







1.安装scrpy
关于名字,Scrapy = S + crawl +py ???.
基于Python3.x的scrapy使用,首先配置virtualenv配置python虚拟环境,详见.
在虚拟环境中安装scrapy,使用国内豆瓣源安装:
pip install -i https://pypi.douban.com/simple scrapy
如果安装或编译出错,则使用这里已经编译好的包进行安装,同样使用pip命令安装本地文件。
安装完成之后,使用scrapy startproject jobbole命令创建jobbole项目,目录结构中spiders包下存放的是初始化生成的爬虫模板文件。
2. Scrapy框架的组成
首先上一张图
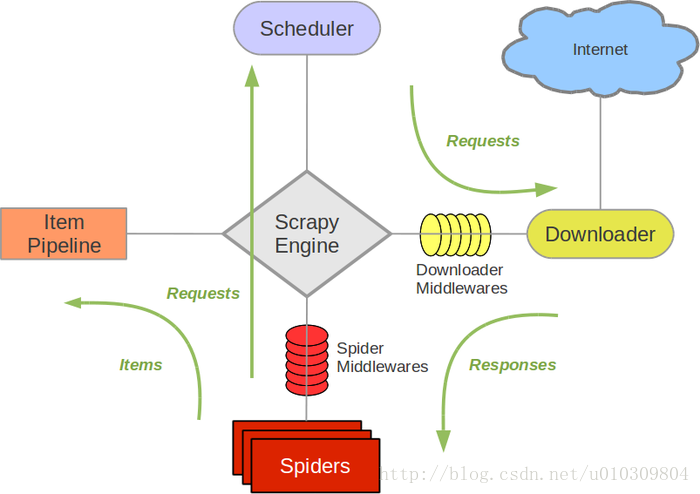
简单的来说,Scrapy由以下几部分组成:
(1)任务调度器Scheduler,调度多个异步请求任务。
(2)下载器downloader,提供专用的图片、文件下载器。
(3)数据后处理其ItemPipline.
scrapy标准的爬虫文件中有一个scrapy.Spider子类,与爬虫相关的类和方法包括Request,Response,parse,Item,ItemLoader,settings,pipeline。一个完整的爬虫流程如下:

- 从start_urls开始,通过Request发请求。标准的Request如下:
from url import parse
final_url = parse.urljoin(response.url, url)
// 发送新的请求
yield Request(url=final, callback=self.parse_detail, meta={})url可以通过parse可以处理那些无域名的相对路径
callback制定另一个类成员函数进行处理
meta可以将任意数据通过dict的形式传入response中,向下传递
通过yield Request可发送新的请求
自定义解析函数时,函数的参数签名为(self, response)
可以通过response.xpath() 、response.css()和response.re()手动获取页面内容。推荐的做法是使用scrapy提供的ItemLoader,ItemLoader会自动解析提取的值,而不用手动extrac()[0]。
与ItemLoader配合的是Item,Item定义时可以设置input_processor和output_processor。Item的定义只是通过Filed()进行声明即可。
// 预置processor的种类
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1265
1265

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









