
lesspart = splitdata_contigus(dataset, i, average, 0)
lesspart_p = float(len(lesspart)) / sum
leftpart_gini = lesspart_p * calcgini(lesspart)
morepart = splitdata_contigus(dataset, i, average, 1)
morepart_p = float(len(morepart)) / sum
morepart_gini = morepart_p * calcgini(morepart)
gini = leftpart_gini + morepart_gini
if gini < mingini_contigus:
mingini_contigus = gini
bestvalue = average
if mingini_contigus < bestgini:
bestfeatureidx = i
bestvalue_contigus = bestvalue
type = 1
#如果是离散型,直接取基尼系数最小者的特征
else:
mingini_disper = 100000.0
values = set(values)
for value in values:
otherpart = splitdata_disper(dataset, i, value)
p = float(len(otherpart)) / len(dataset)
gini = p * calcgini(otherpart)
if gini < mingini_disper:
mingini_disper = gini
if mingini_disper < bestgini:
bestfeatureidx = i
type = 0
#如果是连续性特征作为最优特征,要做二值化,就是根据是否大于最优均值,将标签名称和数据,都做二值化
#为什么要做二值化,不是三值化,四值化?因为标准CART决策树是一个二叉树,就是根据每个连续型特征是否大于某值来分叉
if type == 1:
labels[bestfeatureidx] = labels[bestfeatureidx] + " > " + str(bestvalue_contigus)
for data in dataset:
curvalue = data[bestfeatureidx]
if data[bestfeatureidx] > bestvalue_contigus:
data[bestfeatureidx] = 1
else:
data[bestfeatureidx] = 0
return bestfeatureidx
def createtree (dataset, labels):
results = [data[-1] for data in dataset]
#只剩下一种结果时,
if len(results) == results.count(results[0]):
return results[0]
#只剩下结果没有特征了
if len(dataset[0]) == 1:
return vote(results)
bestfeatureidx = choose_bestfeature(dataset, labels)
bestfeature = labels[bestfeatureidx]
label = labels[bestfeatureidx]
tree = {label:{}}
del(labels[bestfeatureidx])
bestfeaturevalues = set(data[bestfeatureidx] for data in dataset)
for value in bestfeaturevalues:
splitdata = splitdata_disper(dataset, bestfeatureidx, value)
splitlabels = labels[:]
if splitdata == []:
continue
tree[label][value] = createtree(splitdata, splitlabels)
return tree
df = pd.read_table('nba.txt', sep = '\t')
#数据源,第一行是标题略过,第一列是球员名字略过
dataset = df.values[0:,1:].tolist()
labels = ['score', 'allscore', 'hitratio', 'threeratio', 'penaltyratio', 'time', 'count ', 'clublevel']
tree = createtree(dataset, labels)
createPlot(tree)训练样本数据,以NBA球员当前的各方面数据(同时包括连续型和离散型特征),以及自设定的其球员档次等级:
name score allscore hitratio threeratio penaltyratio time count clublevel tag
安东尼-戴维斯 31.6 537 51.9 28.2 81.3 37.2 17 Middle 1.5
拉塞尔-威斯布鲁克 31.2 561 43.5 33.7 81.3 35.4 18 Middleupper 1.5
德玛尔-德罗赞 30.2 483 48.8 25.8 80.9 36.8 16 Middle 2
詹姆斯-哈登 28.9 491 45.9 36.3 83.4 37 17 Middleupper 1.5
德马库斯-考辛斯 28.3 481 47.2 40.8 76.9 33.7 17 Middle 1.5
达米安-利拉德 28.2 536 46.3 36.6 89.6 35.7 19 Middle 2
凯文-杜兰特 27.2 462 57.4 44.6 83.8 34.4 17 upper 1
斯蒂芬-库里 26.7 454 50.2 42.5 92.9 33.3 17 upper 1
伊赛亚-托马斯 26.1 417 43.2 33.6 87.6 33.1 16 lower 2.5
吉米-巴特勒 25.8 413 49 42.6 88.7 35.2 16 Middleupper 1.5
考瓦伊-莱昂纳德 24.8 421 46.2 38.6 92.5 34.2 17 upper 1.5
凯里-欧文 24.8 372 49 43.3 84 33.9 15 upper 2
肯巴-沃克 24.5 392 46.9 41.1 79.6 33.4 16 Middle 2.5
勒布朗-詹姆斯 23.6 331 49.8 36.1 74.2 36.1 14 upper 1
安德鲁-维金斯 23.5 376 43 39.1 76.7 36.4 16 Middle 2.5
约翰-沃尔 23.5 305 45.4 38.1 81.6 34.2 13 Middle 2
卡梅罗-安东尼 23 368 45.4 34.7 86.8 33.8 16 Middle 1.5
凯文-勒夫 22.3 335 45.4 43 86.5 31.7 15 upper 1.5
C.J.-迈克科伦姆 22.3 424 47.3 44.5 91 34.6 19 Middle 2.5
吉安尼斯-安特托孔波 22 330 51.4 18.8 78.7 34.7 15 Middle 2
卡尔-安东尼-唐斯 21.1 338 49.1 39.4 71 34.7 16 Middle 2
布雷克-格里芬 21.1 380 48.7 22.2 77.4 33.1 18 upper 1.5
乔治-希尔 20.9 188 55.2 47.1 86.7 32.7 9 Middle 2
克里斯塔普斯-波尔津吉斯 20.9 335 49 40 78.6 33.3 16 Middle 2.5
哈里森-巴恩斯 20.8 332 46 28.6 87.1 37.3 16 Middle 2.5
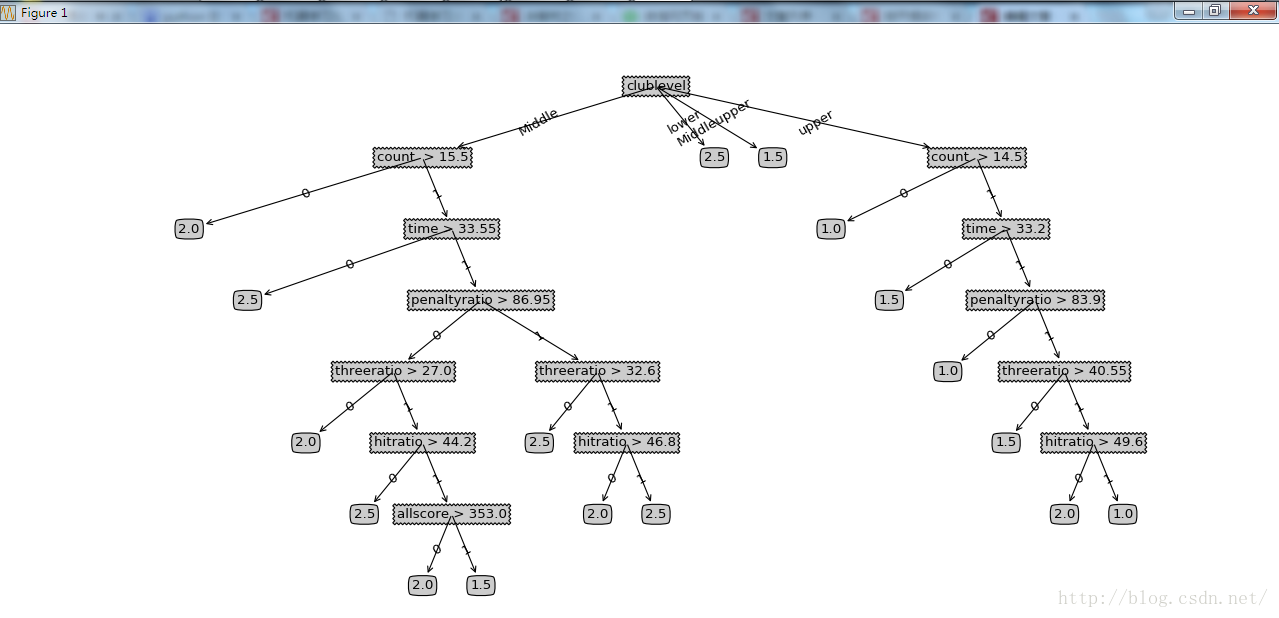
保罗-乔治 20.8 249 43.9 37.2 93 34.9 12 Middleupper 1.5运行结果如下:可以发现分叉还是比较多。















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









