







文章目录
更新日期:2022/9/14
2022年9月14日更新
当时为了把这个实验做好,花费了不少功夫。然而,这个算法仍然很不稳定,实际效果比较差劲。虽然在本文的例子表现很好,但随便找一个其他的例子,可能就确定不了四个顶点,也就没法成功矫正。
现在的话,这种传统的方法应该都过时了吧。应该可以训练CNN模型来找到四个顶点,然后进行矫正,网上也应该有很多成熟的方法。
欢迎大家交流学习!
代码:
github: https://github.com/JianghaoLan/doc-rectify-opencv
上不去github的同学也可以去gitee:
gitee: https://gitee.com/lanjianghao/doc-rectify-opencv
前言
同一平面物体在不同视角下的图像之间满足一个特殊的几何变换:单应性变换。
单应性变换是指一个图像中的坐标 X = ( x , y , 1 ) X = (x,y,1) X=(x,y,1)与另一个图像中对应点 U = ( u , v , 1 ) U = (u,v,1) U=(u,v,1)之间的变换是一个可逆的 3 × 3 3\times 3 3×3矩阵(单应矩阵,Homography):
U T = H X T U^T = H X^T UT=HXT
本次实验给出6张图片,要求对图片中的文档进行透视矫正(详细实验内容及要求请见下文)。
要得到图像中文档与真实文档的单应变换矩阵,首先要找到图像中文档的4个顶点,是实验的难点。
提示:博主正在学习《计算机视觉》(本科)课程,此博文原为本人实验课程技术报告,经整理后发布,欢迎大家相互交流学习。本人才疏学浅,如果有不到位的地方,欢迎大家提出意见和建议。
文章除特别注明处外,均为博主原创,转载请附原文出处。
实验任务与要求
实验任务与要求如下:
对发生透视变换的文档图像进行几何校正处理,得到规范的文档图像。
几何校正的目的是把发生了透视变换的目标变换为具有真实比例和角度的目标。
本次实验提供了6张图像,每张图像中含有一个平面文档,你要对这6张图像中的文档进行校正,并输出校正结果。欢迎大家自己拍摄文档/海报等的图像,看看使用自己开发的程序能否正确的校正。
可以要求手工输入文档的真实长宽比例,或者真实长宽参数。
通过实验探索:
1) 如何自动提取文档图像的四个角点或四条直边;
2) 如何抑制各种噪声干扰;
实验材料:
(实验图片为课程老师原创,经同意后发布,请勿盗用。部分图片由于包含个人信息,已经过处理隐去)
以下六张图片分别为1.jpg、2.jpg、3.jpg、4.jpg、5.jpg、6.jpg:





6个文档的物理尺寸分别是:
图片文件 (长,宽)(cm) 1.jpg(24, 17) 2.jpg(18.2, 11.2) 3.jpg(20, 14) 4.jpg(9.5, 6.5) 5.jpg(12, 8.5) 6.jpg(26, 21)
注:因文章中部分图片包含个人信息,已经过处理隐去
1 实验情况概述
实验中实现了完整的文档矫正函数,输入为图像和其它参数,输出为校正后的图像。程序会自动对图像进行矫正,无需人工干预。
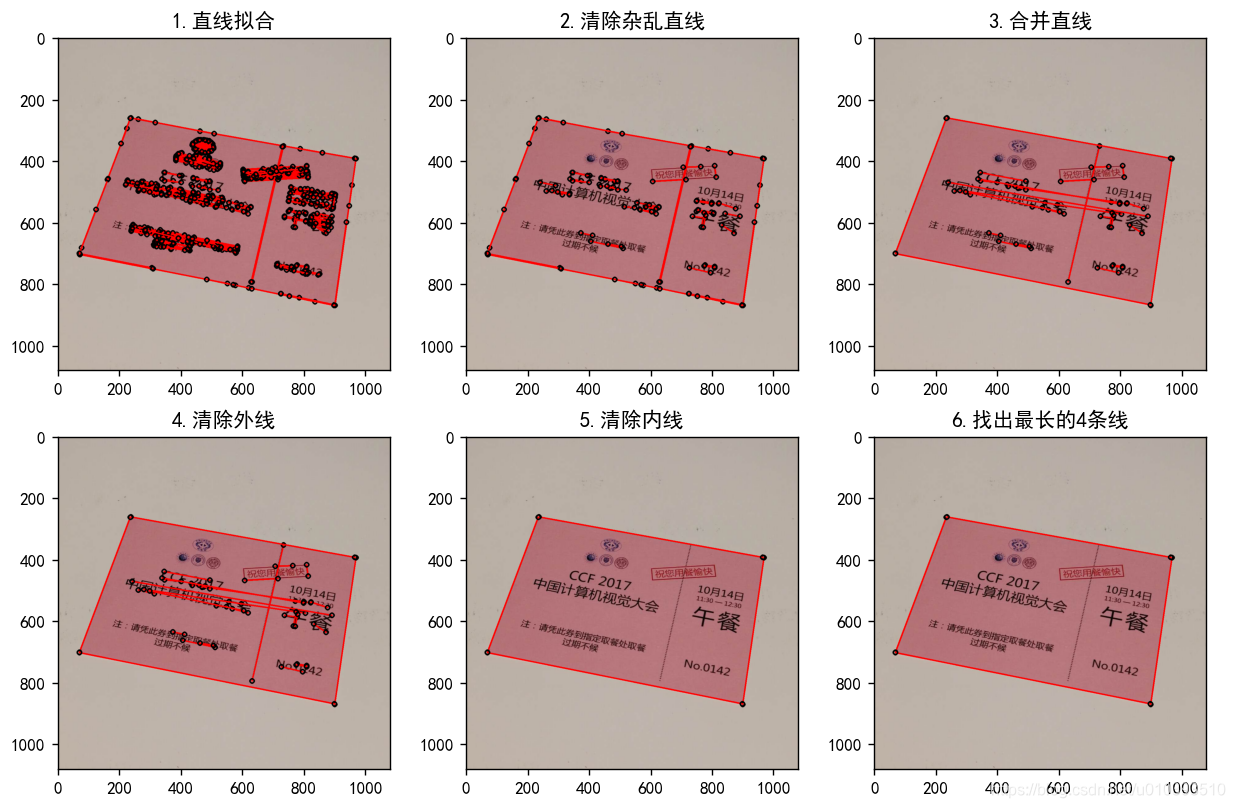
实验对原图哈夫变换拟合出的直线依次使用4种方法进行去噪,有效去除了干扰直线,最后取出最长的四条线,认定为文档边缘,计算出文档4个顶点进行矫正。在给出的6幅图像上进行文档矫正,取得了满意的效果。其中一张图片的处理过程及最终效果如图1所示:

2 实验过程
实验中实现了完整的文档矫正函数,输入为图像和其它参数,输出为校正后的图像。文档矫正的步骤如下:
步骤1:拟合直线;
步骤2:清除杂乱直线;
步骤3:合并直线;
步骤4:清除外线;
步骤5:清除内线;
步骤6:找到图像中文档的4个顶点坐标和文档实际顶点坐标;
步骤7:透视矫正。
下面给出每一个步骤的详细介绍
2.1步骤1:拟合直线
该步骤分为两步:1)Canny边缘检测;2)哈夫变换拟合直线。
Canny边缘检测时,应该使用较小的阈值;同样,哈夫变换拟合直线时,也使用较小的计数阈值、最小直线段长度,直线段之间的最大间隔。目的是使其对个别图像不明显的文档边缘有更好的拟合结果。
比如,图像“Lab3-5.jpg”的两侧边缘基本与背景融合,如图2所示,过严格的参数会使边缘直线不能被拟合出来。

该步骤的结果图如图3所示:

2.2 步骤2:清除杂乱直线
由于步骤1边缘检测、拟合直线时使用了较宽松的参数,导致拟合直线时,文字、纹理等变化较快的地方会出现大量的杂乱直线,如图4所示。

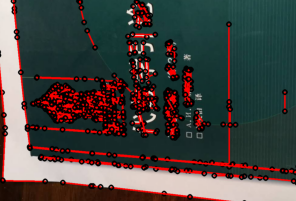
步骤2的作用就是对这些杂乱直线进行清除。
判定一条直线是否为杂乱直线的方法为:统计该条直线两端点附近其它直线(端点)的个数,如果超过一定阈值,则该直线为杂乱直线。
根据此判断杂乱直线的方法,实验中实现了清除杂乱直线的函数,方法为统计每条直线两端点附近(参数指定范围)其它直线(端点)的个数,如果个数超过指定个数,则删去该直线。该步骤对噪声进行了良好的去除,方便后续的操作。
处理前和处理后的对比如图5所示。


2.3 步骤3:合并直线
步骤1中为了提高文档边缘的识别效果,使用了较小的最小直线段长度,直线段之间的最大间隔参数,导致同一边上拟合出的直线既短又多,不利于识别真正的边缘。
因此,该步骤的主要工作是找出所有直线中实际上为同一条直线的多条直线,将其合并为一条,并使合并后的直线长于合并前的直线长度。
该步骤的算法如下:
直线之间两两比较,如果两直线倾斜角度相近(夹角小于一定阈值),则认为两直线平行,再进行以下判断:
尝试从两直线中各取一点,连成一条新直线,如果这条直线与原直线倾斜角度相近(夹角小于一定阈值),则认为原两直线是同一条直线,将其合并。合并时,取两直线所有四个端点中相距最远的两点,作为新直线。
实验中实现的合并直线算法,当一条直线与多条直线平行时,会选取连成的新直线中与原直线倾斜角度最近似的直线进行合并。
拟合结果经该步骤处理前和处理后的对比如图6所示。


2.4 步骤4:清除外线
此步骤可看作是步骤5:清除内线的预处理。清除内线是指清除文档内部的线,仅保留文档边缘线。但是,由于图像中的文档外部也可能检测到一些较大的噪声直线干扰,若直接清除内线,则会使文档外部的干扰直线被当作文档边缘,而真正的文档边缘被当作文档内线被清除。
外线噪声的实例如图7。


因此,该步骤的目的是对这些线进行清除。
从给出的6张图片来看,外线主要是由于桌面、背景纸张等造成,这些物体由于并未完整地显示在图像中,因此检测出的直线的两个端点或某一端点靠在图像边缘。
该步骤的算法对这些端点靠近图像边缘的直线进行删除,实验中,实现该算法的函数会将离图像边缘近于一定阈值的直线删除。该步骤处理前后对比如图8所示。


2.5 步骤5:删除内线
某些文档受封面图案的影响,导致拟合出较长的直线在文档内部,影响真正文档边缘直线的识别,如图9所示。

由于文档封面图案的特点,这些内线大多与文档边缘平行,可以利用此特点来进行检测和去除。
实验中删除内线的算法如下:
1)首先,设置一个向量(或数组)
flag,来标记每条直线是否要保留,刚开始flag向量元素全为 f a l s e false false;
2)遍历每条直线,分别执行如下操作:找出该条直线的所有近平行直线,组成近平行直线组。近平行直线是指与该直线夹角小于一定阈值的直线。找出近平行直线组中相距最远的两条直线,flag标记设为 t r u e true true;
3)最终得到的flag向量中值为 t r u e true true的表明示对应直线要保留,值为 f a l s e false false表示对应直线要删去.注1:找出近平行直线组中最远两条直线方法为:找出法线式方程中 ρ ρ ρ最大和 ρ ρ ρ最小的两条直线。
注2:为了有更好的稳定性,实验中在该步骤处理前先删去了长度过短的直线。
该步骤处理前后的直线数组对比如图10所示。


2.6 步骤6:找到图像中文档的4个顶点坐标和文档实际顶点坐标
该步骤可分为以下几个分步骤:
1)首先,在经过前述处理过后的直线组中找出最长的4条,认定为文档的4条边;
2)然后,根据这4条边计算出文档的顶点,按正确顺序排列好;
3)根据文档实际比例计算文档实际顶点坐标
其中,分步骤2是该步骤的难点和重点,首先要计算出文档的四个顶点,然后再将4个顶点按照正确顺序排列好。下面将着重介绍这两部分。
2.6.1 计算出文档的4个顶点
要根据4条边计算顶点,需要使用计算直线交点的方法。但是一般情况下,任意一条直线与其它三条直线均有交点,而实际上只有与邻边的交点才是正确的,因此首先要知道哪两条边互为对边,计算交点时一组对边之间不计算。
由于透视图中对边之间的倾斜角度仍然很接近,一般小于邻边之间的倾斜角度差距,故可以认为夹角最小的两条直线互为对边。
方法如下:从4条边中取出任意一条边,计算其与其它三条直线的夹角,与其夹角最小的另一条直线认为是该直线的对边。
当分辨出两组对边后,就可以在两组对边之间两两计算交点,获得4个交点坐标,即为文档4个顶点。
2.6.2 将4个顶点正确排列
4个顶点的排列顺序应该与实际顶点相对应,否则,会在之后的单应变换矩阵计算中得到错误的单应变换矩阵。
本文规定正确的排列顺序为:4个顶点顺时针的排列。
实验中设计了一种巧妙的方法将4个顶点进行正确排列。思路如下:
从4个顶点的均值中心出发,分别连接4个顶点,构成4个向量,再根据向量的角度对4个向量进行排序,排序后的排列即为正确排列。
为了使程序能同时适应横放、竖放的文档,在设计该函数时,加入了开始向量参数start_vector,可以通过该参数设置4个顶点的排列从哪一个开始。加入start_vector参数后,该步骤算法的排序结果为:以4个顶点的均值中心为原点放置向量start_vector,将start_vector沿顺时针旋转一周依次碰到的4个点的顺序即为最终排序结果。
加入start_vector参数后的具体实现方法如下:
1)计算4个交点的均值中心点,从该中心点出发与4个交点分别构成4个向量;
2)计算4个向量与向量start_vector的夹角注:此处夹角范围为 [ 0 , 2 π ) [ 0, 2\pi ) [0,2π),非传统定义,定义如下:将一向量沿顺时针旋转,如果在某一位置与另一向量同向,则与该向量夹角为原向量转过的角度;
3)按与向量
start_vector的夹角将4个交点从小到大排列,得到最终排序结果。
可以通过参数start_vector设置4个顶点的排列从哪一个开始。比如,对于图11(a),设置开始向量为(0, 1),对于图11b),设置开始向量为(-1, 0),使它们的顶点排列顺序都能从文档左上角的顶点开始。




2.7 透视矫正
经过前述几个步骤,从原图像中得到了文档的4个顶点坐标和原文档实际的4个顶点坐标。
opencv中的getPerspectiveTransform函数根据4对点计算透视变换,得到单应变换矩阵;warpPerspective函数可以实现透视变换,根据单应变换矩阵对文档进行矫正。
直接使用getPerspectiveTransform计算单应变换矩阵,再利用warpPerspective即可还原出矫正的文档图像。
3 实验结果与分析
3.1 实验结果
对于实验给出的6张图片,程序均能计算出正确的文档顶点,并还原出校正后的图像。6幅图像文档矫正的处理过程和结果如图12所示。


1.jpg矫正结果


2.jpg矫正结果


3.jpg矫正结果


4.jpg矫正结果


5.jpg矫正结果


6.jpg矫正结果
3.2 实验不足分析
不足1:实验中认为贴近边缘的线为外线,依据是在实验给出的6幅图像中,外线主要是由于桌面、背景纸张等造成,这些物体由于并未完整地显示在图像中,因此检测出的直线的两个端点或某一端点靠在图像边缘。但是,更实际的情况中,可能会检测到在文档外、但不贴近边缘的外线,这种外线不会被程序识别并除去,因此,如果存在过长的这样的线,可能会导致错误的文档边缘判断。
不足2:在1.jpg图像中,由于书本封面图案较为杂乱,导致合并直线后出现很长的干扰直线,且与文档真实边缘夹角均较大,无法被清除内线环节除去,险些被判断为文档真正边缘。没有被判断为真正文档边缘的原因是,这些干扰直线一端贴近文档边缘,因此在清除外线处理中被除去。虽然在最终在该幅图像中识别正确,但可见该程序对于封面图案较为杂乱的透视图像的识别会受到较大干扰。















 463
463

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









