







音频识别,获取文字
本菜鸟这学期有个自主学习英语课,课上有个听力部分。考试主要是其中的Task 3 部分。老师让我们重点听那部分。可是给的音频是以Unit 为单元的。Unit分为3个Part, 每个Part 又分为 3个Task。非常坑爹。自己找Task 3部分的位置很麻烦,所以想用语音识别定位”Task three”的位置。可惜本菜鸟不懂语音识别,就找了个网上现成的工具:popuparchive (可能需要fangqiang)。把音频传上去,它会在后台处理音频。生成对应的“歌词”。之后我们就可以定位了。不过有几个问题:
1. 对免费用户一个月的处理量有限制。
2. 处理的结果不是很完美,主要是断句不是很对。
步骤如下:
首先注册,这步不用多说。
登录进去后,点击my collections:(如下图)
给my collections 上传音频。
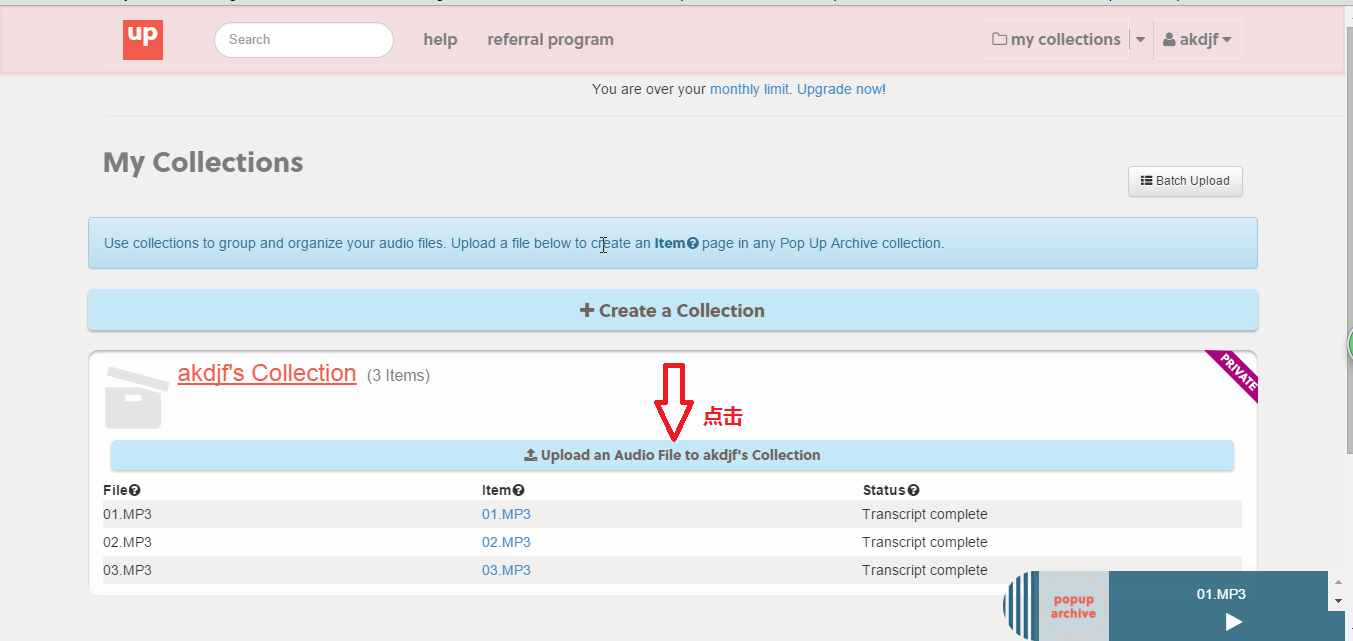
点击”Upload one file at a time” 选择本地的音频文件。
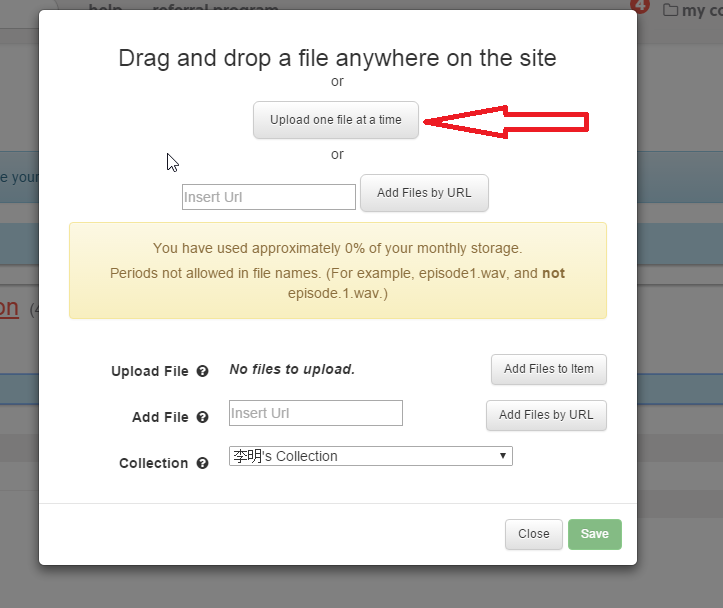
上传完成
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2769
2769

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









