







在写完上一篇文章之后,在使用过程中慢慢发现一些问题,比如说数据入库很慢,10W的数据分10个文件入库大概需要两三分钟,如下图
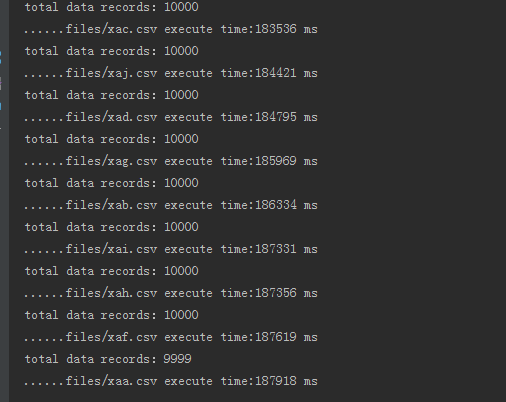
这是我忍受不了的,所以我寻思着如何优化该程序,提高入库性能。因此我对JDBC数据入库的几种方法做了一个对比,在大量的实验下,发现了如下的规律:
1、使用statement耗时最长;
2、使用PreparedStatement耗时明显缩短;
3、使用PreparedStatement + 批处理耗时暂时耗时最少。
针对我的小程序,入库的表所需要的字段有上百个,我懒得去拼字符串,于是就选择Statement+批处理来处理,关键代码如下:
if(conn == null) {
conn = dbutil.getConnection();
}
pre = conn.createStatement();
conn.setAutoCommit(false);
while (line_record != null) {
if(line_record.indexOf("cdri 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 743
743











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









