







 本文详细解析了Hadoop启动后PID文件的存储位置,默认位于/tmp目录。探讨了启动与停止过程中PID文件的作用,包括进程号的记录与读取。同时,指出了/tmp目录的弊端并提出了解决方案,即自定义PID文件的存储路径。
本文详细解析了Hadoop启动后PID文件的存储位置,默认位于/tmp目录。探讨了启动与停止过程中PID文件的作用,包括进程号的记录与读取。同时,指出了/tmp目录的弊端并提出了解决方案,即自定义PID文件的存储路径。
1 存储位置
hadoop启动之后,pid文件是存储哪里?
我们可以通过查看 hadoop-env.sh文件
cat etc/hadoop/hadoop-env.sh
从下图可以看出hadoop默认的pid文件是存储到/tmp目录的

从下图可以看出,后缀名是.pid的就是hadoop的pid文件

2 启动和停止
我们启动的时候,是执行sbin/start-df.sh文件,我们看一看这个文件
cat sbin/start-dfs.sh
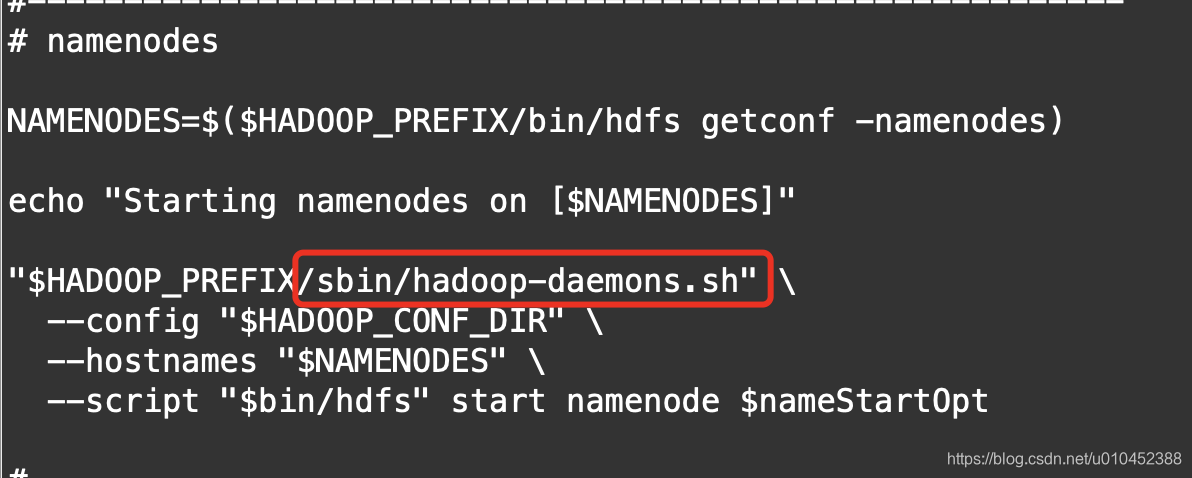
从上面这个图可以看出,启动namenode节点的时候,调用了hadoop-daemons.sh文件了,我们再看看这个文件
cat sbin/hadoop-daemons.sh

从上图可以看出,在最后一行又调用了hadoop-daemon.sh文件,我们在看看这个文件
cat sbin/hadoop-daemon.sh
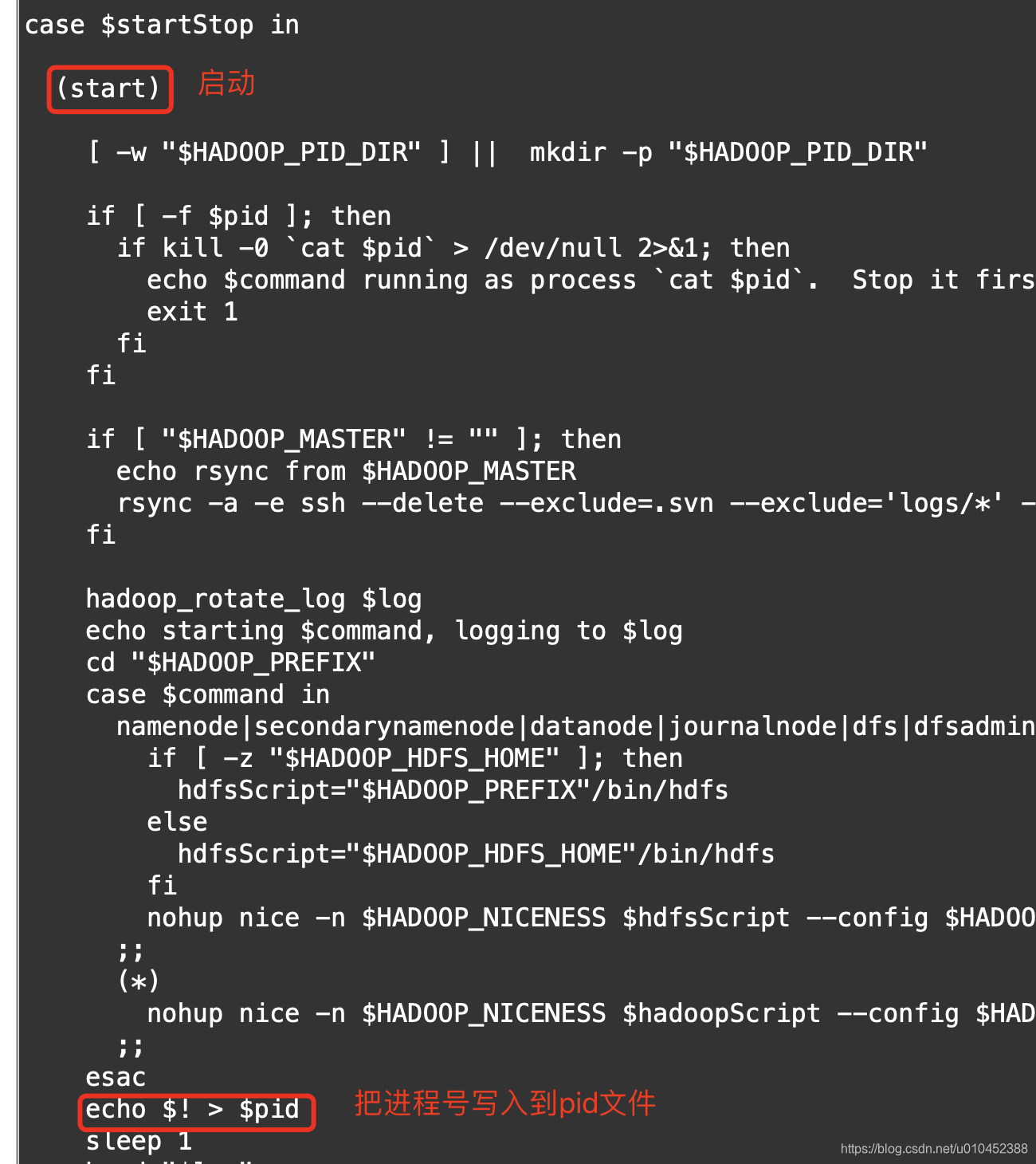
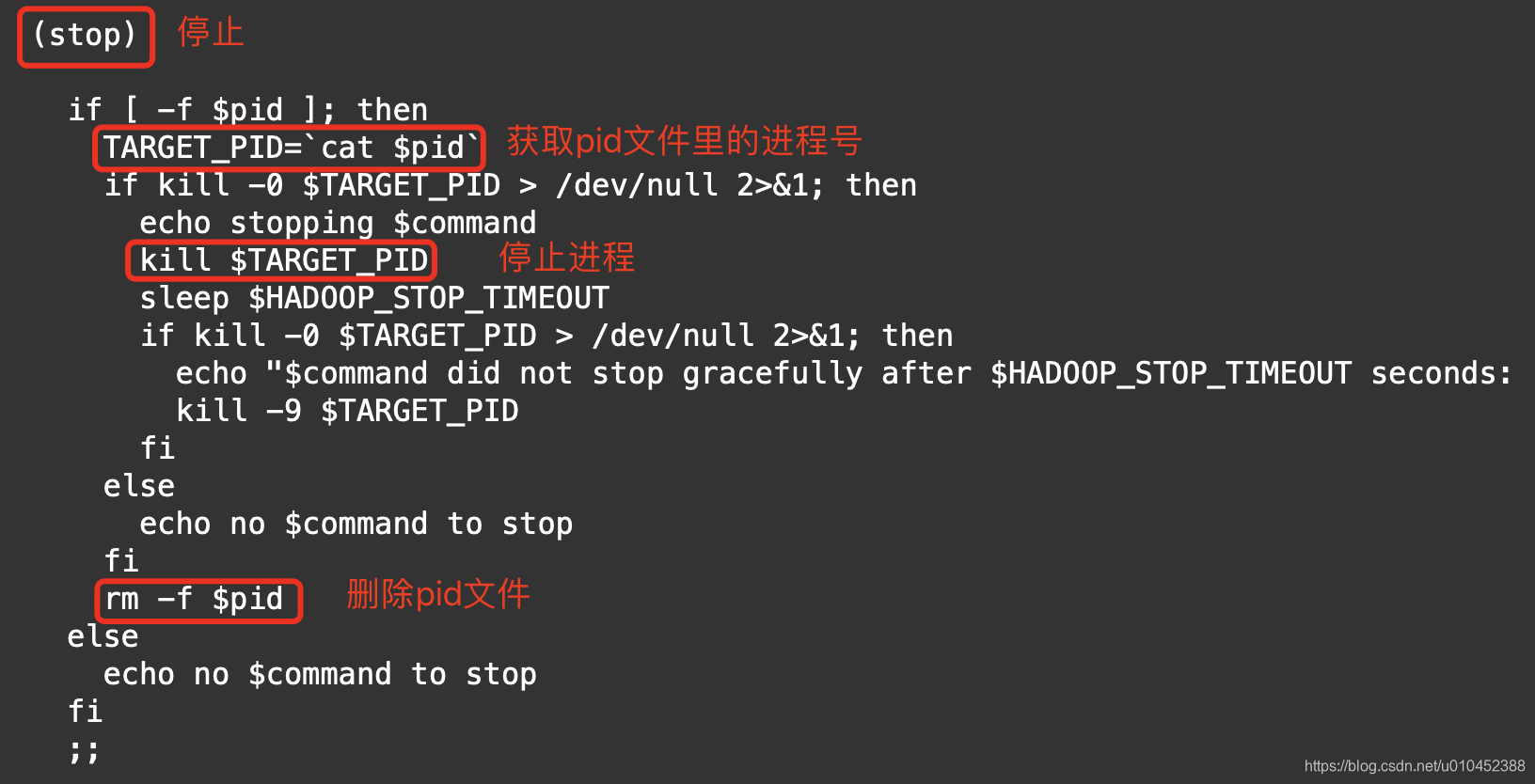
从上面两张图可以得出结论:
a) hadoop启动的时候,会生成pid文件,并把进程号写入到pid文件
b) hadoop停止的时候,会到pid文件中获取进程号,然后停止进程,最后删除pid文件
下面我们做一下验证:
a) 看下namenode的进程号是不是和pid文件里的进程号一样

从上图可以看出,进程号是一样的,说明我们前面的推理是正确的
b) 我们把生成号的namenode的pid文件名字改一下,停止的时候脚本会找不到pid文件,也就不会停止namenode进程了
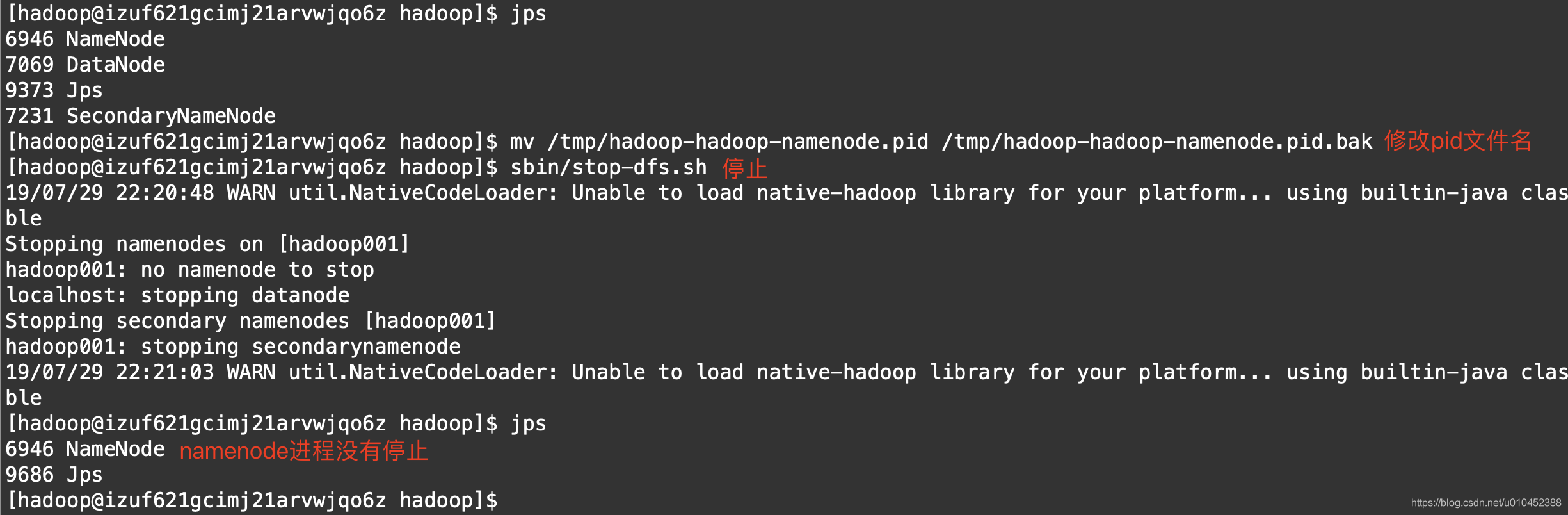
从上图可以看出,我们的两个推理是正确的
3 tmp目录的弊端
linux的/tmp目录会自动清理一段时间没有访问的文件,一般都是30天,假如hadoop启动了30天以上,那么pid文件会被删除,再调用停止的时候会停止不了,生产上一般不会放在/tmp目录下,下面我们自己创建个目录存放pid文件
#创建文件夹
mkdir -p /data/tmp
#赋予权限
chmod 777 -R /data/tmp
然后修改etc/hadoop/hadoop-env.sh文件
vi /etc/hadoop/hadoop-env.sh
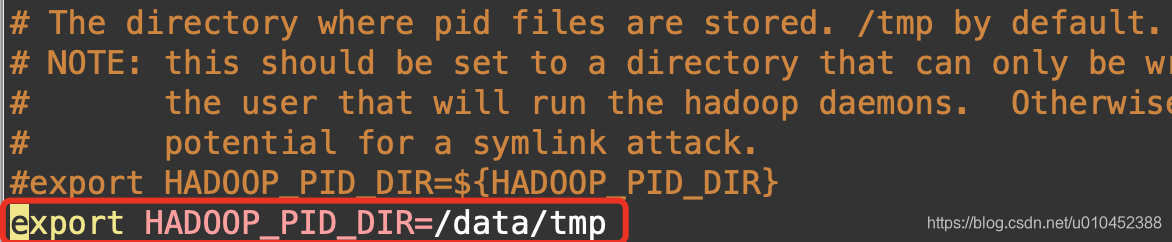
然后启动
sbin/start-dfs.sh
启动之后,我们查看pid文件


















 311
311

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









