







本文将通过朴素贝叶斯解决邮件的分类问题。理论文献参考:http://openclassroom.stanford.edu/MainFolder/DocumentPage.php?course=MachineLearning&doc=exercises/ex6/ex6.html。文章将分为三个部分,首先介绍一下基本的概率概念,然后对给出了特征的邮件进行分类,最后给出邮件特征的提取代码。
概率知识
1、概率:
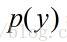 表示在一系列事件(数据)中发生y 的概率。
表示在一系列事件(数据)中发生y 的概率。
2、条件概率:
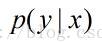 表示给定x 后,发生y 的概率。
表示给定x 后,发生y 的概率。
对于分类来说,就只有两种情况:

3、贝叶斯定理:
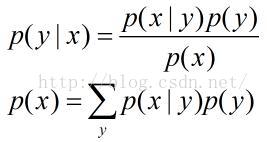
其中
称之为先验概率,即不需要考虑x 的影响;
表示给定x 后,发生y 的概率,故称之为y 的后验概率。
称之为先验概率,即不需要考虑x 的影响;
表示给定x 后,发生y 的概率,故称之为y 的后验概率。
对于本实验来说,我们将用一个多项的贝叶斯公式:
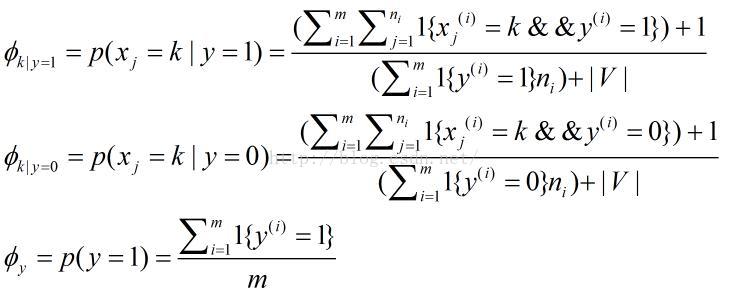
其中
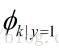 表示在一封垃圾邮件中给定单词是字典中第k个单词的概率;
表示在一封垃圾邮件中给定单词是字典中第k个单词的概率;
表示在一封垃圾邮件中给定单词是字典中第k个单词的概率;
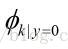 表示在一封非垃圾邮件中给定单词是字典中第k个单词的概率;
表示在一封非垃圾邮件中给定单词是字典中第k个单词的概率;
 表示训练邮件中垃圾邮件所占概率;
表示训练邮件中垃圾邮件所占概率;
m 表示训练邮件的数量,第i 封邮件包含
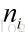 个单词,字典中包含
个单词,字典中包含
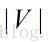 个单词。
个单词。
个单词,字典中包含
个单词。
邮件分类
对于给定了特征的邮件来说,只需对训练邮件计算出垃圾邮件和非垃圾邮件对应特征的概率即可,然后通过贝叶斯公式计算出给定特征的邮件,其是垃圾邮件和非垃圾邮件的概率大小,从而确定分类。
clc, clear;
% Load the features
numTrainDocs = 700;
numTokens = 2500;
M = dlmread('train-features.txt', ' ');
spmatrix = sparse(M(:,1), M(:,2), M(:,3), numTrainDocs, numTokens); % size: numTrainDocs * numTokens
% row: document numbers
% col: words in dirctionary
% element: occurrences
train_matrix = full(spmatrix);
% Load the labels for training set
train_labels = dlmread('train-labels.txt'); % i-th label corresponds to the i-th row in train_matrix
% Train
% 1. Calculate \phi_y
phi_y = sum(train_labels) ./ length(train_labels);
% 2. Calculate each \phi_k|y=1 for each dictionary word and store the all
% result in a vector
spam_index = find(1 == train_labels);
nonspam_index = find(0 == train_labels);
spam_sum = sum(train_matrix(spam_index, :));
nonspam_sum = sum(train_matrix(nonspam_index, :));
phi_k_y1 = (spam_sum + 1) ./ (sum(spam_sum) + numTokens);
phi_k_y0 = (nonspam_sum + 1) ./ (sum(nonspam_sum) + numTokens);
% Test set
test_features = dlmread('test-features.txt');
spmatrix = sparse(test_features(:,1), test_features(:,2),test_features(:,3));
test_matrix = full(spmatrix);
numTestDocs = size(test_matrix, 1);
% Calculate probability
prob_spam = log(test_matrix * phi_k_y1') + log(phi_y);
prob_nonspam = log(test_matrix * phi_k_y0') + log(1 - phi_y);
output = prob_spam > prob_nonspam;
% Read the correct labels of the test set
test_labels = dlmread('test-labels.txt');
% Compute the error on the test set
% A document is misclassified if it's predicted label is different from
% the actual label, so count the number of 1's from an exclusive "or"
numdocs_wrong = sum(xor(output, test_labels))
%Print out error statistics on the test set
error = numdocs_wrong/numTestDocs<pre name="code" class="plain">log_a = test_matrix*(log(prob_tokens_spam))' + log(prob_spam);
log_b = test_matrix*(log(prob_tokens_nonspam))'+ log(1 - prob_spam); 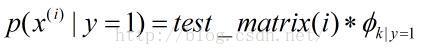 ,即对于每一个特征单词求总的概率
,即对于每一个特征单词求总的概率
然后求对数值,应该是:
log_a = log(test_matrix * prob_tokens_spam') + log(prob_spam);
log_b = log(test_matrix * prob_tokens_nonspam')+ log(1 - prob_spam); 特征单词提取
对于自己提取邮件中的特征单词,构成字典,然后按照第二部分利用特征单词的概率对邮件进行分类。
主函数,Naive_Bayes.m
clc;clear
% This file extracts features of emails for judging whether an email is a
% spam or not.
%% Read all text files in cell variable 'data'
data = cell(0);
directory = dir('.');
numberDirect = length(directory);
for n = 3 : numberDirect
files = dir(directory(n).name);
numberFiles = length(files);
for i = 3 : numberFiles
% Be careful the path
fid = fopen(['.\', directory(n).name, '\', files(i).name]);
if (-1 == fid)
fclose(fid);
continue;
end
dataTemp = textscan(fid, '%s', '\n');
fclose(fid);
data = [data; dataTemp{1, 1}];
end
end
%% Sort the data by alphabet.
data = sort(data);
% Count occurrences and delete duplicate words and store in a struct variable.
numberStrings = length(data);
words = struct('strings', {}, 'occurrences', 0);
numberFeature = 1;
occurrences = 1;
for i = 1 : numberStrings - 1
if (strcmp(char(data(i)), char(data(i + 1))))
occurrences = occurrences + 1;
else
words(numberFeature).strings = char(data(i));
words(numberFeature).occurrences = occurrences;
numberFeature = numberFeature + 1;
occurrences = 1;
end
end
words = struct2cell(words);
%% This is only for testing, or you can use
% 'sortrows(cell2mat(words(2, 1, :)))' for getting the 2500 most words.
orders = ones(numberFeature - 1, 1);
for i = 2 : numberFeature - 1
orders(i) = orders(i) + orders(i - 1);
end
features_number = cell2mat(words(2, 1, :));
features_numbers = [features_number(:), orders];
%% Get the 2500 most words to generate dictionary
features_numbers = sortrows(features_numbers);
directionary = words(:, :, features_numbers(:, 2));
directionary = directionary(1, 1, end - 2500 : end - 1);
directionary = sort(directionary(:));
%% calculate features in all folders for trainset and testset
for n = 3 : numberDirect
files = dir(directory(n).name);
numberFiles = length(files);
for i = 3 : numberFiles
fid = fopen(['.\', directory(n).name, '\', files(i).name]);
if (-1 == fid)
fclose(fid);
continue;
end
dataTemp = textscan(fid, '%s', '\n');
fclose(fid);
data = dataTemp{1,1};
feature = find_indexandcount(data, directionary);
docnumber = (i - 2) * ones(size(feature, 1), 1);
featrues = [docnumber, feature];
if (3 == i)
dlmwrite(['.\', directory(n).name, '\', 'features.txt'], featrues, 'delimiter', ' ');
else
dlmwrite(['.\', directory(n).name, '\', 'features.txt'], featrues, '-append', 'delimiter', ' ');
end
end
endfunction result = find_indexandcount(email, dictionary)
% This function computes words' index and count in an email by a dictionary.
numberStrings = length(email);
numberWords = length(dictionary);
count = zeros(length(dictionary), 1);
for i = 1 : numberStrings
count = count + strcmp(email(i), dictionary);
end
% Record order sequence
orders = ones(numberWords, 1);
for i = 2 : length(dictionary) - 1
orders(i) = orders(i) + orders(i - 1);
end
result = sortrows([orders, count], 2);
% Find words which appear more than 1 times
reserve = find(result(:, 2));
result = result(reserve, :);
end
这样就提取了所有邮件的特征单词,构成字典,并根据此字典得出训练邮件和测试邮件中,每一封邮件的特征单词在字典中的位置及出现的次数,这样转到第二步即可对测试邮件分类。下面的test.m 与步骤2的类似,不过需要将各自文件夹下的features.txt 文本文件提取出来并更改名称,放到当前工作目录下。
test.m
% train.m
% Exercise 6: Naive Bayes text classifier
clear all; close all; clc
% store the number of training examples
numTrainDocs = 350;
% store the dictionary size
numTokens = 2500;
% read the features matrix
M0 = dlmread('nonspam_features_train.txt', ' ');
M1 = dlmread('spam_features_train.txt', ' ');
nonspmatrix = sparse(M0(:,1), M0(:,2), M0(:,3), numTrainDocs, numTokens);
nonspamtrain_matrix = full(nonspmatrix);
spmatrix = sparse(M1(:,1), M1(:,2), M1(:,3), numTrainDocs, numTokens);
spamtrain_matrix = full(spmatrix);
% Calculate probability of spam
phi_y = size(spamtrain_matrix, 1) / (size(spamtrain_matrix, 1) + size(nonspamtrain_matrix, 1));
spam_sum = sum(spamtrain_matrix);
nonspam_sum = sum(nonspamtrain_matrix);
% the k-th entry of prob_tokens_spam represents phi_(k|y=1)
phi_k_y1 = (spam_sum + 1) ./ (sum(spam_sum) + numTokens);
% the k-th entry of prob_tokens_nonspam represents phi_(k|y=0)
phi_k_y0 = (nonspam_sum + 1) ./ (sum(nonspam_sum) + numTokens);
% Test set
test_features_spam = dlmread('spam_features_test.txt',' ');
test_features_nonspam = dlmread('nonspam_features_test.txt',' ');
numTestDocs = max(test_features_spam(:,1));
spmatrix = sparse(test_features_spam(:,1), test_features_spam(:,2),test_features_spam(:,3),numTestDocs, numTokens);
nonspmatrix = sparse(test_features_nonspam(:,1), test_features_nonspam(:,2),test_features_nonspam(:,3),numTestDocs,numTokens);
test_matrix = [full(spmatrix); full(nonspmatrix)];
% Calculate probability
prob_spam = log(test_matrix * phi_k_y1') + log(phi_y);
prob_nonspam = log(test_matrix * phi_k_y0') + log(1 - phi_y);
output = prob_spam > prob_nonspam;
% Compute the error on the test set
test_labels = [ones(numTestDocs, 1); zeros(numTestDocs, 1)];
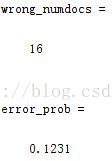
wrong_numdocs = sum(xor(output, test_labels))
%Print out error statistics on the test set
error_prob = wrong_numdocs/numTestDocs
其结果如下:(分类错误的个数及概率)















 1189
1189

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









