







Hadoop:
1.HDFS:分布式文件系统,存储海量的数据;
2.MapReduce:并行处理框架,实现任务分解和调度
Hive是构建在hadoop HDFS上的一个数据仓库
数据仓库:是不可更新的,随着时间的推移,不产生变化的集合,主要是数据查询,用于决策的数据。
Hive允许熟悉MapReduce开发者的开发自定义的mapper和reducer来处理内建的mapper和reducer无法完成的复杂的分析工作.
是SQL解析引擎,他将SQL语句转移成M/R Job然后在hadoop执行。
Hive的表其实就是HDFS的目录;Hive数据其实就是HDFS的文件。

OLTP系统是面向事务,要么同时成功要么同时失败;
OLAP系统是只做查询用。
搭建数据仓库的基本模型是星型模型 和雪花模型
1.Hive的体系结构是什么?
2.Hive如何与hadoop HDFS进行相互操作
3.Hive数据与Hadoop中的文件之间的关系
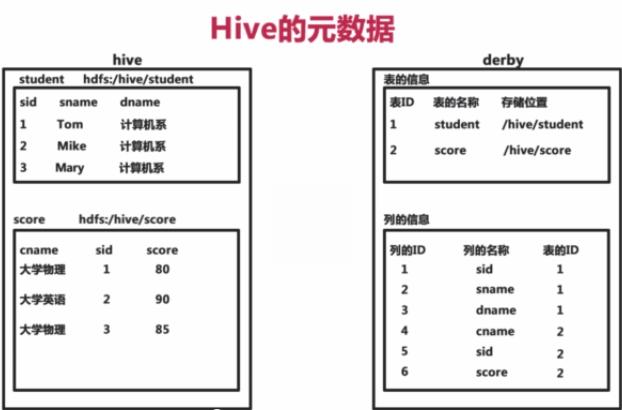
a.Hive将元数据存储在数据库中(metastore),支持mysql、derby等数据库。Hive默认产生derby数据库
b.Hive中的原数据包括表的名字,表的列和分区及其属性,标的属性(是否为外部表等),表的数据所在目录等。
HQL的执行过程:
a.解析器,编译器,优化器完成HQL查询语句从词法分析、语法分析、编译、优化以及查询计划(Plan)的生成、生成的查询计划存储在HDFS中,并在随后有MapReduce调用执行。
第一步:HQL select
第二步:解析器,语法分析
第三步:生成HQL的执行计划
第四步:优化器,生成最佳的执行计划。
第五步:执行
Hive的体系结构:Hadoop用HDFS进行存储,利用MapReduce进行计算。
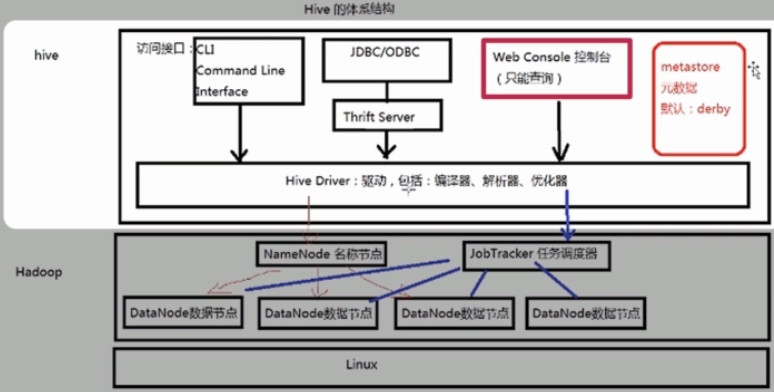
JobTracker任务调度器:我们在Hive中执行一条HQL语句,这条HQL语句实际上会被解析成MapReduce的作业并被提交到我们的Hadoop的集群上,进行运行,得到的结果最终会客户端的程序。这个工作就是由我们JobTracker所做的。
有了Hadoop集群后,可以在体制上构建我们的Hive的数据仓库。由于在Hive中需要操作我们在Hadoop集群中的HDFS中的文件系统的数据,所以在hive底层回事hive的驱动,有了hive的驱动,我们就能提供不同的访问接口,来进行操作。
Hive安装:单机环境、伪分布环境、集群环境
(1)嵌入模式
a、元数据信息被存储在Hive自带的Derby数据库中;
b、只允许创建一个连接
c、多用于Demo
(2)本地模式
a、元数据信息被存储在MySQL数据库中;
b、MySQL数据库与Hive运行在同一台物理机器上;
c、多用于开发和测试;
(3)远程模式
a、Hive的元信息被保存在MySQL的数据库中,而Hive与MySQL运行在不同的操作系统中;
b、用于生产环境,允许创建多个连接;















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









