







K-Means算法。
原理上来讲,K-Means算法其实是假设我们数据的分布是K个sigma相同的高斯分布的,每个分布里有N1,N2……Nk个样本,其均值分别是Mu1,Mu2……Muk,那么这样的话每个样本属于自己对应那个簇的似然概率就是
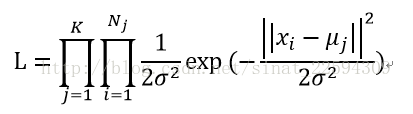
这个套路我们就很熟悉了,下面就是取对数似然概率,要求似然概率的最大值,给它加个负号就可以作为损失函数了,考虑到所有簇的sigma是相等的,所以我们就可到了K-Means的损失函数

接着我们对损失函数求导数为0,就可以得到更新后最佳的簇中心了
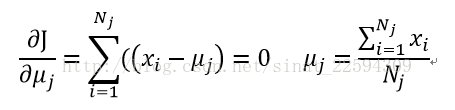
这样我们就得到了所谓的K-Means算法
1 初始选择K个类别中心。
2 将每个样本标记为距离类别中心最近的那个类别。
3 将每个类别中心更新为隶属该类别所有点的中心。
4 重复2,3两步若干次直至终止条件(迭代步数,簇中心变化率,MSE等等)
现在我们回过头来看看K-Means算法的问题。
首先,正如我刚开始介绍它的时候,它是假设数据服从sigma相同的混合高斯分布的,所以最后分类的结果肯定是若干个类圆形的区域,这就很大程度上限制了它的应用范围,如果我们的数据是那种比较奇葩的形状,比如什么扇形啊,圆环啊,你会发现K-Means的效果其实不是很叫人满意。
其次,你得给出这个分类的数目K啊,有一定的先验条件还好,如果是两眼一抹黑,怎么确定呢?猜呗,或者试呗,用一定的评价标准选择最佳那个就成。还有就是初始簇中心的选择,K-Means的结果对初值是敏感的,比如说样本分为三个簇,你一开始把两个中心定在某一个簇中,还有一个中心处在另外两个簇的中间,这样最后的结果很可能是那两个簇被划分成一类,还有一个簇被强行划分成两个簇这样。所以为了解决这个初值敏感问题,又提出了K-Means++算法,它的做法就是你先随机指定第一个簇中心,然后计算所有点到该簇中心的距离,以这个距离作为权值来选择下一个簇中心,一定程度上可以解决簇中心初值选择不合理的问题。
最后还有一个问题,就类似于上一篇我们讲的SVM一样,如果我们采用线性可分SVM方法,一个异常点就可以把我们的分割超平面带跑偏导致泛化能力被削弱。K-Means中我们采用均值来更新簇中心,同样的,一个异常点会导致新的这个簇中心发生比较大的偏离,而且再更新的时候我们还是要考虑那个异常点,所以就不会得到比较好的效果。
说了这么多K-Means的缺点都显得它一无是处了,我们还是要说K-Means作为一种最经典的聚类算法,它简单,快速,在应对大数据的时候相对优势会比较大,有的时候还可以作为其他聚类算法中的一步。
====================================================================
DBSCAN算法。
前面讲了K-Means算法主要针对那
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 6504
6504











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









