






这是「进击的Coder」的第 849 篇技术分享
作者:kingname
来源:未闻 Code
“
阅读本文大概需要 5 分钟。
”写过爬虫的同学都知道,当我们想对 App 或者小程序进行抓包时,最常用的工具是 Charles、Fiddler 或者 MimtProxy。但这些软件用起来非常复杂。特别是当你花了一两个小时把这些软件搞定的时候,别人只用了 15 分钟就已经手动把需要的数据抄写完成了。
我的需求
如果你不是专业的爬虫开发者,那么大多数时候你的抓包需求都是很小的需求,手动操作也不是不能。这种时候,我们最需要的是一种简单快捷的,毫不费力的方法来解放双手。
例如我最近在玩《塞尔达传说——王国之泪》,我有一个小需求,就是想找到防御力最大的帽子、衣服和裤子来混搭。这些数据,在一个叫做『Jump』的 App 上面全都有,如下图所示:
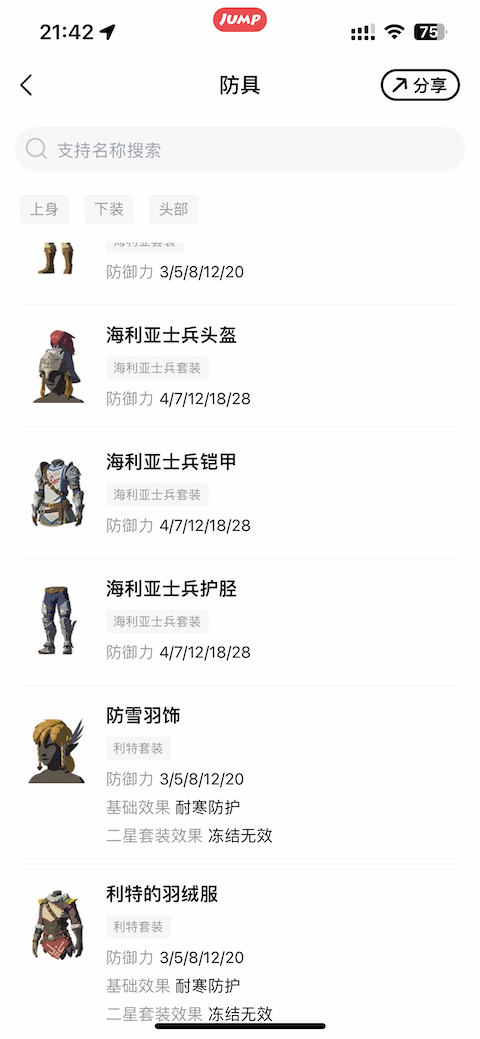
防具总共也就几十个,肉眼一个一个看也没问题,就是费点时间而已。那么,如果我想高效一些,有没有什么简单办法通过抓包再加上 Python 写几行代码来筛选,快速找到我想要的数据呢?
手机上的操作
实际上,方法非常简单。我们只需要在手机上安装一个 App,叫做『Stream』,如下图所示:

这个软件在 App Store 国区就可以下载。
第一次打开这个 App 的时候,我们设置一下根证书,点击下图中箭头指向的这个按钮:
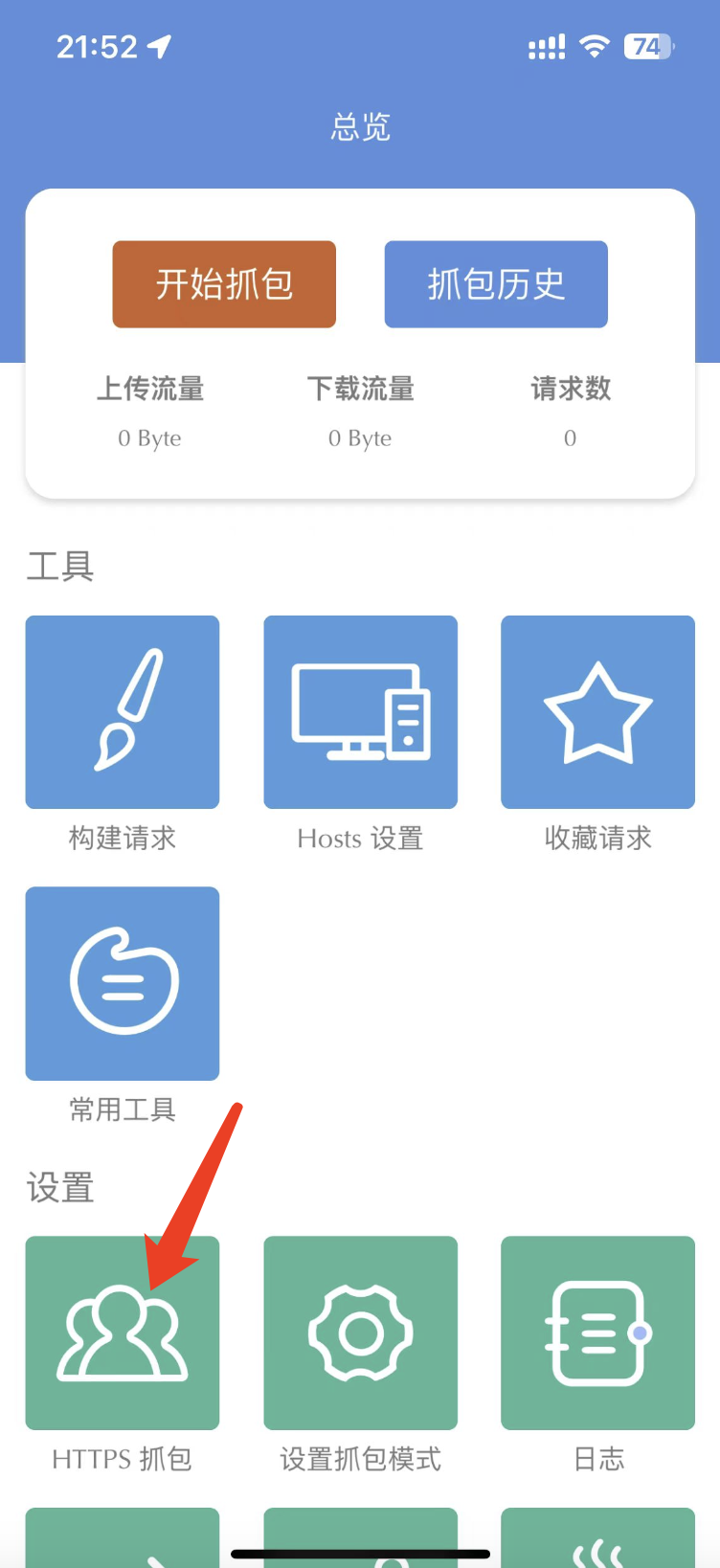
他会一步一步指导你安装根证书。整个过程不超过 30 秒,这里我就不再赘述了。
安装完成根证书以后,我们点击『开始抓包』按钮。此时,手机上面所有的流量就会经过 Stream 并抓取下来。
我们打开 Jump App,找到防具列表,然后不停往下滑动屏幕,直到滑到最下面。
然后回到 Stream,点击『停止抓包』按钮。抓包过程就完成了。
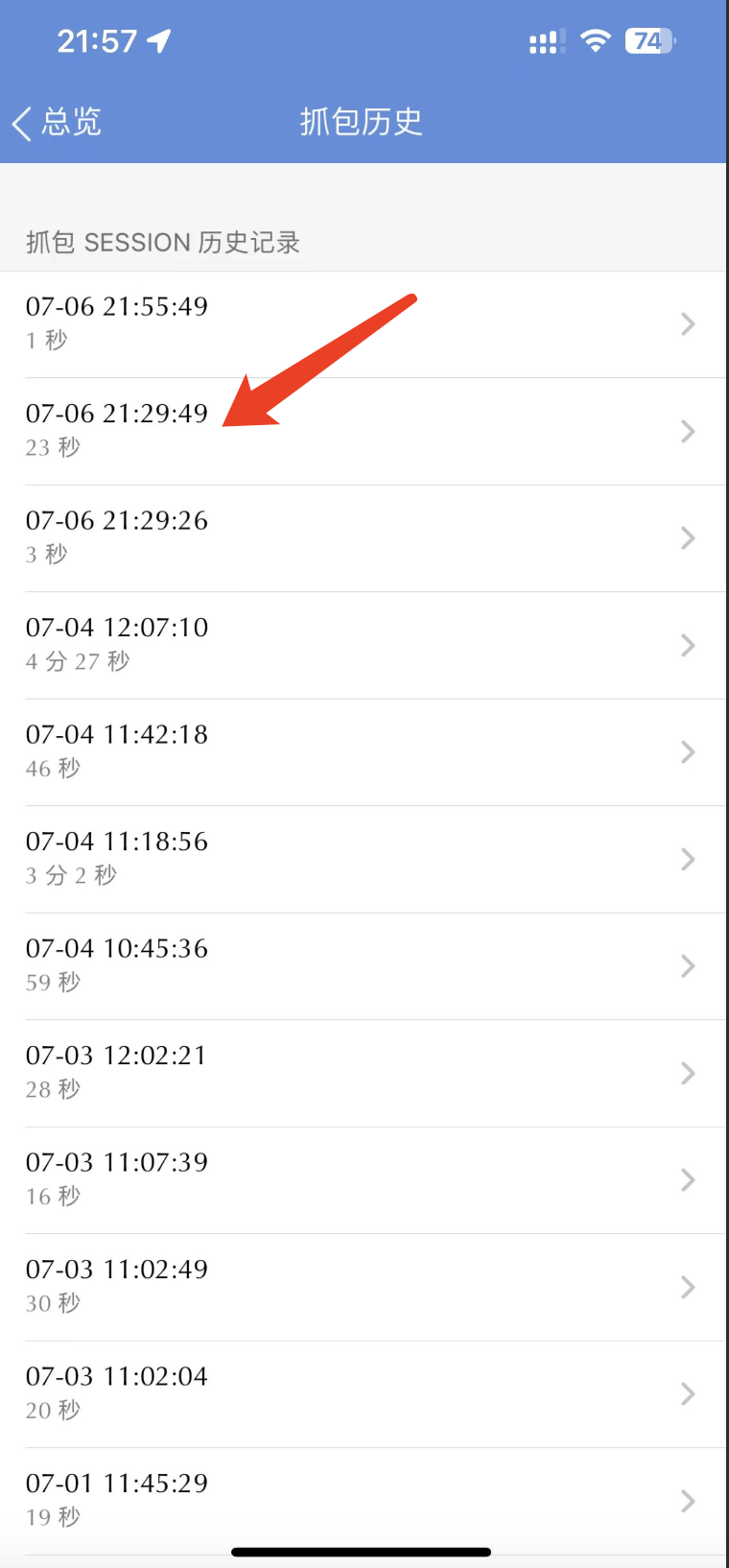
我们点击『抓包历史』按钮,找到刚刚抓到的数据包,如下图所示:
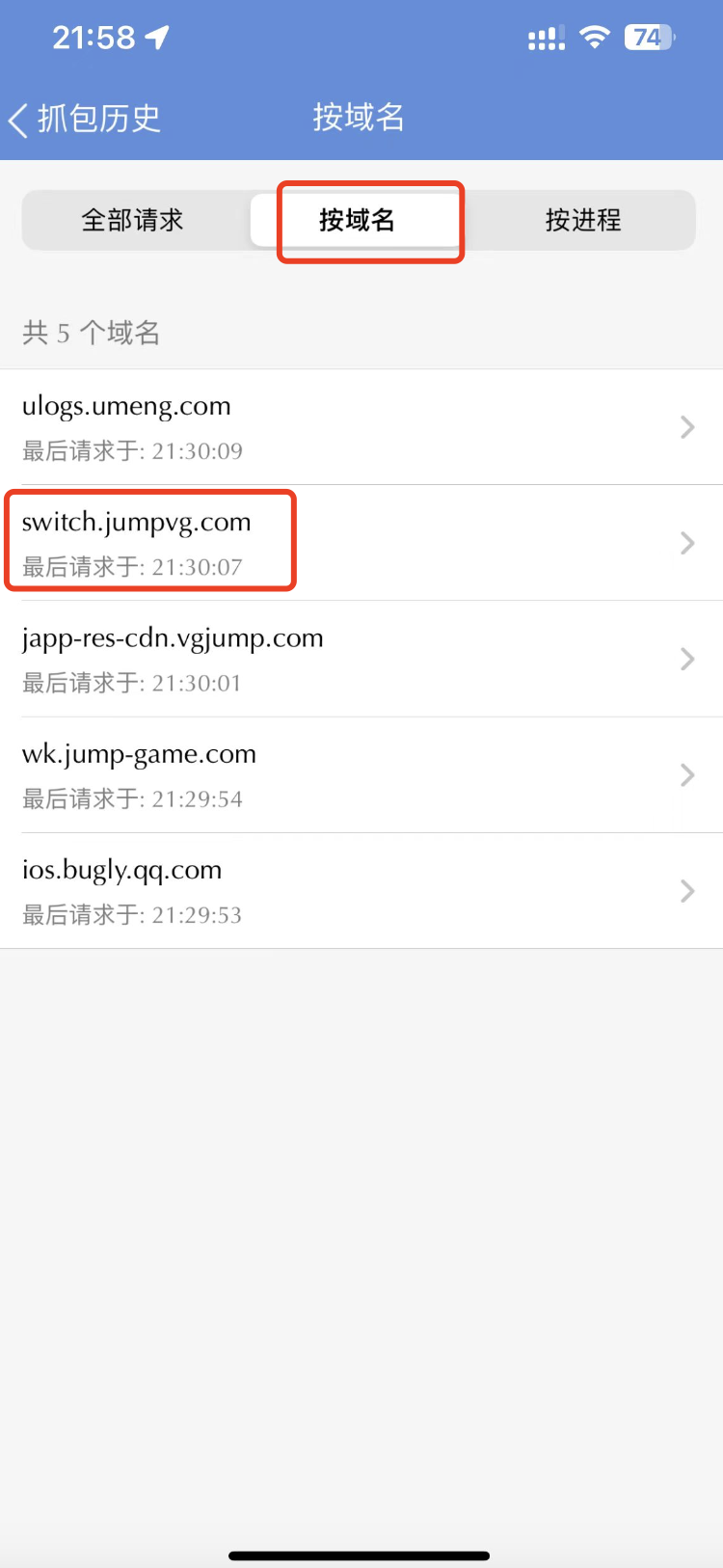
按域名进行筛选,方便找到 Jump App 发送的 HTTP 请求。如下图所示:
打开请求以后,点击『响应』-『查看响应』按钮,如下图所示:
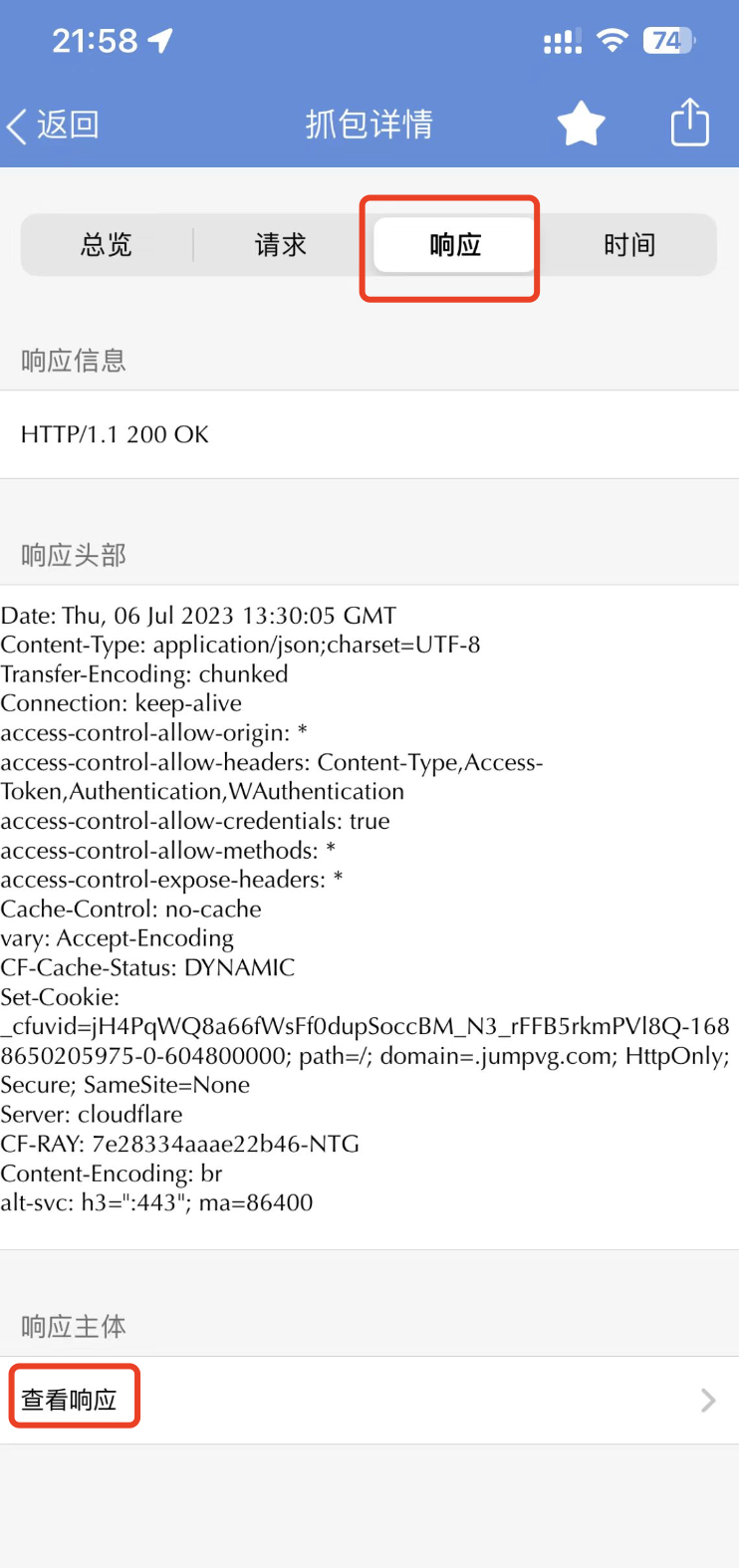
我们就能看到如下图所示请求体,这确实就是防具对应的数据包,如下图所示:

我们现在,需要使用筛选功能,选出所有获取防具信息的后端请求。所以先到『请求选项卡』,查看一下 URL 的规律,如下图所示:
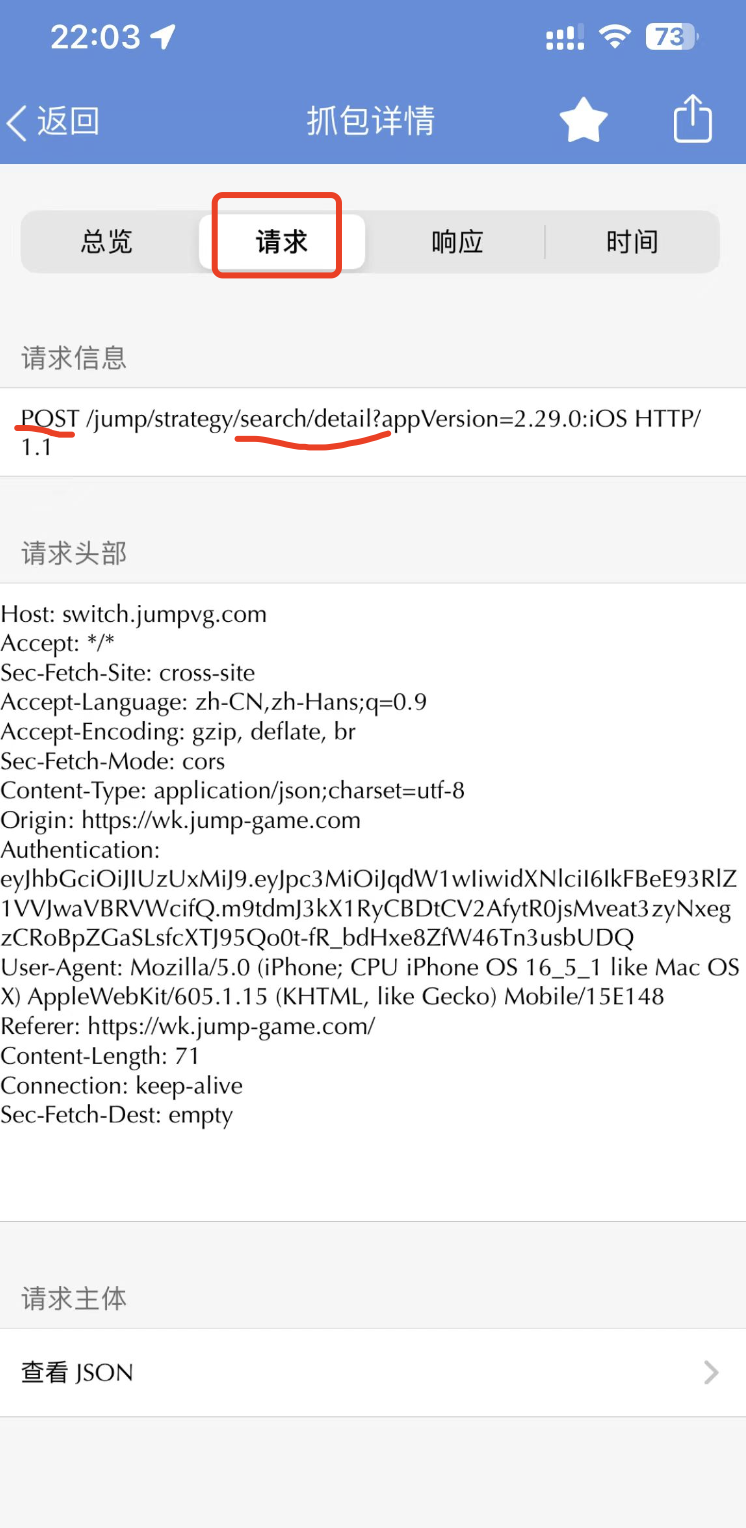
回到请求列表页,点击右上角的放大镜进行筛选,如下图所示:
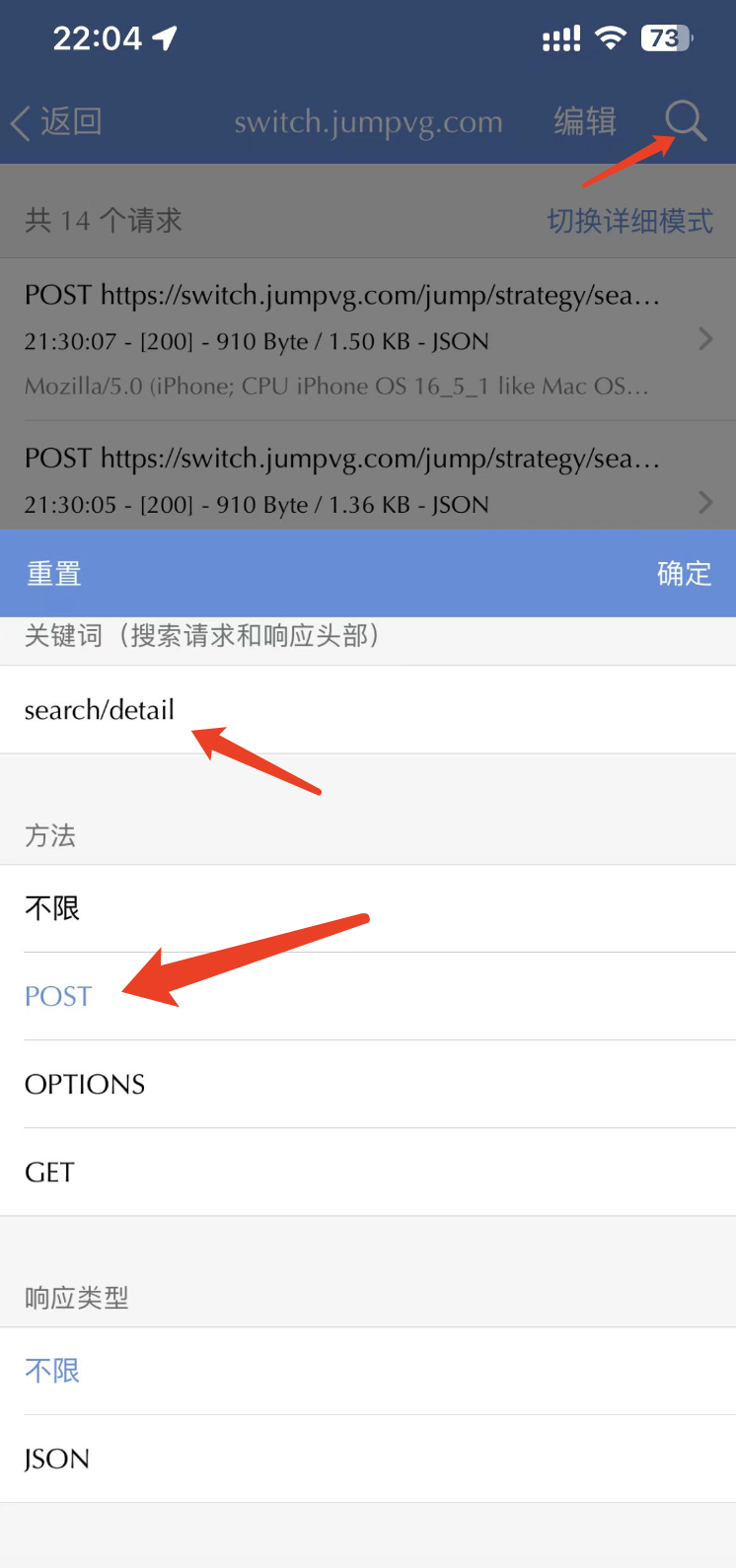
筛选以后,只有 5 个请求了,如下图所示:
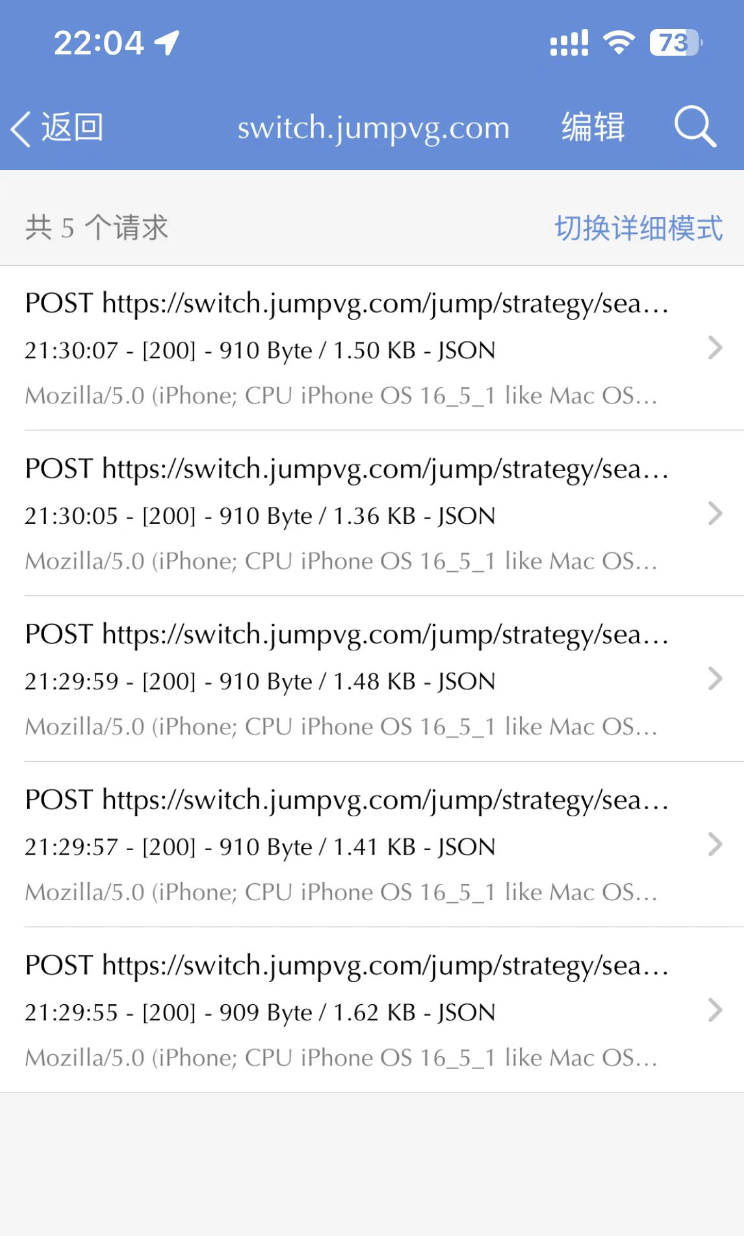
最后一步,我们点击右上角的『编辑』按钮,选中所有请求,并点击右下角的『导出 HAR』,如下图所示:
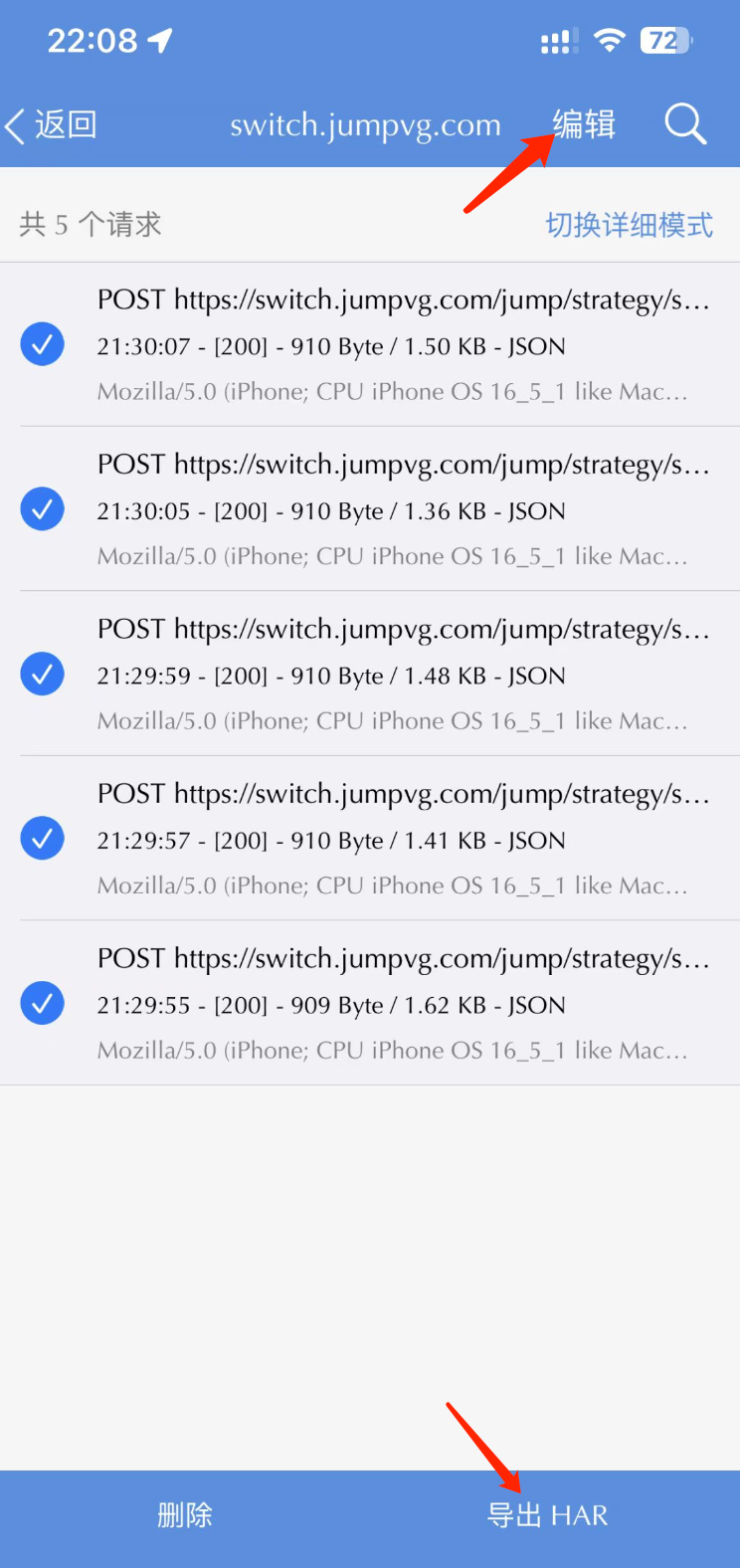
大家可以使用 AirDrop 或者微信发送到电脑上。到此为止,手机上的所有操作就已经结束了。接下来我们来到电脑上,写一段 Python 代码来解析这个 HAR 文件。
写一点点代码
这段代码非常简单,大家可以直接复制:
import json
import brotli
import base64
from haralyzer import HarParser
with open('/Users/kingname/Downloads/Stream-2023-07-06 22:08:44.har') as f:
har_parser = HarParser(json.loads(f.read()))
data = har_parser.har_data
entries = data['entries']
for entry in entries:
text = entry['response']['content']['text']
content = brotli.decompress(base64.b64decode(text)).decode()
info = json.loads(content)
print(info)运行效果如下图所示:
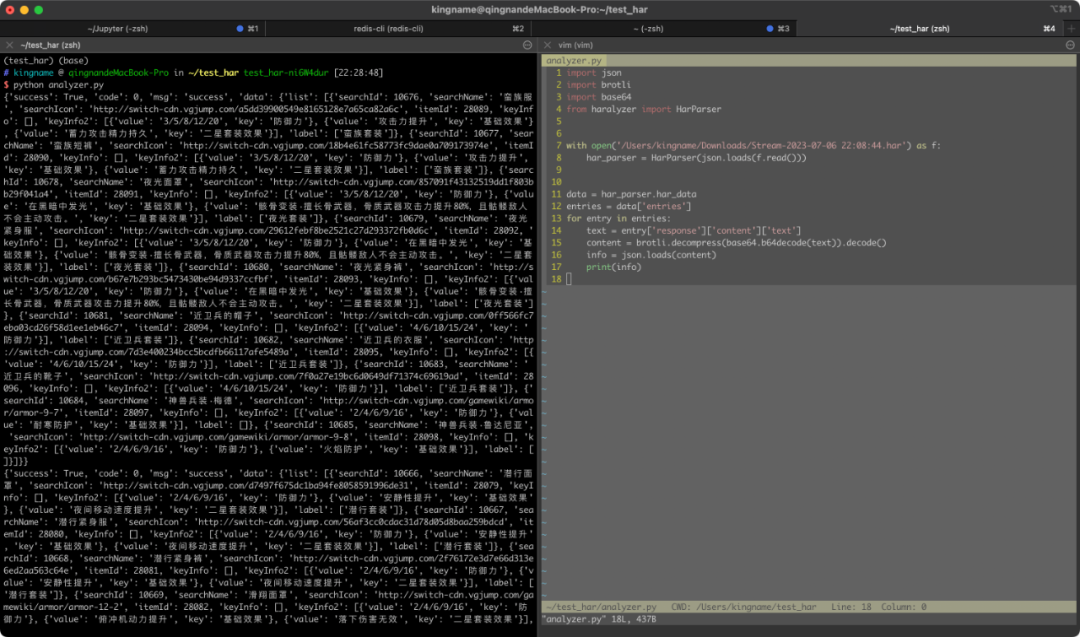
这里我们使用了两个第三方库,分别是haralyzer和brotli。其中的haralyzer是用来解析 HAR 文件;brotli是用来对数据进行解压缩。
在一般情况下,其他网站的 HAR 解析,代码到text = entry['response']['content']['text']就可以了。返回的text直接就是人眼可读的内容了。但 Jump 稍微特殊一些,因为它返回的内容经过压缩,所以获取到的是 Base64 字符串。如果我们直接打印,就会看到:
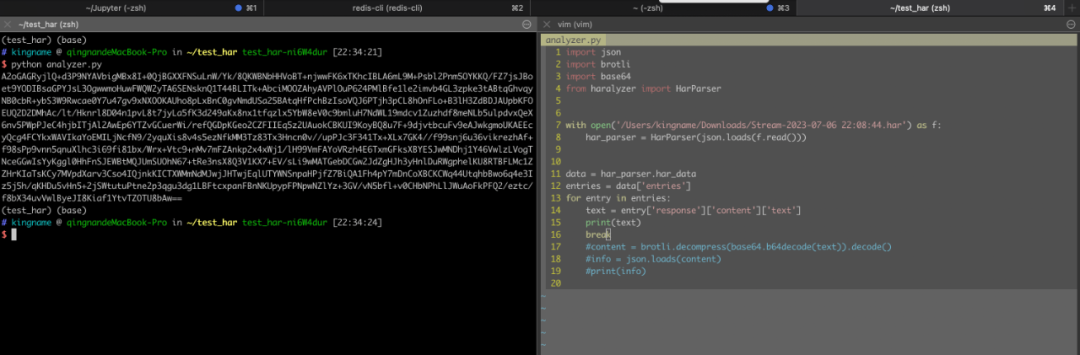
这个 Base64 不能直接解码,因为解了以后是二进制信息。从之前 Stream 的响应 Headers 里面,我们可以看到这个数据是经过br压缩的,如下图所示:
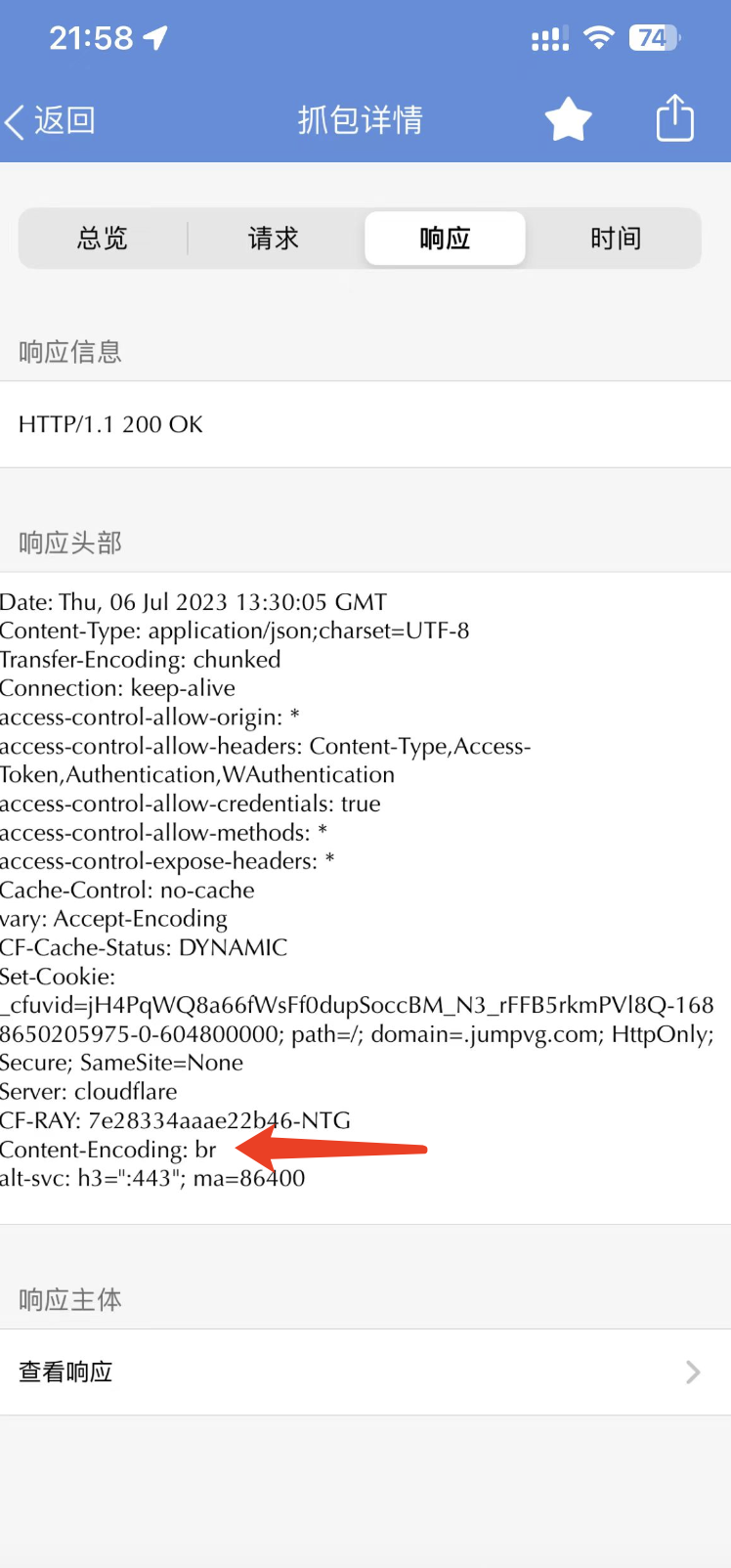
所以需要使用brotli解压缩:brotli.decompress(base64.b64decode(text)).decode()。
现在你已经拿到返回数据的 JSON 信息了。那么接下来要对数据进行怎么样的处理,都不再是问题了。
总结
安装 Stream 并设置根证书
打开抓包功能
打开目标 App 或者微信小程序,让流量经过 Stream
关闭抓包功能,从抓包历史里面找到目标请求的 URL 规则
筛选出所有需要的请求,导出为 HAR 文件
使用 Python 解析 HAR 文件
当你熟练以后,整个过程不超过 3 分钟就能完成。

End
欢迎大家加入【ChatGPT&AI 变现圈】,零门槛掌握 AI 神器!我们带你从小白到高手,解锁智能问答、自动化创作、技术变现的无限可能。与我们共同成长,开启 AI 新征程!立即行动,未来已来!(详情请戳:知识星球:ChatGPT&AI 变现圈,正式上线!)
扫码加入:

好文和朋友一起看~















 1998
1998











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









