







最近在做一些题的时候更加理解到为什么有一句话叫做程序=算法+数据结构,可能之前的一些题我用最基本的数据类型加上一些“意想不到”的算法就可以解决,但是往往一些问题,佐以精妙的数据结构能让人事半功倍。
Trie树就是这样的一种数据结构,先来一段来自百度的定义性描述,它又称单词查找树,字典树,是一种树形结构,是一种哈希树的变种。典型应用是用于统计,排序和保存大量的字符串(但不仅限于字符串),所以经常被搜索引擎系统用于文本词频统计。它的优点是:利用字符串的公共前缀来减少查询时间,最大限度地减少无谓的字符串比较,查询效率比哈希树高。Trie树再解决mou一类问题时真的是简单又好用。关于它的简单操作也不过是初始化,插入,查询,删除,下面依次给出一种简单的实现,在实际遇到的问题中可能需要增加某种字段或者进行别的怎样的扩展,这都是依题目而变的。
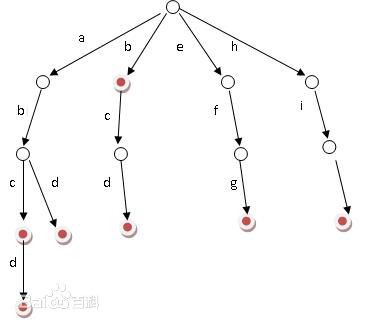
我们假设在这里我们面向的是由26个小写字母组成的字符串。
//因为我们考虑的是由26个小写字母组成的字符串
//具体问题还可以再变化,而这种变化往往是最难的
#define MAX 26
using namespace std;
//定义Trie树的节点
typedef struct Trie_Node{
struct Trie_Node *next[MAX];
}Trie;
Trie *r;//创造的Trie树的根节点的指针
void init(){//以r为根进行初始化
r = (Trie *)malloc(sizeof(Trie));
for(int i = 0;i < MAX;i++){
r->next[i] = NULL;
}
}
void insert(Trie *root,char *word){
Trie *p = root;
while(*word != '\0'){
if(p->next[*word - 'a'] == NULL){
Trie *temp = (Trie *)malloc(sizeof(Trie));
for(int i = 0;i < MAX;i++){
temp->next[i] = NULL;
}
p->next[*word - 'a'] = temp;
}
p = p->next[*word - 'a'];
word++;
}
}
bool search(Trie *root,char *word){
Trie *p = root;
for(int i = 0;word[i]!='\0';i++){
if(p == NULL||p->next[word[i]-'a'] == NULL){
return false;
}
p = p->next[word[i]-'a'];
}
return true;
}
void del(Trie *root){//因为我们用到动态内存分配,不用了就还回去
for(int i = 0;i < MAX;i++){
if(root->next[i] != NULL){
del(root->next[i]);
}
}
free(root);
}

















 2522
2522

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









