







听说高大上的spark2.0版本发布啦,凑个热闹来安装一下。
本文安装方式及教程截图均基于ubuntu 14.04系统
需要下载以下4个软件:
说明:自己尝试发现手动下载这些软件的压缩包再解压到某目录下的方式比命令行稍快一点,后面也有命令行下载方式的说明。此种方式适用于习惯图形界面的童鞋。
1.Hadoop-2.7.2.tar.gz 下载网址:
http://www-eu.apache.org/dist/hadoop/common/hadoop-2.7.2/hadoop-2.7.2.tar.gz
2.scala-2.11.8.tgz 下载网址:
http://downloads.lightbend.com/scala/2.11.8/scala-2.11.8.tgz
3.spark-2.0.0-bin-hadoop2.7.tgz 下载网址:
http://spark.apache.org/downloads.html
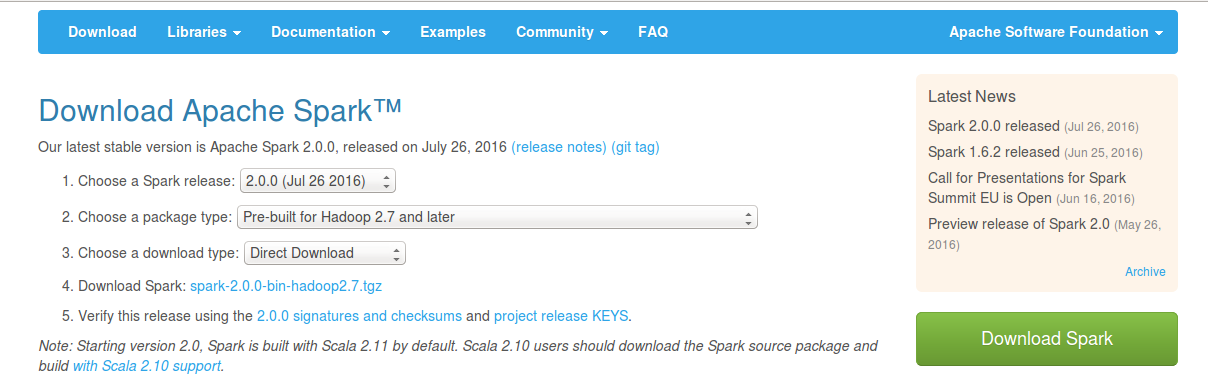
4.java下载网址:
http://download.oracle.com/otn-pub/java/jdk/8u101-b13/jdk-8u101-linux-x64.tar.gz
一.安装java
将java下载后手动解压到/home/che文件夹下(可采用右击压缩包,单击“提取”)
在终端(可用Ctrl+Alt+T快捷键打开)中输入:
sudo gedit /etc/profile在打开的文本中添加:
export JAVA_HOME=/home/che/jdk1.8.0_101/
export JRE_HOME=/home/che/jdk1.8.0_101/jre
export PATH=$JAVA_HOME/bin:$JRE_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib:$JRE_HOME/lib:$CLASSPATH二.配置ssh localhost
确保安装好ssh:
sudo apt-get update
sudo apt-get install openssh-server
sudo /etc/init.d/ssh start生成并添加密钥:
ssh-keygen -t rsa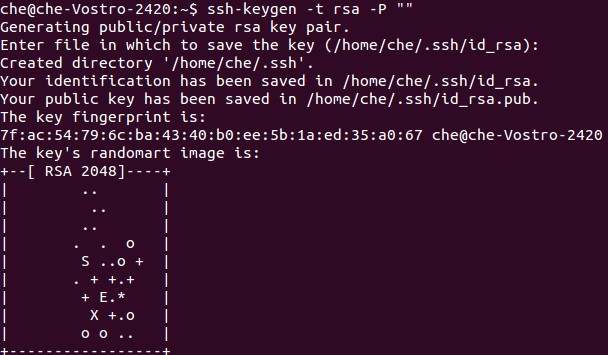
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
chmod 0600 ~/.ssh/authorized_keys测试ssh localhost
ssh localhost
exit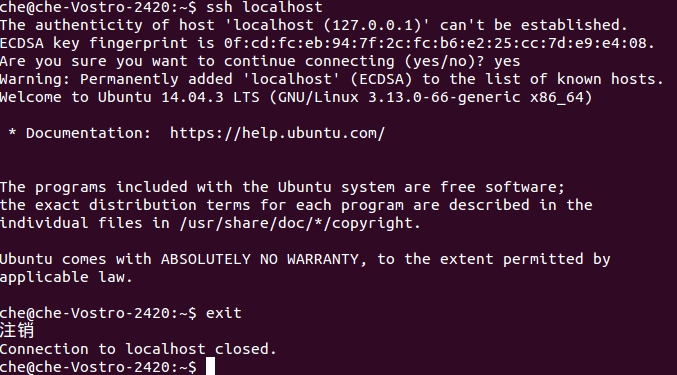
三.安装hadoop2.6.0
将hadoop2.6.0下载然后手动解压到/home/che文件夹下
【或者】执行:
cd /home/che
wget http://www-eu.apache.org/dist/hadoop/common/hadoop-2.7.2/hadoop-2.7.2.tar.gz
tar -xzvf hadoop-2.7.2.tar.gz编辑/etc/profile文件
sudo gedit /etc/profile添加:
export HADOOP_HOME=/home/che/hadoop-2.7.2
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin让其生效
source /etc/profile编辑$HADOOP_HOME/etc/hadoop/hadoop-env.sh文件
sudo gedit $HADOOP_HOME/etc/hadoop/hadoop-env.sh添加:
export JAVA_HOME=/home/che/jdk1.8.0_101/修改core-site.xml文件
cd $HADOOP_HOME/etc/hadoop
sudo gedit core-site.xml修改为:
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>修改hdfs-site.xml文件
sudo gedit hdfs-site.xml修改为(第一个是dfs的备份数目,单机用1份就行,后面两个是namenode和datanode的目录):
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>file:///home/che/hadoopdata/hdfs/namenode</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>file:///home/che/hadoopdata/hdfs/datanode</value>
</property>
</configuration>修改mapred-site.xml.template
sudo gedit mapred-site.xml.template修改为:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>修改yarn-site.xml
sudo gedit yarn-site.xml修改为:
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>初始化hadoop:
hdfs namenode -format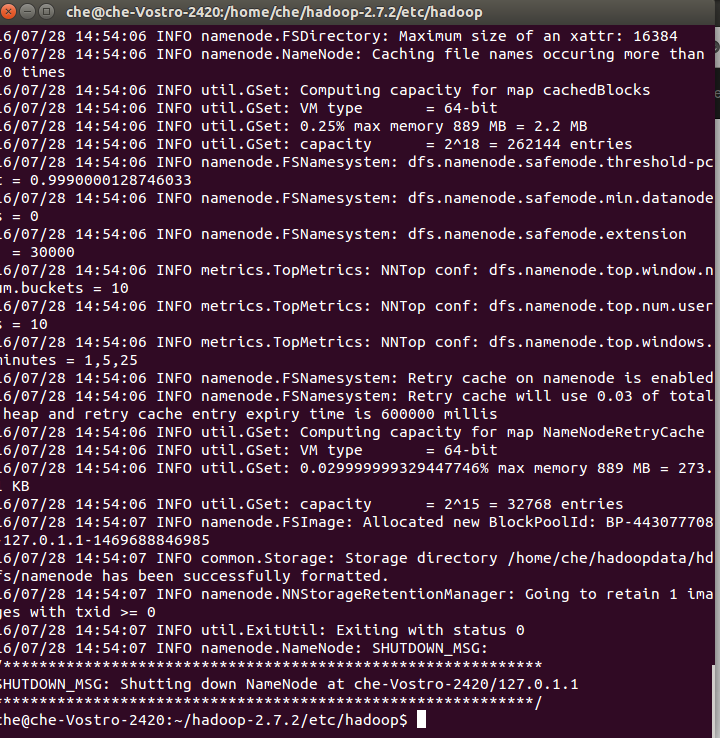
启动
$HADOOP_HOME/sbin/start-all.sh停止
$HADOOP_HOME/sbin/stop-all.sh检查WebUI,浏览器打开端口8088:http://localhost:8088
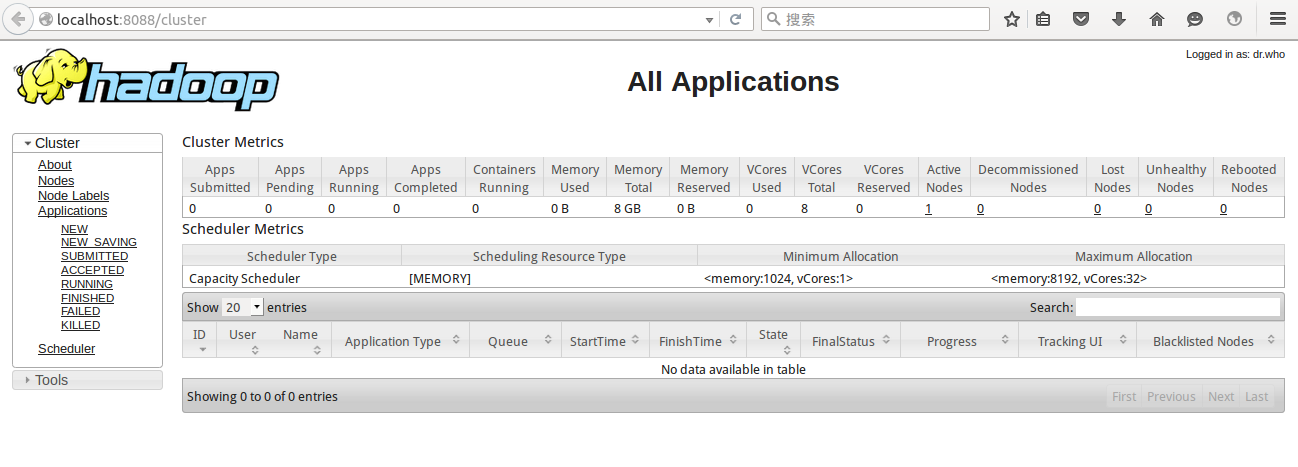
其他端口说明:
port 8088: cluster and all applications
port 50070: Hadoop NameNode
port 50090: Secondary NameNode
port 50075: DataNode
hadoop运行后可使用jps命令查看,得到结果:
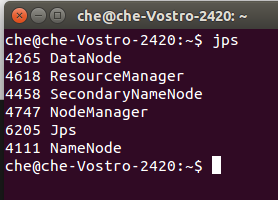
四.安装scala
将scala下载后手动解压文件到/home/che文件夹
【或者】执行:
cd /home/che
tar -xzvf scala-2.11.8.tgz在/etc/profile文件的末尾添加环境变量:
sudo gedit /etc/profile添加:
export SCALA_HOME=/home/che/scala-2.11.8
export PATH=$SCALA_HOME/bin:$PATH保存并更新/etc/profile:
source /etc/profile查看是否成功:
scala -version
五.安装spark
下载spark手动解压安装包到/home/che文件夹下
【或者】执行:
cd /home/che
tar -xzvf spark-2.0.0-bin-hadoop2.7.tgz
mv spark-2.0.0-bin-hadoop2.7 spark-2.0.0打开/etc/profile文件
sudo gedit /etc/profile在/etc/profile文件的末尾添加环境变量:
export SPARK_HOME=/home/che/spark-2.0.0
export PATH=$SPARK_HOME/bin:$PATH保存并更新/etc/profile:
source /etc/profile在conf目录下复制并重命名spark-env.sh.template为spark-env.sh:
cd $SPARK_HOME/conf
cp spark-env.sh.template spark-env.sh
sudo gedit spark-env.sh添加:
export JAVA_HOME=/home/che/jdk1.8.0_101
export SCALA_HOME=/home/che/scala-2.11.9
export SPARK_MASTER_IP=master
export SPARK_WORKER_MEMORY=4G启动spark
$SPARK_HOME/sbin/start-all.sh
jps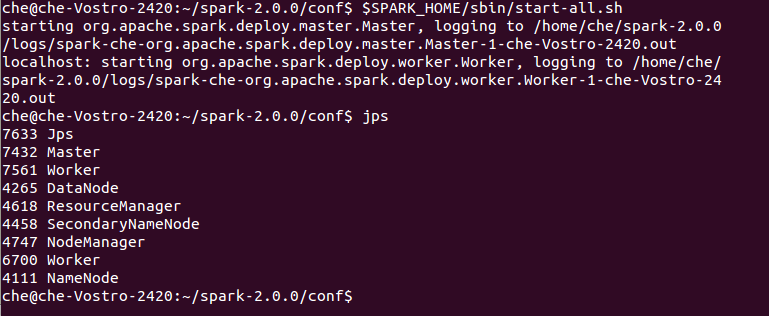
可以打开http://localhost:8080/看worker情况(只有启动之后才能看到)
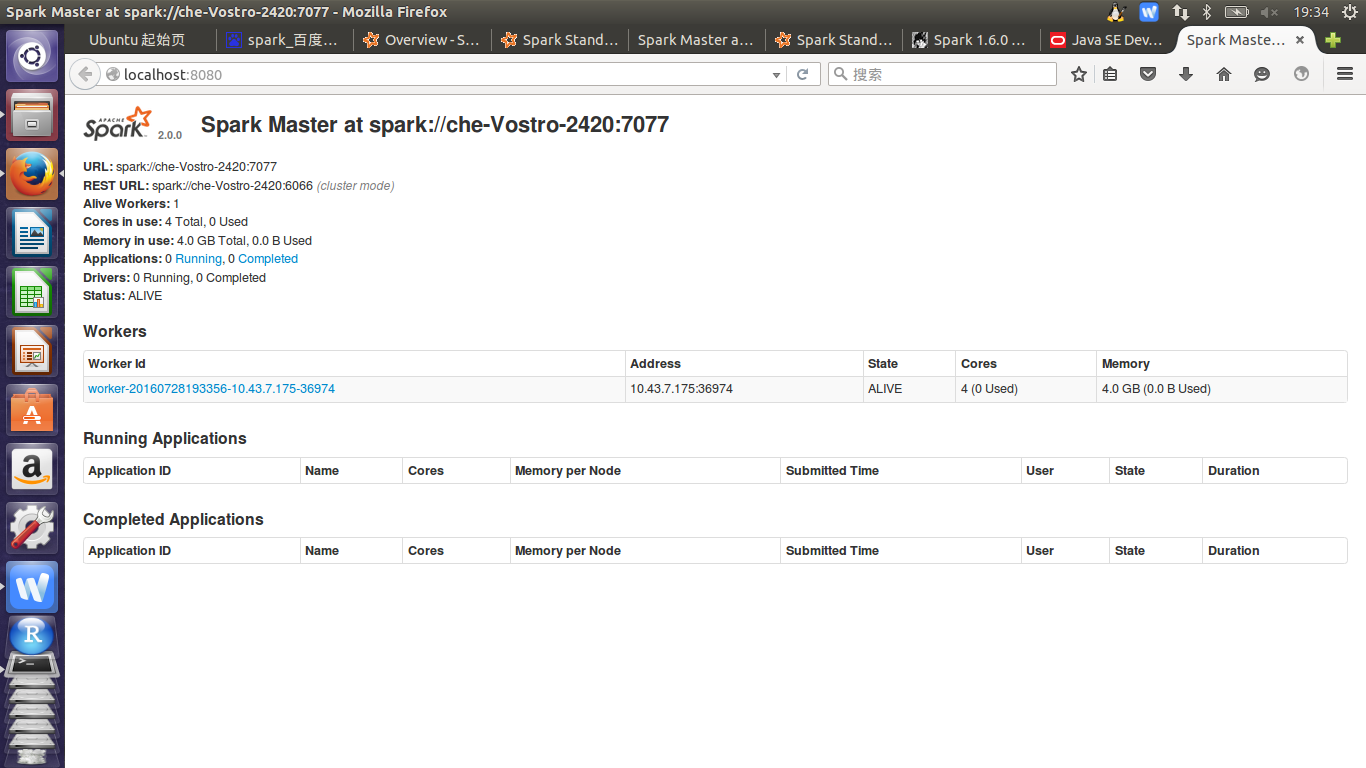
可以看到有一个worker,现在就可以愉快的玩耍spark啦!!!
$SPARK_HOME/bin/run-example SparkPi看看你有没有得到:
Pi is roughly 3.14716(当时运行出来一大串代码,最后找了半天这个结果在代码中间隐藏着)
参考网址:
http://blog.tomgou.xyz/spark-160-dan-ji-an-zhuang-pei-zhi.html
http://blog.csdn.net/stark_summer/article/details/43495623
转载请注明文章来源及作者:会飞的星星















 1434
1434











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









