







上一篇文章中介绍了Elasticsearch中是如何搜索文本的,同时也简述了在es里面索引数据结构的特点不可变性。
索引不可变性的缺点限制了单个索引存储的最大数据量以及更新的频次,所以es面临的问题是如何解决倒排索引不可更新的特点而同时仍然保持不可变特性带来的好处。
答案就是使用多个索引
代替原来的每次重写整个索引,es里面采用方式是增加新的索引来反映最近的变化,然后查询的时候一次查询所有的倒排索引,从最早的一直到最新的,然后在合并结果返回。
在lucene里面一个索引是多个segment加上一个commit point文件组成,每个segment都是一个倒排索引,而commit point这个文件标记了所有的已知的segment文件。如下图所示:

注意lucene里面的index在es里面叫做shard,es里面的一个index可以包含多个shard,对es里面的一个索引查询在es底层会把查询请求发送到所有shard里面最后在把结果集合并并返回。
回到文章开头的问题,es如何利用多索引来解决更新的问题,下面我们看下数据被写入es的过程:
(1)当es收到一个写入或者更新的请求时,首先会把这个数据收集在内存的indexing buffer
(2)经过一定的间隔或者外部命令触发时,会在内存缓冲区生成新的segment。
(3)然后segment首先会被写到filesystem cache中,这个时候其实搜索就能搜到了。
(4)然后经过一段时间filesystem cache中的segment会被fsync到磁盘文件上并在commit point文件中记录新segment文件名称,同时新的segment会被打开确保搜索可见
(5)最终内存里面buffer区会被清空,并等待收集新的documnet。
如下图:

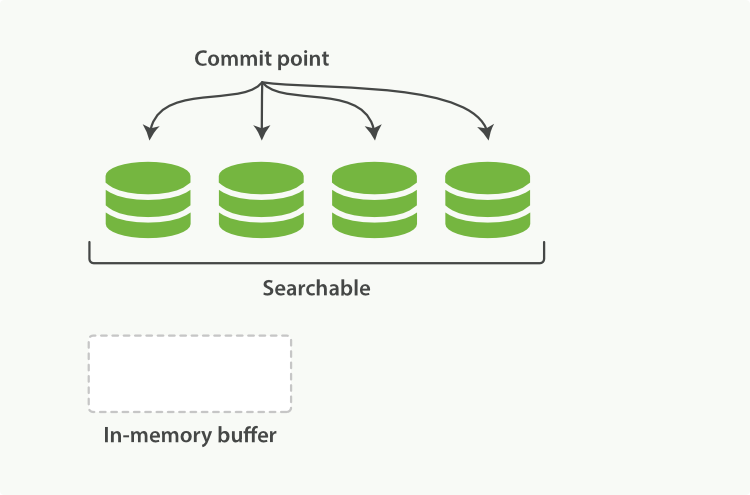
当收到查询请求时,所有的sengment包含内存和磁盘中的会被依次查询,最终聚合所有segment并准确计算每个document的相关性,上面的实现方式可以相对代价比较小的方法处理新增的document。
上面介绍的是新增数据的处理,接下来我们看下如果有删除和更新请求那么es是如何处理的。
首先我们知道sengments本身是不可变的,所以document是不能从旧的segments中移除,同时也不能被更新,那么es是如何处理删除和更新请求的呢?
在每次commit point时,es会生成一个后缀为.del的文件,这个文件标记了所有已经被删除的数据,在一条数据被删除时,es仅仅会在.del文件里面做个删除标记,被标记删除的数据仍然会被查询到,但是在最终返回结果之前,被标记删除的数据会被移除,这就是es里面删除的实现逻辑。
同理更新的逻辑也类似,当一个document被更新时,旧版本的document也会在.del文件里面被打上删除标记,新版本的document会被索引到一个新的segment里面,这个时候的查询会同时把两者都查询出来,但在最终返回结果之前被标记删除的旧版本数据会被移除掉。
以上就是es里面实现动态更新索引的内容,在这里我们能看到es里面更新和删除都类似于采用伪删除的策略来实现,到这里大家可能有个疑问,那些被标记删除的数据,什么时候才会被文件系统真正的清除,毕竟量大了还是对性能有一点影响的,这个在后面segment merge的文章中介绍。















 224
224

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









