










一,什么是Hive:
1.Hive是建立在Hadoop HDFS上的数据仓库基础架构;
2.Hive可以用来进行数据提取转化加载(ETL)
3.Hive定义了简单的类似SQL查询语言,称为HQL它允许熟悉SQL的用户查询数据
4.Hive允许熟悉MapRduce开发者的开发自定义的mapper和reducer来处理内建的mapper和reducer无法完成的复杂的分析工作;
5.Hive是SQL解析引擎,他将SQL语句转移成M/R Job然后在Hadoop执行;
6.Hive的表其实就是HDFS上的目录/文件;
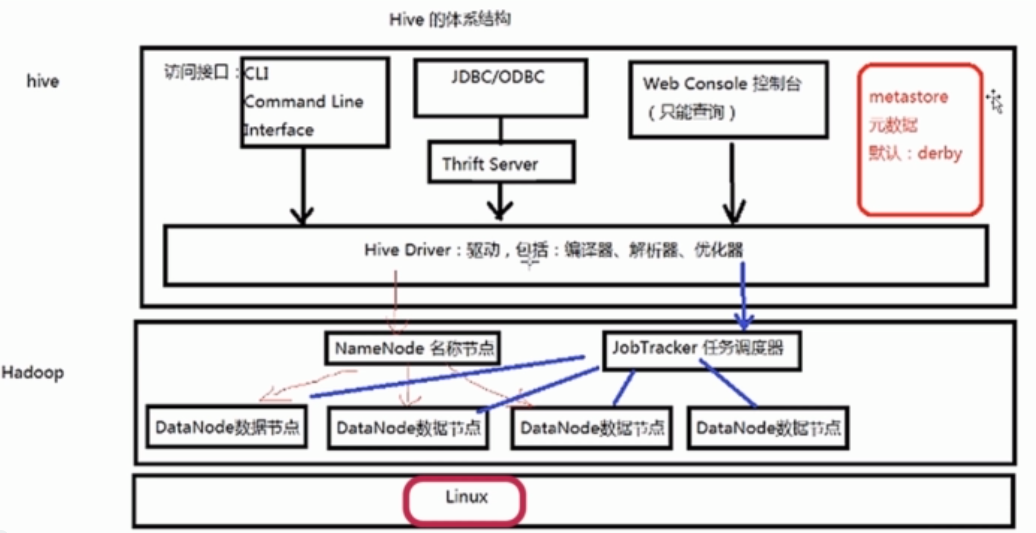
二,Hive的体系架构
1.Hive的元素据:
1).Hive将元素据存储在数据库中(metastore)支持mysql,derby等数据库。
2).Hive中的元数据包括表的名字,表的列和分区及其属性,表的属性(是否为外部表等),表的数据所在目录等
2.Hadoop:用HDFS进行存储,利用MapReduce进行计算
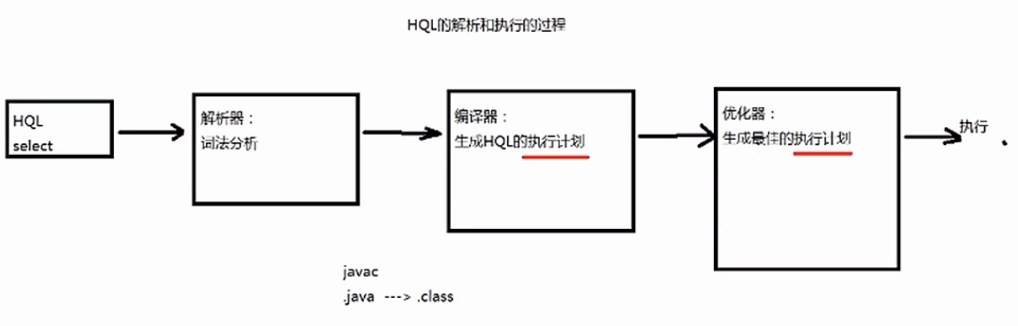
三,一条HQL语句如何在hive中进行查询?–HQL的执行过程:
解析器,编译器,优化器完成HQL查询语句从词法分析,语法分析,编译,优化以及查询计划(plan)的生成。生成的查询计划存储在HDFS中,并在随后有MapReduce调用执行。
四,hive的安装
1,hive的安装模式:嵌入模式,本地模式,远程模式。
1),嵌入模式:
a,元数据信息被存储在Hive自带的Derby数据库中;
b,只允许创建一个链接;
c,多用于Demo;
d,安装方法:解压后即可使用
2),本地模式:
a,元数据信息被存储在MySQL数据库中;
b,MySQL数据库与Hive运行在同一台物理机器上;
c,多用于开发和测试;
d,安装方法:
3),远程模式:Hive和MySQL数据库存放在不同的操作系统
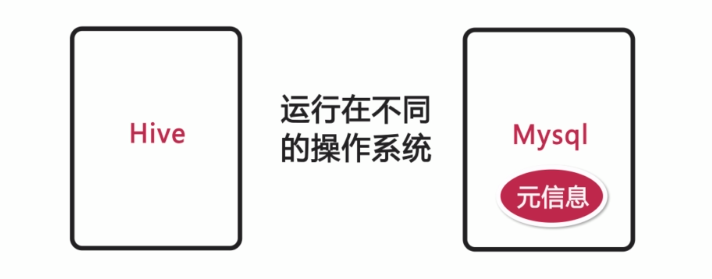
安装方法:参考本地模式,只需将hive-site.xml文件中的javax.jdo.option.ConnectionURL属性的localhost改为MySQL数据库所在服务器的ip地址即可。
<property>
<name>javax.jdo.option.ConnectionURL</name>
<-- 将localhost该为MySQL数据库所在服务器的ip地址 -->
<value>jdbc:mysql://localhost:3306/sfd?createDatabaseIfNotExist=true</value>
<description>JDBC connect string for a JDBC metastore</description>
</property>
五,Hive 的管理:
1,Hive的启动方式:
1,Hive的启动方式:
1),CLI(命令行)方式;
a,直接输入`# <HIVE_HOME>/bin/hive`的执行程序
b,输入`# hive --service cli`
c,常用的CLI命令:(在hive的命令行下进行交互)
清屏: Ctrl+L ! clear
查看数据仓库中的表: show tables;
查看数据仓库中内置的函数: show function;
查看表结构:desc [tablename]
查看HDFS上的文件:dfs -ls [目录]
dfs -lsr [目录] 查看目录下的所有文件和文件夹(包括子目录)。
执行操作系统的命令: ! [命令]
执行HQL语句:select * form talbename;
执行sql脚本:source [sql文件的路径]
进入hive的禁黙模式: hive -S(不出现调试信息值输出结果)
(在操作系统的CLI下进行交互):
执行一条语句:hive -S -e 'show tables;'
2),Web界面方式;
a,hive默认端口为 9999
b,开启hive 的 Web 界面:hvie --service hwi
有些版本可能会报如下错误:

只是因为这些版本(如hive0.13.0)自身没有hwi的web管理工具:这时我们需要通过源代码编译一下wab管理的工具;具体步骤:
首先,在hive官网下载hive的源代码,解压,进入源代码目录下的hwi文件夹`# cd hwi`,然后使用`jar cvfM0 hive-hwi-0.13.0.war -C web/`将web目录下的源文件打包为hive-hwi-0.13.0.war的war包并将这个war包移动到hive工作目录下的lib目录下;修改conf/hive-site.xml文件:
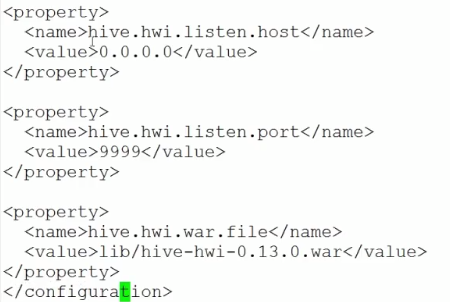
这样就可以重新启动hive --service -hwi 了
在界面通过网址`http://localhost:9999/hwi`(其中的localhost是mysql所在操作系统的ip)这是会报如下错误:

解决办法:我们要吧jdk目录下tool.jar包拷贝到hive目录下的lib文件夹中,现在就可以使用web管理端
3),远程服务启动方式:如果我们要以JDBC或ODBC的程序登陆到hive中操作数据时,必须选用远程服务启动方式
a,端口号10000
b,启动方式:`# hive --service hiveserver &`
六,Hive的数据类型:
1,基本数据类型:
1.tinyint/smallint/int/bigint:整数类型
类型的所占字节数:

2.float/double:浮点数类型
3.boolean:布尔类型
4.string:字符串类型
varchar(20)和 char(20)的区别:前者表示字符串的最大长度是20,也就是说保存的长度可以小于20;而后者表示的是字符串的长度是就是20,就算保存的字符串的长度小于20也会按照长度20来保存。
2,复杂数据类型
1.Array:数组类型,有一系列想用数据类型的元素组成
a.表的创建:

2.Map:集合类型,包含key->value键值对,可以通过key来访问元素。
a.表的创建:

(Array 和 Map 的结合建表:

)
3.Struct:结构类型,可以包含不同数据类型的元素。这些元素可以通过“点语法”的反噬来得到所需要的元素。
a.表的创建:

(Array 和 Struct的区别:Array中存放的必须是相同的数据类型,Stuct存放的可以是不同的数据类型)
3,时间数据类型
1.Data:从Hive0.12.0开始支持
a.表现形式年月日(YYYY-MM-DD)
2.Timestamp:从Hive0.8.0开始支持
a.与时区无关
b.是个有Unix以来的偏移量
c.查看timestamp:`select * from unix_timestamp();`















 537
537

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









