





spark中的DataFrame和RDD对于初学者来说是很容易产生混淆的概念。下面内容是berkeley的spark课程学习笔记,记录了
DataFrame与RDD的相同点及区别。
首先看一下官网的解释:
DataFrame:在Spark中,DataFrame是一个以命名列方式组织的分布式数据集,等同于关系型数据库中的一个表,也相当于R/Python中的data frames(但是进行了更多的优化)。
RDD:rdd是一个分布式的数据集,数据分散在分布式集群的各台机器上。
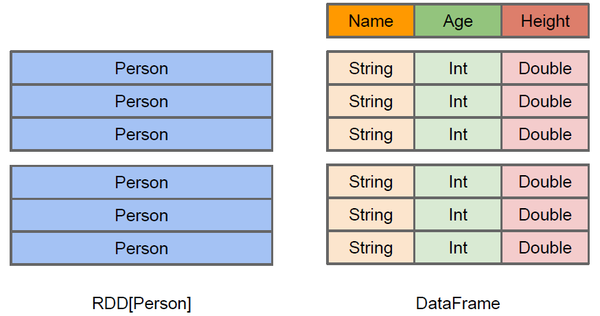
下图直观的标示了两者结构上的区别左侧的RDD[Person]虽然以Person为类型参数,但Spark框架本身不了解Person类的内部结构。而右侧的DataFrame却提供了详细的结构信息,使得Spark SQL可以清楚地知道该数据集中包含哪些列,每列的名称和类型各是什么。DataFrame多了数据的结构信息,即schema。
一、相同点
1. 创建后不能修改:spark
强调不变性,在大部分场景下倾向于创建新对象而不是修改老对象。
2. 通过查看数据操作记录可以高效地对丢失的数据进行重新计算
。
3. 支持对分布式数据的操作。
4.DataFrame和RDD都可以由以下数据源创建:
(1)分布式存储的python数据集。
(2)pandas中的DataFrame或者其他spark数据集。
(3)HDFS或者其他文件系统中的文件。
5.DataFrame和RDD都有两种操作类型:tranformations和actions。
二、区别
RDD可以通过编程设置数据集的分区块数量(没有设置时使用默认值,默认值就是程序所分配到的CPU Core的数目。)
更多的分区意味着更好的分布性。
DataFrame的优势
spark对于DataFrame在执行时间和内存使用上相对于RDD有极大的优化。
- Catalyst Optimization Engine 减少了DataFrame75%的执行时间。
- Project Tungsten off-heap menory management减少了75%的内存使用。
Catalyst Optimization Engine

图中右上角表示的是分别以用python、scala执行RDD和DataFrame聚合10 million整型对用的时间。
我们可以看到,使用python及scala执行RDD的速度明显比DataFrame慢。
在执行RDD时,scala比Python快。但对于DataFrame,两种语言没有区别。
这是因为python是解释型语言,scala是编译型语言。
在绿色部分,为了更好地执行,Catalyst将Scala和Python的DataFrame操作
编译为物理计划,并生成了JVM bytecode,所以python没有解释过程。
导致这两种语言在性能上基本有着同样的表现。同时,两者性能均优于普通Python RDD实现的4倍,也达到了Scala RDD实现的两倍
。
左下角的表显示Catalyst 优化的效果,经过Catalyst优化后的代码比解释型代码明显快了很多,并且于人工编码速度差不多。
Project Tungsten off-heap menory management

上图中右上角绿色部分是使用DataFrame所占用的内存空间,比RDD少了四分之三。
左下角则显示了Tungsten优化的结果。
上文提到了DataFrame在时间和空间上对于RDD的优势明显,那我们应该怎样选择DataFrame和RDD。
1. 何时使用DataFrame
- 结构化或半结构化数据
- 对数据进行的操作,如transformations和actions较多。
- 需要更快的执行速度、更少的执行空间
2. 何时使用RDD
- 非结构化的数据,如音视频媒体,文本数据流。
- 对数据需要进行的操作较少。
- 希望用函数式编程结构的方式对数据进行处理。















 192
192

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









