







java的Object类中有一方法hashcode返回int类型
public native int hashCode();
而且其实现是native方法。
hashCode方法的主要作用是为了配合基于散列的集合一起正常运行,这样的散列集合包括HashSet、HashMap以及HashTable。考虑一种情况,当向集合中插入对象时,如何判别在集合中是否已经存在该对象了?(注意:集合中不允许重复的元素存在)也许大多数人都会想到调用equals方法来逐个进行比较,这个方法确实可行。但是如果集合中已经存在一万条数据或者更多的数据,如果采用equals方法去逐一比较,效率必然是一个问题。此时hashCode方法的作用就体现出来了,当集合要添加新的对象时,先调用这个对象的hashCode方法,得到对应的hashcode值,实际上在HashMap的具体实现中会用一个table保存已经存进去的对象的hashcode值,如果table中没有该hashcode值,它就可以直接存进去,不用再进行任何比较了;如果存在该hashcode值, 就调用它的equals方法与新元素进行比较,相同的话就不存了,不相同就散列其它的地址,所以这里存在一个冲突解决的问题,这样一来实际调用equals方法的次数就大大降低了,说通俗一点:Java中的hashCode方法就是根据一定的规则将与对象相关的信息(比如对象的存储地址,对象的字段等)映射成一个数值,这个数值称作为散列值。即在散列集合包括HashSet、HashMap以及HashTable里,对每一个存储的桶元素都有一个唯一的"块编号",即它在集合里面的存储地址;当你调用contains方法的时候,它会根据hashcode找到块的存储地址从而定位到该桶元素。
设计hashCode()时最重要的因素就是:无论何时,对同一个对象调用hashCode()都应该产生同样的值。如果在讲一个对象用put()添加进HashMap时产生一个hashCdoe值,而用get()取出时却产生了另一个hashCode值,那么就无法获取该对象了。所以如果你的hashCode方法依赖于对象中易变的数据,用户就要当心了,因为此数据发生变化时,hashCode()方法就会生成一个不同的散列码。
这里突然想到一个问题,到底什么是散列???
把关键码值映射到数组中的位置来访问记录这个过程称为散列(hashing)
把关键码值映射到位置的函数称为散列函数(hashing function),通常用 h 表示。
存放记录的数组称为散列表(hash table),用 HT 表示。
散列表中的一个位置称为一个槽(slot)。
我们说hashmap是一个链表散列结构,底层是一个entry数组,那这样就好理解了。一个key-value进来是怎么散列的呢?
public V put(K key, V value) {
if (table == EMPTY_TABLE) {
inflateTable(threshold);
}
if (key == null)
return putForNullKey(value);
int hash = hash(key);
int i = indexFor(hash, table.length);
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}put中,先用通过hash方法,得到hash值,这个hash值的关键就是key的hashcode,通过下面的代码可以看到hash值并不是简单的hashcode,还要通过一些复杂的位运算。
final int hash(Object k) {
int h = hashSeed;
if (0 != h && k instanceof String) {
return sun.misc.Hashing.stringHash32((String) k);
}
h ^= k.hashCode();
// This function ensures that hashCodes that differ only by
// constant multiples at each bit position have a bounded
// number of collisions (approximately 8 at default load factor).
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}最后利用hash值和和数组的长度的运算得到新插入元素在数组中的位置
static int indexFor(int h, int length) {
// assert Integer.bitCount(length) == 1 : "length must be a non-zero power of 2";
return h & (length-1);
}重写 equals 时为什么一定要重写 hashCode?
重要说明:本篇为博主《面试题精选-基础篇》系列中的一篇,关注我,查看更多面试题。Gitee 面试题系列开源地址:gitee.com/mydb/interv…
equals 方法和 hashCode 方法是 Object 类中的两个基础方法,它们共同协作来判断两个对象是否相等。为什么要这样设计嘞?原因就出在“性能” 2 字上。
使用过 HashMap 我们就知道,通过 hash 计算之后,我们就可以直接定位出某个值存储的位置了,那么试想一下,如果你现在要查询某个值是否在集合中?如果不通过 hash 方式直接定位元素(的存储位置),那么就只能按照集合的前后顺序,一个一个的询问比对了,而这种依次比对的效率明显低于 hash 定位的方式。这就是 hash 以及 hashCode 存在的价值。
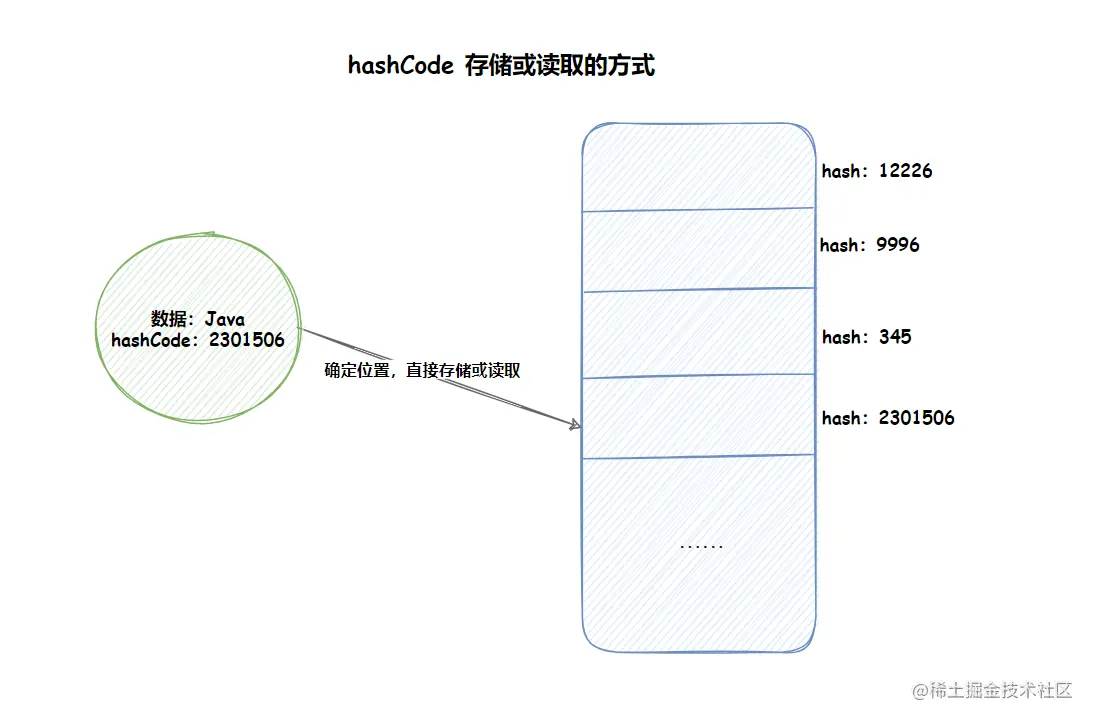
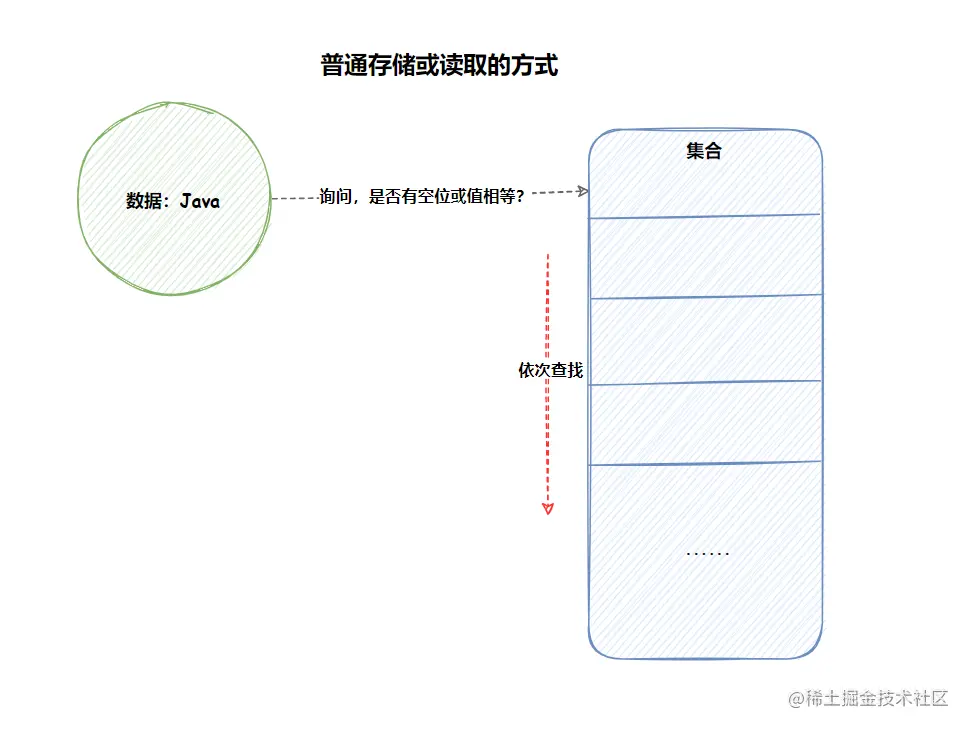
当我们对比两个对象是否相等时,我们就可以先使用 hashCode 进行比较,如果比较的结果是 true,那么就可以使用 equals 再次确认两个对象是否相等,如果比较的结果是 true,那么这两个对象就是相等的,否则其他情况就认为两个对象不相等。这样就大大的提升了对象比较的效率,这也是为什么 Java 设计使用 hashCode 和 equals 协同的方式,来确认两个对象是否相等的原因。
那为什么不直接使用 hashCode 就确定两个对象是否相等呢?
这是因为不同对象的 hashCode 可能相同;但 hashCode 不同的对象一定不相等,所以使用 hashCode 可以起到快速初次判断对象是否相等的作用。
但即使知道了以上基础知识,依然解决不了本篇的问题,也就是:重写 equals 时为什么一定要重写 hashCode?要想了解这个问题的根本原因,我们还得先从这两个方法开始说起。
1.equals 方法
Object 类中的 equals 方法用于检测一个对象是否等于另外一个对象。在 Object 类中,这个方法将判断两个对象是否具有相同的引用。如果两个对象具有相同的引用,它们一定是相等的。
equals 方法的实现源码如下:
public boolean equals(Object obj) {
return (this == obj);
}
复制代码通过上述源码和 equals 的定义我们可以看出,在大多数情况来说,equals 的判断是没有什么意义的!例如,使用 Object 中的 equals 比较两个自定义的对象是否相等,这就完全没有意义(因为无论对象是否相等,结果都是 false)。
通过以下示例,就可以说明这个问题:
public class EqualsMyClassExample {
public static void main(String[] args) {
Person u1 = new Person();
u1.setName("Java");
u1.setAge(18);
Person u2 = new Person();
u1.setName("Java");
u1.setAge(18);
// 打印 equals 结果
System.out.println("equals 结果:" + u1.equals(u2));
}
}
class Person {
private String name;
private int age;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
}
复制代码以上程序的执行结果,如下图所示:

因此通常情况下,我们要判断两个对象是否相等,一定要重写 equals 方法,这就是为什么要重写 equals 方法的原因。
2.hashCode 方法
hashCode 翻译为中文是散列码,它是由对象推导出的一个整型值,并且这个值为任意整数,包括正数或负数。
需要注意的是:散列码是没有规律的。如果 x 和 y 是两个不同的对象,x.hashCode() 与 y.hashCode() 基本上不会相同;但如果 a 和 b 相等,则 a.hashCode() 一定等于 b.hashCode()。
hashCode 在 Object 中的源码如下:
public native int hashCode();
复制代码从上述源码可以看到,Object 中的 hashCode 调用了一个(native)本地方法,返回了一个 int 类型的整数,当然,这个整数可能是正数也可能是负数。
hashCode 使用
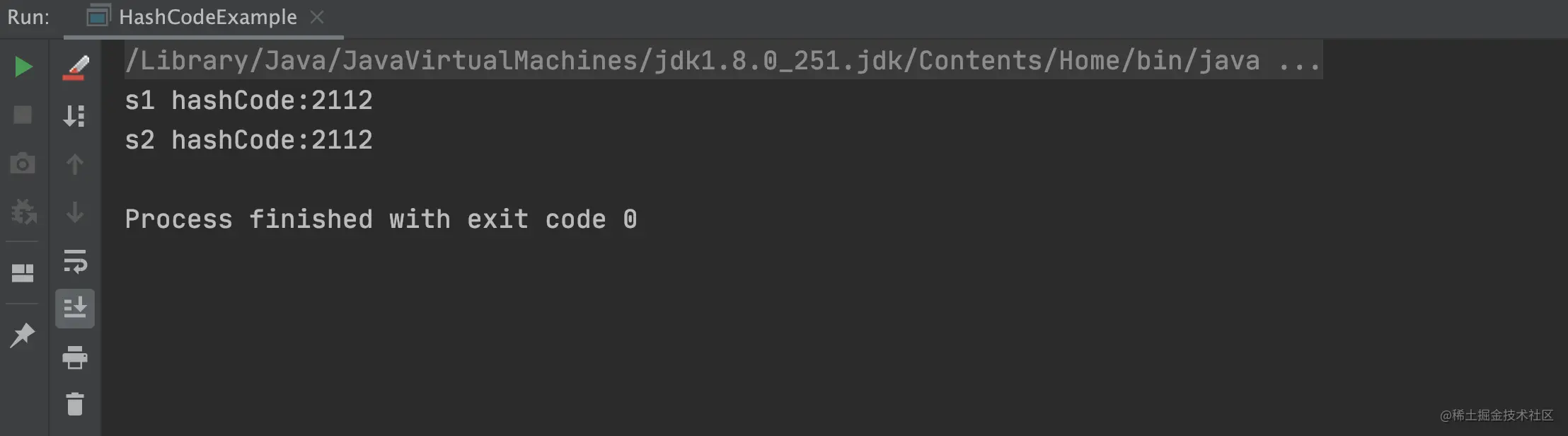
相等的值 hashCode 一定相同的示例:
public class HashCodeExample {
public static void main(String[] args) {
String s1 = "Hello";
String s2 = "Hello";
String s3 = "Java";
System.out.println("s1 hashCode:" + s1.hashCode());
System.out.println("s2 hashCode:" + s2.hashCode());
System.out.println("s3 hashCode:" + s3.hashCode());
}
}
复制代码以上程序的执行结果,如下图所示:

不同的值 hashCode 也有可能相同的示例:
public class HashCodeExample {
public static void main(String[] args) {
String s1 = "Aa";
String s2 = "BB";
System.out.println("s1 hashCode:" + s1.hashCode());
System.out.println("s2 hashCode:" + s2.hashCode());
}
}
复制代码以上程序的执行结果,如下图所示:
3.为什么要一起重写?
接下来回到本文的主题,重写 equals 为什么一定要重写 hashCode?
为了解释这个问题,我们需要从下面的这个例子入手。
3.1 Set 正常使用
Set 集合是用来保存不同对象的,相同的对象就会被 Set 合并,最终留下一份独一无二的数据。
它的正常用法如下:
import java.util.HashSet;
import java.util.Set;
public class HashCodeExample {
public static void main(String[] args) {
Set<String> set = new HashSet();
set.add("Java");
set.add("Java");
set.add("MySQL");
set.add("MySQL");
set.add("Redis");
System.out.println("Set 集合长度:" + set.size());
System.out.println();
// 打印 Set 中的所有元素
set.forEach(d -> System.out.println(d));
}
}
复制代码以上程序的执行结果,如下图所示:
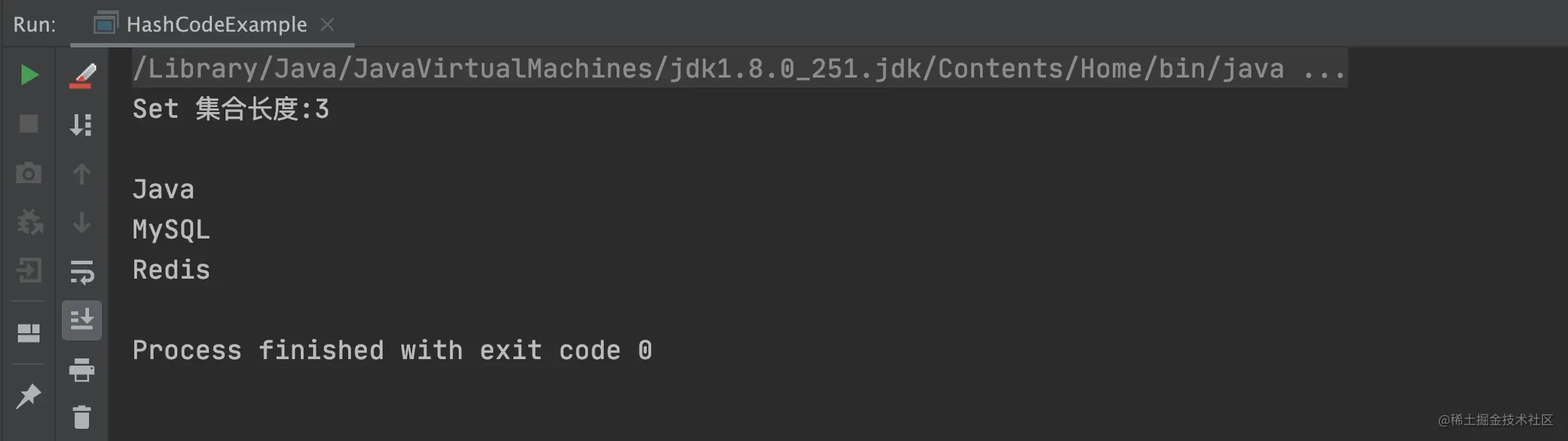
从上述结果可以看出,重复的数据已经被 Set 集合“合并”了,这也是 Set 集合最大的特点:去重。
3.2 Set 集合的“异常”
然而,如果我们在 Set 集合中存储的是,只重写了 equals 方法的自定义对象时,有趣的事情就发生了,如下代码所示:
import java.util.HashSet;
import java.util.Objects;
import java.util.Set;
public class EqualsExample {
public static void main(String[] args) {
// 对象 1
Persion p1 = new Persion();
p1.setName("Java");
p1.setAge(18);
// 对象 2
Persion p2 = new Persion();
p2.setName("Java");
p2.setAge(18);
// 创建 Set 集合
Set<Persion> set = new HashSet<Persion>();
set.add(p1);
set.add(p2);
// 打印 Set 中的所有数据
set.forEach(p -> {
System.out.println(p);
});
}
}
class Persion {
private String name;
private int age;
// 只重写了 equals 方法
@Override
public boolean equals(Object o) {
if (this == o) return true; // 引用相等返回 true
// 如果等于 null,或者对象类型不同返回 false
if (o == null || getClass() != o.getClass()) return false;
// 强转为自定义 Persion 类型
Persion persion = (Persion) o;
// 如果 age 和 name 都相等,就返回 true
return age == persion.age &&
Objects.equals(name, persion.name);
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public String toString() {
return "Persion{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
}
复制代码以上程序的执行结果,如下图所示:
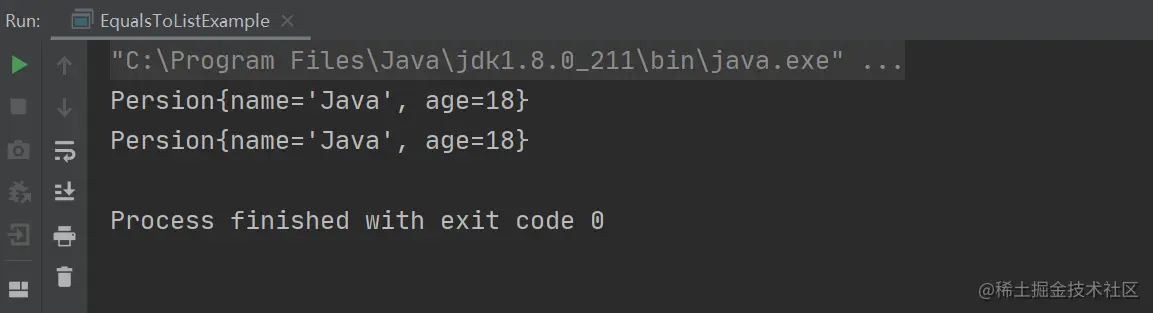
从上述代码和上述图片可以看出,即使两个对象是相等的,Set 集合竟然没有将二者进行去重与合并。这就是重写了 equals 方法,但没有重写 hashCode 方法的问题所在。
3.3 解决“异常”
为了解决上面的问题,我们尝试在重写 equals 方法时,把 hashCode 方法也一起重写了,实现代码如下:
import java.util.HashSet;
import java.util.Objects;
import java.util.Set;
public class EqualsToListExample {
public static void main(String[] args) {
// 对象 1
Persion p1 = new Persion();
p1.setName("Java");
p1.setAge(18);
// 对象 2
Persion p2 = new Persion();
p2.setName("Java");
p2.setAge(18);
// 创建 Set 对象
Set<Persion> set = new HashSet<Persion>();
set.add(p1);
set.add(p2);
// 打印 Set 中的所有数据
set.forEach(p -> {
System.out.println(p);
});
}
}
class Persion {
private String name;
private int age;
@Override
public boolean equals(Object o) {
if (this == o) return true; // 引用相等返回 true
// 如果等于 null,或者对象类型不同返回 false
if (o == null || getClass() != o.getClass()) return false;
// 强转为自定义 Persion 类型
Persion persion = (Persion) o;
// 如果 age 和 name 都相等,就返回 true
return age == persion.age &&
Objects.equals(name, persion.name);
}
@Override
public int hashCode() {
// 对比 name 和 age 是否相等
return Objects.hash(name, age);
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public String toString() {
return "Persion{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
}
复制代码以上程序的执行结果,如下图所示:
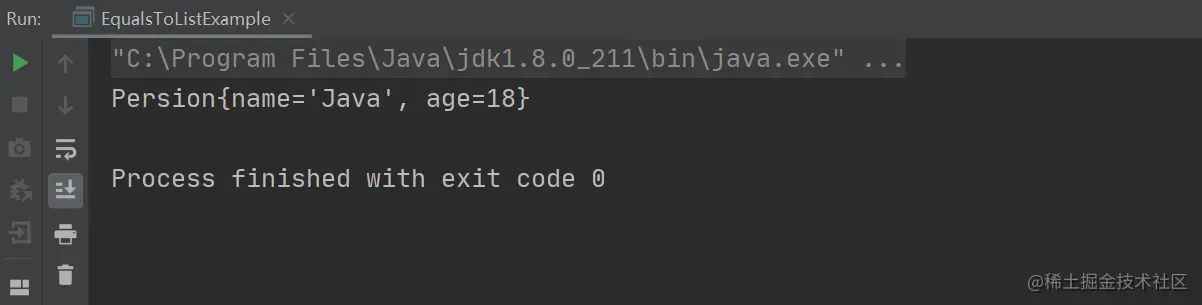
通过上述结果可以看出,当我们一起重写了两个方法之后,奇迹的事情又发生了,Set 集合又恢复正常了,这是为什么呢?
3.4 原因分析
出现以上问题的原因是,如果只重写了 equals 方法,那么默认情况下,Set 进行去重操作时,会先判断两个对象的 hashCode 是否相同,此时因为没有重写 hashCode 方法,所以会直接执行 Object 中的 hashCode 方法,而 Object 中的 hashCode 方法对比的是两个不同引用地址的对象,所以结果是 false,那么 equals 方法就不用执行了,直接返回的结果就是 false:两个对象不是相等的,于是就在 Set 集合中插入了两个相同的对象。
但是,如果在重写 equals 方法时,也重写了 hashCode 方法,那么在执行判断时会去执行重写的 hashCode 方法,此时对比的是两个对象的所有属性的 hashCode 是否相同,于是调用 hashCode 返回的结果就是 true,再去调用 equals 方法,发现两个对象确实是相等的,于是就返回 true 了,因此 Set 集合就不会存储两个一模一样的数据了,于是整个程序的执行就正常了。
总结
hashCode 和 equals 两个方法是用来协同判断两个对象是否相等的,采用这种方式的原因是可以提高程序插入和查询的速度,如果在重写 equals 时,不重写 hashCode,就会导致在某些场景下,例如将两个相等的自定义对象存储在 Set 集合时,就会出现程序执行的异常,为了保证程序的正常执行,所以我们就需要在重写 equals 时,也一并重写 hashCode 方法才行。














 291
291











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









