







作者:YouChuang
本文主要是对剑指offer及平时遇到的链表相关的题目做了部分总结
删除链表结点
O(1)时间内删除链表指定结点
给定指定链表的头结点和目标结点,在O(1)的时间内删除掉该目标结点
思路
一般思路:
从头结点遍历链表,找到指定结点然后删除,但是这样会带来O(n)的时间开销,不满足题意。存在的问题是查找都是从头结点开始,时间过长。
优化思路:
抽象认识问题,删除结点其实本质上就是删除该结点中存放的数据,另外删除结点的本质方法就是找到该结点的前一个结点然后实施删除。
基于这两种认识,提出将当前结点的下一个结点作为目标结点,将两者的数据交换,就可以得到前一个结点(即之前的目标结点)边界条件
针对目标结点为尾结点的情况,我们无法找到下一个结点来删除,所以就采用传统的方法来进行删除,总体的时间复杂度为((n-1) * 1 + n * 1) / n,还是O(1)的复杂度
删除重复结点
在一个排序的链表中,存在重复的结点,请删除该链表中重复的结点,重复的结点不保留,返回链表头指针。 例如,链表1->2->3->3->4->4->5 处理后为 1->2->5
- 思路
特别注意,不是只删除掉重复的结点,而是只要该结点出现重复,则所有相关结点都删掉(包括源结点) - 边界条件
链表为空或只有一个结点
所有结点都为重复(重复同一个数据或者多种重复数据)
包括头结点在内的前几个结点发生重复
/*
public class ListNode {
int val;
ListNode next = null;
ListNode(int val) {
this.val = val;
}
}
*/
public class Solution {
ListNode deleteDuplication(ListNode pHead)
{
/*
work、pre双指针
*/
if(pHead == null)
return pHead;
//用来标记是否出现重复结点
int tag = 0;
ListNode ppre, pwork, pnext;
ppre = null;
pwork = pHead;
pnext = pwork.next;
while(pnext != null)
{
if(pwork.val == pnext.val)
{
tag = 1;
pwork.next = pnext.next;
pnext.next = null;
pnext = pwork.next;
}
else
{
if(tag == 1)
{
//说明之前出现了重复结点,如果是在头结点就出现这种情况需要小心处理
if(pwork == pHead)
{
pwork = pnext;
pnext = pnext.next;
pHead = pwork;
}
else
{
ppre.next = pnext;
pwork = pnext;
pnext = pnext.next;
}
tag = 0;
}
else
{
ppre = pwork;
pwork = pnext;
pnext = pnext.next;
}
}
}
//如果最后部分全部重复,整个链表都是重复数据,则全部删除处理
if(tag == 1)
{
if(pHead == pwork)
{
pHead = pnext;
}
else
{
ppre.next = pnext;
pwork.next = null;
}
}
return pHead;
}
}查找特定节点
倒数第k个结点
输入一个链表,输出该链表中倒数第k个结点。
- 思路
常规思路,两个工作指针,一前一后出发 - 边界条件
计数k与结点为null两个条件的控制
/*
public class ListNode {
int val;
ListNode next = null;
ListNode(int val) {
this.val = val;
}
}
*/
public class Solution {
public ListNode FindKthToTail(ListNode head,int k) {
if((head == null) || (k == 0))
return null;
/* 前者先走的步数 */
int num = k;
ListNode ppre;
ListNode pwork;
ppre = pwork = head;
/* pwork先走k步 */
while((num > 1) && (pwork != null)){
pwork = pwork.next;
num--;
}
/* k若超过了链表的范围 */
if(pwork == null){
return null;
}
/* 同时后移 */
while(pwork.next != null){
pwork = pwork.next;
ppre = ppre.next;
}
return ppre;
}
}查找中间结点
思路:跟上面的类似,只不过两个工作指针同时出发,步幅不同
环与相交
判断是否存在环
思路:
若是链表存在环的话,则两个速度不同的工作指针,肯定会在环中相遇。
设定两个工作指针,同时出发,步幅不同,两者相遇则证明有环,否则会遍历结束
具体的实现在下面问题中有代码
查找环的入口
一个链表中包含环,请找出该链表的环的入口结点。
- 思路
经典问题,相关问题还有几个,稍后补上,再总结一下
需要数学推导,简单说下过程:
假设非环链表长度为K(长度即为结点个数,非环链表不包含环的入口结点),环的长度为L,两个工作指针ppre、pnext,ppre的速度为spre,pnext的速度为snext;
假设两个指针同时从头结点(不计入长度之内)出发,向前走了x次,即ppre走了spre*x步,pnext走了spnext*x步,则两者在环中相交时(这里有两个问题,判断链表是否有环以及默认两个结点是在环中的第一圈即相遇,稍后解决)
(ppre*x - K) % L = (pnext*x - K) % L
((pnext - ppre) * X) % L = 0
假设pnext的速度为2,ppre为1
则X % L = 0,即X = L
则两者相交的地方在X-K=L-K的地方,即环中距离环入口处L-K个位置的地方
这时可以看出相交处再次到达环入口的距离为K,与链表头结点到环入口的距离相同
稍后补上图片来做说明,可能会更好理解一下
则本题目的思路也就出来了
先让两个指针ppre、pnext分别以1、2的速度同时遍历链表,知道两者相遇
然后ppre指针重回头结点,pnext不变,接着ppre和pnext同时以速度1继续遍历,直到再次相遇,则相遇的地方即为环的入口结点
以下图为例
K为3,L为7,则X=L=7,即ppre指针向前走了7步,pnext向前走了14步,两者第一次相聚在X-K=4,距离入口4步的位置,然后再继续前行3步即可再次达到环的入口处
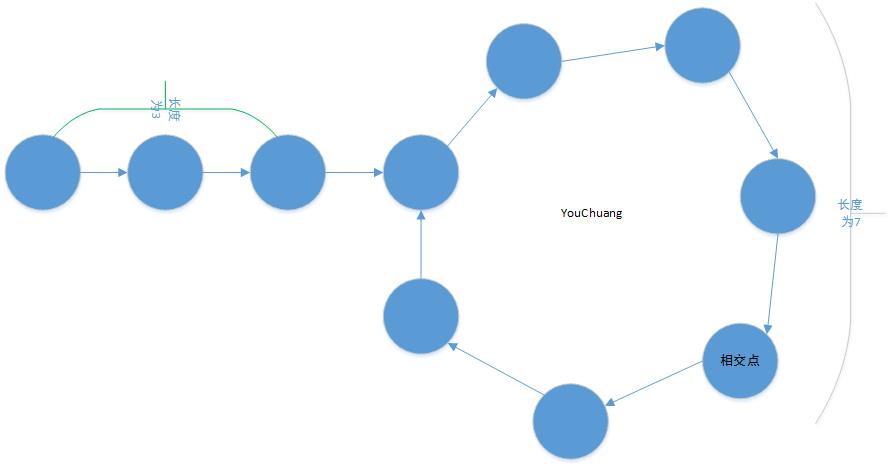
- 边界条件
链表本身即为环
/*
public class ListNode {
int val;
ListNode next = null;
ListNode(int val) {
this.val = val;
}
}
*/
public class Solution {
ListNode EntryNodeOfLoop(ListNode pHead)
{
if(pHead == null || pHead.next == null)
return null;
ListNode pwork = pHead;
ListNode pa, pb;
pa = pb = pHead;
/** 找到两个结点在环中相遇的结点 */
while(pa != null && pa.next != null)
{
pa = pa.next;
pb = pb.next.next;
if(pa == pb)
{
//若是相遇,则跳出循环继续处理
break;
}
}
//若两者在环的入口处相遇,则链表本身为环
if(pa == pHead)
return pa;
if(pa != null)
{
pa = pHead;
while(pa != null && pa.next != null)
{
pa = pa.next;
pb = pb.next;
if(pa == pb)
{
//若是相遇,则跳出循环继续处理
return pa;
}
}
}
return pa;
}
}两个链表是否相交
两个单链表,判断是否相交
- 思路
首先明确一点,若是两个链表相交,则两个链表的尾结点必定相同,头结点不同
最基本思路,对链表1中的每一个结点遍历链表2
优化思路一,转化成环的问题,将链表2的头部接在链表1后面,若是两个链表相交,则链表2变成环,直接判断链表2是否为满环即可(遍历一遍是否回到起点)
优化思路二,因为两个相交链表的尾结点必定相同,则直接分别找到两个链表的尾结点,然后比较即可
如果链表中可能有环,判断是否相交
- 思路
若是有环的链表相交,由于相交链表尾结点必定相同,则两个链表的环必定重合
那么就可以直接判断链表一中环的入口结点是否在另一个链表上出现即可。
相交的第一个结点
两个单链表
- 思路
基于优化思路一,则找到新的带环链表的环入口结点即为相交的第一个结点
基于优化思路二,则需先确定两个链表长度,然后基于短链表,遍历长链表结点到相同的位置,然后两个链表同时遍历并比较结点是否相同,直至末尾,代码见下方
/*
public class ListNode {
int val;
ListNode next = null;
ListNode(int val) {
this.val = val;
}
}
*/
public class Solution {
public ListNode FindFirstCommonNode(ListNode pHead1, ListNode pHead2) {
/**
* 边界条件处理,其中一个链表为空或者只有一个结点则不成立,两个链表头部不能重合,不然就完全重合
* 链表1的末尾指针、工作指针,链表2的末尾、工作指针
*/
ListNode pwork1, pwork2, pwork;
pwork1 = pHead1;
pwork2 = pHead2;
int len1 = 0, len2 = 0, tmp = 0;
/** 获取链表长度,比较,然后遍历对齐 */
while(pwork1 != null){
len1++;
pwork1 = pwork1.next;
}
while(pwork2 != null){
len2++;
pwork2 = pwork2.next;
}
pwork1 = pHead1;
pwork2 = pHead2;
tmp = len1 - len2;
if(tmp > 0){
while(tmp > 0){
pwork1 = pwork1.next;
tmp--;
}
}else if(tmp < 0){
while(tmp < 0){
pwork2 = pwork2.next;
tmp++;
}
}
/** 开始遍历并判断 */
while((pwork1 != pwork2) && (pwork1 != null)){
pwork1 = pwork1.next;
pwork2 = pwork2.next;
}
return pwork1;
}
}改变链表顺序
反转链表
输入一个链表,反转链表后,输出反转链表后头节点
- 思路
非递归思路:比较简单的思路,三个工作指针
递归思路:注意如何结束递归 - 边界条件
注意不要让null指针再取next
非递归方式
/*public class ListNode {
int val;
ListNode next = null;
ListNode(int val) {
this.val = val;
}
}*/
public class Solution {
public ListNode ReverseList(ListNode head) {
if((head == null) || (head.next == null))
return head;
ListNode ppre = null;
ListNode pwork = null;
ListNode pnext = null;
pwork = head;
//pnext = head.next;
while(pwork != null){
/*
如果按照下面这样编码的话,则会出现一种情况就是pwork不为null,pnext已经为null,然后最后一句再对pnext取next则会出错。
pnext = head.next;
while(pwork != null){
pwork.next = ppre;
ppre = pwork;
pwork = pnext;
pnext = pnext.next;
}
*/
pnext = pwork.next;
pwork.next = ppre;
ppre = pwork;
pwork = pnext;
}
//head = ppre;
return ppre;
}
}递归方式
public class Solution {
public ListNode ReverseList(ListNode head) {
/** 递归结束条件 */
if((head == null) || (head.next == null))
return head;
/** 逆置两个结点 */
ListNode pNewHead = ReverseList(head.next);
head.next.next = head;
head.next = null;
return pNewHead;
}
}其它操作
复制复杂链表
复制复杂链表,链表有next指针和random指针,random指向任意结点
思路
普通思路:
先复制next指针的链表,再逐个结点遍历random指针,并对找到的对应结点重新遍历链表记录其所在位置,最后更改新链表对应结点的random指针。存在的问题,random结点的定位比较难
巧妙思路:
将新链表和旧链表的结点之间建立一个映射关系,当遍历random时,将原结点和对应的random结点分别映射到新链表的对应结点中即可。存在的问题,需要专门的存储空间来存放映射关系
更为巧妙的思路:
将映射关系与直接用链表的next指针来存储,一个指针多用,旧链表的结点与新链表的结点的映射关系就是next关系。建立完毕后,建立相应的random指针关系,最后再拆分为新旧链表。边界条件
/*
public class RandomListNode {
int label;
RandomListNode next = null;
RandomListNode random = null;
RandomListNode(int label) {
this.label = label;
}
}
*/
public class Solution {
public RandomListNode Clone(RandomListNode pHead)
{
/** 边界条件判断 */
if(pHead == null){
return null;
}
RandomListNode pHeadWork = null;
pHeadWork = pHead;
/**
* 先原地复制next指针链表,建立新旧链表的同时建立映射关系
*/
while(pHeadWork != null){
RandomListNode pNewNode = new RandomListNode(pHeadWork.label);
//pNewNode.label = pHeadWork.label;
pNewNode.random = null;
pNewNode.next = pHeadWork.next;
pHeadWork.next = pNewNode;
pHeadWork = pNewNode.next;
}
/**
* 基于映射关系,建立random链表关系
*/
pHeadWork = pHead;
while(pHeadWork != null){
if(pHeadWork.random != null){
pHeadWork.next.random = pHeadWork.random.next;
}
pHeadWork = pHeadWork.next.next;
}
/**
* 解开链表成两个链表
*/
RandomListNode pNewHead = null, pNewHeadWork = null;
pNewHead = pHead.next;
pNewHeadWork = pNewHead;
pHeadWork = pHead;
pHeadWork.next = pHeadWork.next.next;
pHeadWork = pHeadWork.next;
while(pHeadWork != null){
pNewHeadWork.next = pHeadWork.next;
pNewHeadWork = pNewHeadWork.next;
pHeadWork.next = pHeadWork.next.next;
pHeadWork = pHeadWork.next;
}
return pNewHead;
}
}参考
http://wuchong.me/blog/2014/03/25/interview-link-questions/
http://blog.csdn.net/heyabo/article/details/7610732
http://blog.csdn.net/liuhuiyi/article/details/8742571














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









