






前言
作为Hadoop体系中BigTable中的具体实现. HBase中主要解决的如何存储数据, 并建立相应索引, 快速查找数据. 其特性是写快, 读慢.
本章就简单的聊聊这些过程: 存储数据/查找数据.
基础知识
在前面的章节內, 已经讲过HBase內主要有如下的组成部分.
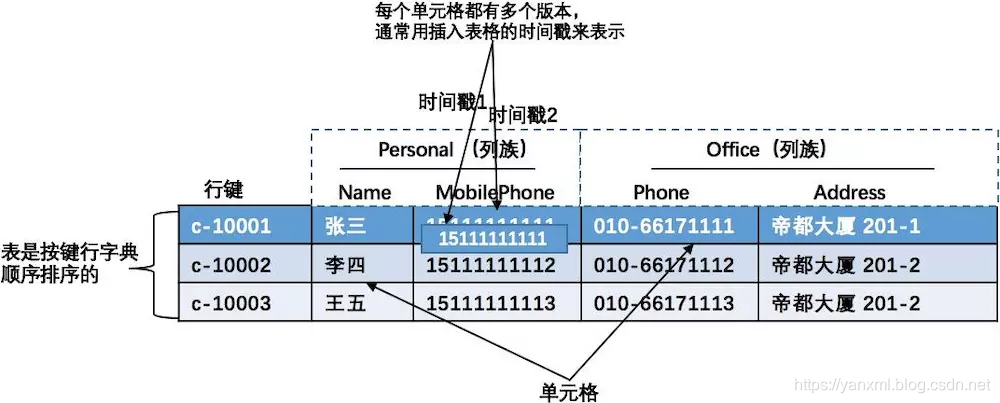
- Table
- Row Key
- Columns Family
- Cell
- Time Stamp
这边不再重复啰嗦. 详细请看HBase Shell 基本使用 中, 基础知识的部分.
基本原理
-
整体组件概览
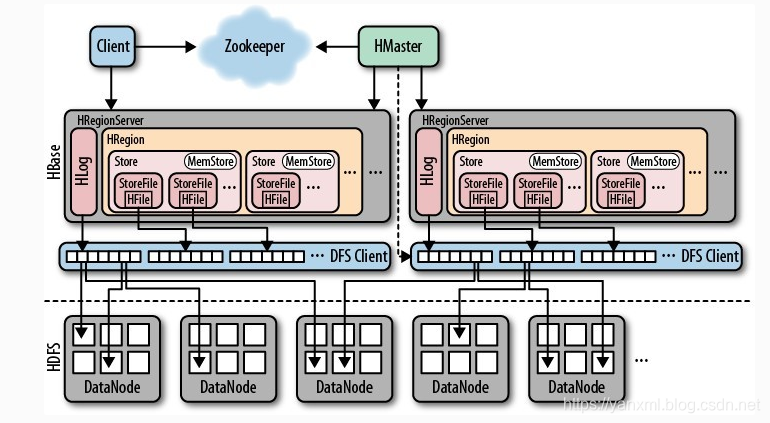
-
RegionServer主要作用是对于多个Region管理, 以及对其HFile(物理I/O)与MemStore(内存)的管理.其主要的组件为:HLog用于记录操作日志.HRegion存储器, 其中又细分为多个Store.HLog是一个AppendLog,只能添加, 不能修改.- 每个
Stroe内分为MemStore(内存存储)与StoreFile/HFile(路径存储).
-
HMaster主要负责RegionServer的调度工作.- 对
Table的增删查改. Region在哪台RegionServer上.Region Split(重新分片)后, 对于Region的分配.- 宕机和加入新机器后的重新分配.
- 对
-
ZooKeeper主要负责协助HMaster和HRegion完成工作. 主要作用在于配置调度文件的共享.
存储数据
Client端向HRegionServer发生写请求;HRegionServer将数据写入HLog(write ahead log). 为了数据的持久化和恢复.HRegionServer将数据写入内存MemStore.- 反馈
client,写入成功.
数据flush过程
写数据时, 客户端通过ZooKeeper定位, 找到一台RegionServer. 随后, 通过HDFS API将数据写入HDFS内.
- 当
MemStore内的数据到达128M后, 将内存内数据写入硬盘(HDFS), 同时删除HLog中的历史数据. - 在
HLog内标记点.
读取数据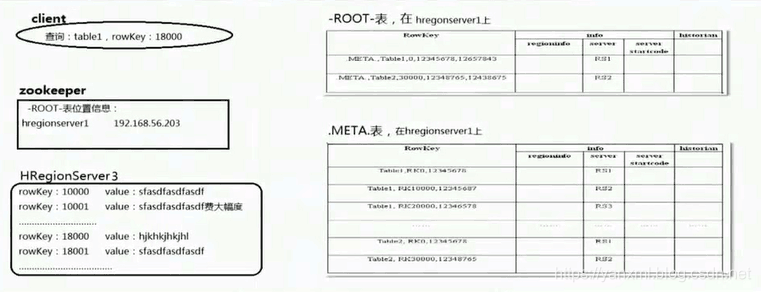
Client通过ZooKeeper查询到记录该表Root表所在的结点;- 通过
Root表寻找到相应的Meta表. - 通过
Meta表查找真正存储数据的结点. (如果数据在内存内, 直接返回; 如果在HDFS内, 从HDFS上获取.)
数据拆分&数据合并&宕机
- 合并: 将多个
HDFS块内的数据进行合并, 合并成新的HDFS块. 目的是, 删除冗余. - 拆分: 当某个
HDFS块过大时, 将其拆分成小块. 目的是, 提高运行和查询的效率. - 宕机: 当
RegionServer宕机后,HMaster将RegionServer上的HLog拆分给其他RegionServer, 并修改.META表.
HMaster依赖ZooKeeper
- 保存HMaster地址,和backup-master地址;
1.1 管理HregionServer;
1.2 做增删改查的操作;
1.3 管理HregionServer的表分配; - 保存表 -ROOT地址. (HBase默认根目录,检索表)
- HRegionServer列表.(表的增三改查,和dfs交互,存储数据.)
Others
与传统的RDBMS的B+树型结构不同的是, HBase文件系统采用LVS的形式存储.
具体可以看下HBase核心概念(LSM树、底层持久化、Region切分合并、日志
Reference
[1]. HBase Region合并分析
[2]. 详解HBase架构原理
[3]. HBase核心知识点总结
[4]. 一篇文章让你了解Hive和HBase的区别
[5]. 总结Hbase 与 MongoDB
[6]. HBase使用场景和成功案例
[7]. 聊聊MySQL、HBase、ES的特点和区别

















 4376
4376

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









