







使用lxml对爬取的网页数据进行解析时,最长使用的方式是xpath,在Scrapy爬虫框架中也提供了相应的函数调用.xpath()和.css(), css()的方式实质上底层仍然被转换成xpath方式进行处理。
1.XPath基础语法
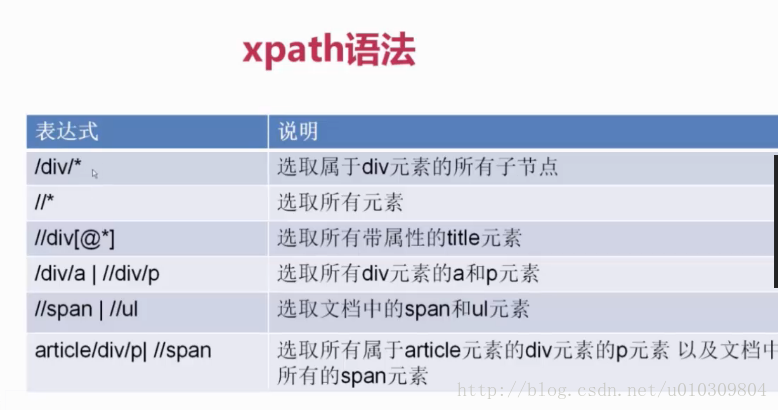
首先是xpath的基本使用方法,如图:


2. XPath with Python
from lxml import etree
html_doc = """<html>
<div>
<a>这是一个链接</a>
</div>
<div>
<ul>
<li id="test1">测试1</li>
<li id="test2">测试2</li>
<li id="testdefault">测试3</li>
</ul>
</div>
<div id="desc">
美女,<span>约吗?</span>
</div>
<span>兄弟,你好吗</span>
</html>"""
selector = etree(html_doc)
# xpath返回的结果通常是列表形式,通过xpath字符串内索引或者外部索引来取某个单独的结果
# 字符串内部索引从1开始,外部索引是python列表索引,从0开始.
selector.xpath('//div[@id="desc"][1]')
selector.xpath('//div[@id="desc"]')[0]
# 通常xpath()返回的是Selector对象,通过调用extract()来提取具体字符串内容
selector.xpath('//div[@id="desc"]')[0].extract()
selector.xpath('//div[@id="desc"][1]').extract()
# text() 提取元素字符串,返回Selector对象
# string(.)提取字符串(包括子元素中的),返回Selector对象
selector.xpath('//div[@id="desc"]')[0].extract() # 美女,
selector.xpath('//div[@id="desc"]/string(.)')[0].extract()#美女,约吗?
# contains(a, b) a中包含b
# starts-with(a, b) a以b开头
selector.xpath('//div[contains(@class, "header")]')[0].extract()
selector.xpath('//div[starts-with(@id, "header")]')[0].extract()
# 获取元素的兄弟节点.获取所有相邻span,获取第一个相邻span的文字内容
selector.xpath('//div[contains(@id, "desc")]/following-sibling::span')
selector.xpath('//div[contains(@id, "desc")]/following-sibling::span[1]/text()')[0].extract()
# 取属性. 取id属性值
selector.xpath('//div[@id="desc"]'/@id)















 362
362

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









