







但你被问到数据库那么强大,索引起到了功不可没的地位,它帮助我们可以快速定位了元素在数据库的位置,有的人可能不太明白,在数据库中通过索引(通俗地讲就是key)找到了相应地value,这和建个数组有什么区别,而且数组的查找的速度是0(1),其实数据库查找有多快,占用空间的大小有多大呢,数据库的的B树索引最初是用在哪里呢?我们带着这些问题功能来谈谈B树和B+树吧!首先看看下列数据库索引的基本图

当你在数据库配置第一列第二列第三列的时候,有没有想过这些数据是怎么分配的,在使用的时候在内存中又是如何被安排?好了上图给了我们很好的信息,具体学习过程我们在接下来慢慢讲解,先给大家讲述一下上图的基本流程,好给大家一个概念,B树索引在数据库的基本作用,上图的蓝色部分的图,相信写过基本数据库的增删改查的同学都知道,他们是一个数据库表格,这些数据被引用到内存中后,就会分配相应的内存空间地址0x07,0x56,0x6A等等,这些是不连续的(数据库的存取是巨大的,你不能在空间找到如此大的空间地址分配给他们)
假设一下col1(第一列)数据是我们的key值,我们可以通过这些key可以轻松地访问到value吗?如果知道15那么一定就可
以快速找到Bob和34吗?显然15已经不是单纯的数值,已经变成了一种地址的代表,这时候可能你会问自己,如果有两个15怎么办,空间地址是唯一的啊,如果你还记得老师说过这样一句话,主键是唯一的,数据库表格中主键不可能重复,那么就不会有两个15的出现,你的问题你应该就知道答案了吧!
既然15是索引,这些索引又是怎么在内存中分布的呢,B树(我觉得B+树更适合)给出了他的方法,上图中左侧部分就是这些key的分布,即采用了B+树的数据结构被存储起来,方便你的快速查找。
好啦,我们一起来学习什么是B树,什么是B+树吧
小生以下内容比较浅显,只给大家讲解以下我的理解,重在讲解基础,如果要深入了解的话,还请多多看看其他的知识哦(发觉自己废话真多啊,不好意思)
相信大家都知道树是什么,这个不知道的话(小生就没有办法了)。那么B树就是在树的基础上给了这些key值做了一些分布上的变化使得key可以非常容易地查找。(上图的索引为B+树的结构,不要急额)如果你理解或者知道二分查找二叉树(见下图)会很轻松理解B树的。

上图的二分查找二叉树他的定义就是中间值比左边值大,但是比右边值小,假设你想找28,你发现根是45,那28一定在左边,接着发现45的左子树的根为24,那么28必然在树的左子树的右侧,找到37,则在37的左叶子上,于是找到28了。那么B树显然有点抄袭二分查找二叉树的特别,它将key的分布几乎差不多。我们来看看B树的定义吧
定义:一棵m 阶的B-树,或者为空树,或为满足下列特性的m 叉树:
⑴树中每个结点至多有m 棵子树;
⑵若根结点不是叶子结点,则至少有两棵子树;
⑶除根结点之外的所有非终端结点至少有[m/2] 棵子树;
懂吗?答案是不懂,你也不需懂,这些是基本的概念,或者说在B树图形出来之后总结的经验,你在看完B树结构图之后你在看看概念,发现好像的确是这个样子哦!!!B树结构图如下
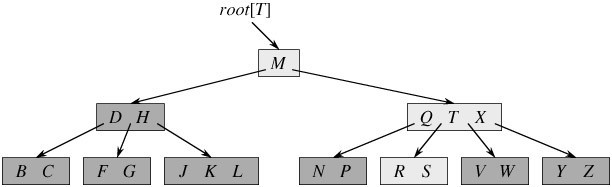
假设你想找S结果发现S>M 于是你找右子树,你发现QTX(这个我需要解释一下了,为什么会出现这个图形,这和B树增删有关,我们下则再讲)可以讲区域分为四段(一条直线上面三个不同的点,是分成四段吧)分别为<Q Q-T T-X 和 >X ,S在Q-T这个区域如是在于是沿着指针找到RS,即找到S了,那么S中必然有地址啊,找到内存地址害怕找不到value吗?
那什么又是B+树索引呢,它又是怎么做到查找索引值的呢,我们先看看B树和B+有什么区别,听名字我们都知道B+是B树的一个变形,他们区别是非常关键的。
1. 有n棵子树的结点中含有n 个关键字;
2.所有的叶子结点中包含了全部关键字的信息,及指向含有这些关键字记录的指针,且叶子结点本身依关键字的大小自小而大的顺序链接。
3.所有的非终端结点可以看成是索引部分,结点中仅含有其子树根结点中最大(或最小)关键字
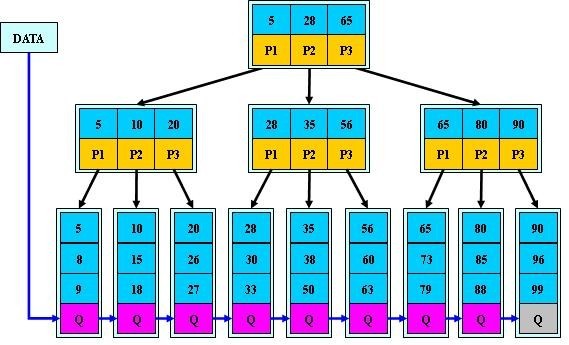
我们按照上图一次说明一下,我们不难发现,叶子节点之间是相连的可以说就是一个大链表,也就是说找到了一个叶子,其他所有叶子也就等于找到了,所有p值(P1,p2,p3)都是Q值中的最小值(当然也可以是最大值)每一层都是下一层的最小值或者最大值,等于你有任何数我都知道要找它的哪个子树中这也是B+比B的最大的亮点更新,不知道同学们有没有发现,B+树所有的索引项都是在底层,也就是说再来一个索引项也从底层加入,那么很难破坏整个树的层数(也就是说B+树要比B树更加平衡点)这是第一突破。那么第二突破是什么呢,这点很重要,这也决定了B+树在数据索引方便要优先于B树B+树只要遍历叶子节点就可以实现整棵树的遍历。而且在数据库中基于范围的查询是非常频繁的,而B树不支持这样的操作(或者说效率太低),通俗点讲一下就是假设我们要找5到20,如果我们用B+树我们就可以实现一次查询就知道了要用最左侧的三棵小子树,要是选用B树的话,则我们要从头查找三次哦,你说哪个快呢!!
以上就是我所了解的数据库索引中B树索引,共同进步,可以留言给我,谢谢!!















 6844
6844

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









