







requests库 response 字符编码的问题
现象描述
有时候从网上下载或者爬取网页的时候,有时候拿到网页是乱码 。
模拟来启动一个server 服务端,编写app.py文件如下
# -*- coding: utf-8 -*-
from flask import Flask
from flask import make_response
app = Flask(__name__)
@app.route('/')
@app.route('/index/')
def index():
response = make_response("<lnci:content>28 U.S.C.A. § ≥ © & </lnci:content>")
response.headers['content-type'] = 'application/xml;charset=Windows-1252'
return response
if __name__ == '__main__':
app.run()
注意 使用 make_response 创建 response , 默认 使用utf-8 编码,和设置headers 没有关系。 headers 只是告诉 客户端 我的文档使用什么编码方式。 如果指定了错误的方式,就有可能出现解码出现错误,或者乱码的问题。
client.py
import requests
url = 'http://127.0.0.1:5000/index'
if __name__ == '__main__':
r = requests.get(url=url)
print(r.encoding)
print(r.text)
结果如下:
Windows-1252
<lnci:content>28 U.S.C.A. § ≥ © & </lnci:content>
发现有乱码 ,这些h5 的特殊字符变成了一些不认识的符号。
r.contenet 与 r.text 区别
在requests库中返回 response 有两种分别是 r.text , r.content
r = requests.get(url=url)
r.text
r.content
它们的主要区别
r.text 返回 符串类型
r.content 返回的 bytes 类型, Binary Response Content
str 与 bytes 互转基础知识
补充 编码知识
我们知道 在python3 中 str 与 bytes 互转 分别是 encode ,decode 方法操作
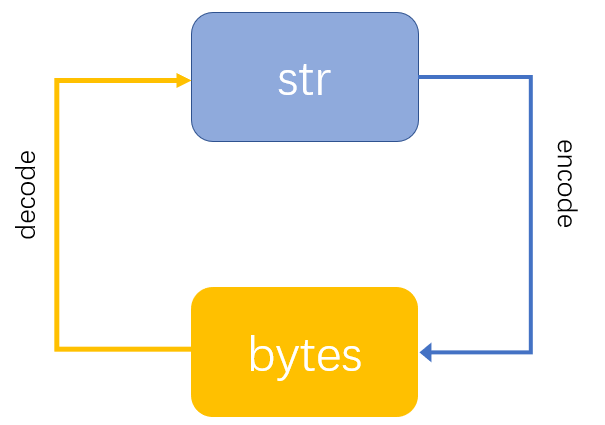
字符串类型 encode 变成一个 bytes 类型 , 然后 bytes 类型通过decode 方式 来转成 str 类型。注意这里 encode 与decode 编码要一样才能进行正常解码。
比如用 str.encode('utf-16') , 然后用 b.decode('utf-8') 就会出现错误,或者出现乱码问题。
>>> b = 'frank'.encode('utf-16')
>>> b
b'\xff\xfef\x00r\x00a\x00n\x00k\x00'
>>> b.decode('utf-8')
Traceback (most recent call last):
File "<input>", line 1, in <module>
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xff in position 0: invalid start byte
>>> b.decode('utf-16')
'frank'
在 requests库中 r.text 返回类型 为字符串类型, 那么它用什么方式解码呢?
查看代码 发现 是通过 chardet 这个库来自动识别 ,这个编码方案 。 然后通过 str 构造方法 ,返回一个str 类型
@property
def apparent_encoding(self):
"""The apparent encoding, provided by the chardet library."""
return chardet.detect(self.content)['encoding']
text 核心源码
content = str(self.content, encoding, errors='replace')
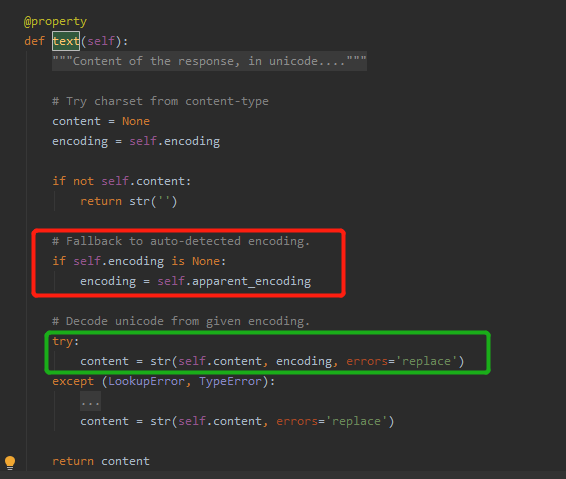
红色部分圈出来的代码,就是 推测 encoding 的编码方式。
请求发出后,Requests 会基于 HTTP 头部对响应的编码作出有根据的推测。当你访问 r.text 之时,Requests 会使用其推测的文本编码。你可以找出 Requests 使用了什么编码,并且能够使用 r.encoding 属性来改变它:
>>> r.encoding
'utf-8'
>>> r.encoding = 'ISO-8859-1'
所以 现在出现乱码的原因 可能是 encoding 不是我们想要的方式 ,我们可以直接修改 encoding 来 改变 解码方式。
解决方案
第一种方式 手动修改 r.encoding 属性
import requests
url = 'http://127.0.0.1:5000/'
if __name__ == '__main__':
r = requests.get(url=url)
print(f"auto detect encoding={r.encoding!r}")
# 修改解码方式
r.encoding = 'utf-8'
print(r.text)
修改以后结果如下:
auto detect encoding='Windows-1252'
<lnci:content>28 U.S.C.A. § ≥ © & </lnci:content>
发现 结果没有乱码了。
第二种方式直接使用 r.content 进行解码
我们还可以通过 r.content 获取二进制内容, 通过decode手动解码 。
import requests
url = 'http://127.0.0.1:5000/'
if __name__ == '__main__':
r = requests.get(url=url)
print(f"auto detect encoding={r.encoding!r}")
# 指定解码
print(r.content.decode('utf-8'))
这种方式也是可以正常获取 xml 文档的。
总结
在抓取网页中出现乱码的原因,主要是 因为 网页的编码方式,和我们请求网页的解码方式 不一样而引起的,不想出现乱码,就要找到 服务端传输bytes流的时候使用的编码方式,这样才不会出现乱码问题。
参考文档
字符编码笔记:ASCII,Unicode 和UTF-8 - 阮一峰的网络日志















 1280
1280











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









