







一、查看NUMA配置命令
apt install numactl
numactl --hardware
numactl --show
numastat
lscpu
1. 执行 numactl --hardware 可以查看硬件对 NUMA 的支持信息。
- available: 1 nodes (0) #如果是2或多个nodes就说明numa没关掉
- CPU 被分成 node 0 和 node 1 两组(这台机器有两个 CPU Socket)。
- 每组 CPU 分配到 96 GB 的内存(这台机器总共有 192GB 内存)。
- node distances 是一个二维矩阵,node[i][j] 表示 node i 访问 node j 的内存的相对距离。比如 node 0 访问 node 0 的内存的距离是 10,而 node 0 访问 node 1 的内存的距离是 21。
numactl --hardware
available: 2 nodes (0-1)
node 0 cpus: 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71
node 0 size: 96920 MB
node 0 free: 2951 MB
node 1 cpus: 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95
node 1 size: 98304 MB
node 1 free: 33 MB node
distances:
node 0 1
0: 10 21
1: 21 10
2. 执行 numactl --show 显示当前的 NUMA 设置:
numactl --show
policy: default
preferred node: current
physcpubind: 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95
cpubind: 0 1
nodebind: 0 1
membind: 0 1
3. 执行numastat显示当前NUMA状态:
- numa_hit—命中的,也就是为这个节点成功分配本地内存访问的内存大小
- numa_miss—把内存访问分配到另一个node节点的内存大小,这个值和另一个node的numa_foreign相对应。
- numa_foreign–另一个Node访问我的内存大小,与对方node的numa_miss相对应
- local_node----这个节点的进程成功在这个节点上分配内存访问的大小
- other_node----这个节点的进程在其它节点上分配的内存访问大小 很明显,miss值和foreign值越高,就要考虑绑定的问题。
liujianguo@ubuntu:/proc/sys/kernel$ numastat
node0 node1 node2 node3
numa_hit 94328451 85523289 122460802 85462040
numa_miss 20270299 32210555 9373343 42488746
numa_foreign 15753535 5349284 65561480 17678644
interleave_hit 19857 19773 19847 19770
local_node 94298512 85477081 122411609 85415471
other_node 20300238 32256763 9422536 42535315
观察整机是否有很多 other_node 指标(远端内存访问)上涨:
watch -n 1 numastat -s
查看单个进程在各个node上的内存分配情况:
numastat -p
4. numactl 命令其他几个重要选项:
- –cpubind=0: 绑定到 node 0 的 CPU 上执行。
- –membind=1: 只在 node 1 上分配内存。
- –interleave=nodes:nodes 可以是 all、N,N,N 或 N-N,表示在 nodes 上轮循(round robin)分配内存。
- –physcpubind=cpus:cpus 是 /proc/cpuinfo 中的 processor(超线程) 字段,cpus 的格式与 --interleave=nodes 一样,表示绑定到 cpus 上运行。
- –preferred=1: 优先考虑从 node 1 上分配内存。
NUMA的内存分配策略有localalloc、preferred、membind、interleave。 NUMA默认的内存分配策略是优先在进程所在CPU的本地内存中分配,会导致CPU节点之间内存分配不均衡,当某个CPU节点的内存不足时,会导致swap产生,而不是从远程节点分配内存。这就是所谓的swap insanity 现象(来源:NUMA perf)。
- localalloc规定进程从当前node上请求分配内存;
- preferred比较宽松地指定了一个推荐的node来获取内存,如果被推荐的node上没有足够内存,进程可以尝试别的node。
- membind可以指定若干个node,进程只能从这些指定的node上请求分配内存。
- interleave规定进程从指定的若干个node上以RR(Round Robin 轮询调度)算法交织地请求分配内存。
NUMA的分配策略例子
# Unset default cpuset awareness.
numactl --all
# Run ${process} on node 0 with memory allocated on node 0 and 1.
numactl --cpunodebind=0 --membind=0,1 ${process} ${process_arguments}
# Run ${process} on cpus 0-4 and 8-12 of the current cpuset.
numactl --physcpubind=+0-4,8-12 ${process} ${process_arguments}
# Run ${process} with its memory interleaved on all CPUs
numactl --interleave=all ${process} ${process_arguments}
# Run process as above, but with an option (-l) that would be confused with a numactl option.
numactl --cpunodebind=0 --membind=0,1 -- ${process} -l
# Run ${network-server} on the node of network device eth0 with its memory also in the same node.
numactl --cpunodebind=netdev:eth0 --membind=netdev:eth0 ${network-server}
# Set preferred node 1 and show the resulting state.
numactl --preferred=1 numactl --show
# Interleave all of the sysv shared memory region specified by /tmp/shmkey over all nodes.
numactl --interleave=all --shm /tmp/shmkey
# Place a tmpfs file on 2 nodes.
numactl --membind=2 dd if=/dev/zero of=/dev/shm/A bs=1M count=1024
numactl --membind=3 dd if=/dev/zero of=/dev/shm/A seek=1024 bs=1M count=1024
# Reset the policy for the shared memory file file to the default localalloc policy.
numactl --localalloc /dev/shm/file
5. numactl -H显示当前各个节点内存占用情况
liujianguo@ubuntu:~/MyTestForAutoNUMA/Experiment_I_OFF$ numactl -H
available: 4 nodes (0-3)
node 0 cpus: 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23
node 0 size: 31915 MB
node 0 free: 26268 MB
node 1 cpus: 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47
node 1 size: 32252 MB
node 1 free: 30522 MB
node 2 cpus: 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71
node 2 size: 32252 MB
node 2 free: 26567 MB
node 3 cpus: 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95
node 3 size: 31973 MB
node 3 free: 30587 MB
node distances:
node 0 1 2 3
0: 10 12 20 22
1: 12 10 22 24
2: 20 22 10 12
3: 22 24 12 10
6. 执行lscpu命令来显示cpu的相关信息:
- lscpu从sysfs和/proc/cpuinfo收集cpu体系结构信息,命令的输出比较易读
- 命令输出的信息包含cpu数量,线程,核数,套接字和Nom-Uniform Memeor Access(NUMA),缓存等
- 不是所有的列都支持所有的架构,如果指定了不支持的列,那么lscpu将打印列,但不显示数据
语法:
lscpu [-a|-b|-c] [-x] [-s directory] [-e [=list]|-p [=list]]
lscpu -h|-V
参数选项:
- -a, –all: 包含上线和下线的cpu的数量,此选项只能与选项e或-p一起指定
- -b, –online: 只显示出上线的cpu数量,此选项只能与选项e或者-p一起指定
- -c, –offline: 只显示出离线的cpu数量,此选项只能与选项e或者-p一起指定
- -e, –extended [=list]: 以人性化的格式显示cpu信息,如果list参数省略,输出所有可用数据的列,在指定了list参数时,选项的字符串、等号(=)和列表必须不包含任何空格或其他空白。比如:’-e=cpu,node’ or ’–extended=cpu,node’
- -h, –help:帮助
- -p, –parse [=list]: 优化命令输出,便于分析.如果省略list,则命令的输出与早期版本的lscpu兼容,兼容格式以两个逗号用于分隔cpu缓存列,如果没有发现cpu缓存,则省略缓存列,如果使用list参数,则缓存列以冒号(:)分隔。在指定了list参数时,选项的字符串、等号(=)和列表必须不包含空格或者其它空白。比如:’-e=cpu,node’ or ’–extended=cpu,node’
- -s, –sysroot directory: 为一个Linux实例收集CPU数据,而不是发出lscpu命令的实例。指定的目录是要检查Linux实例的系统根
- -x, –hex:使用十六进制来表示cpu集合,默认情况是打印列表格式的集合(例如:0,1)
显示格式:
- Architecture: #架构
- CPU(s): #逻辑cpu颗数
- Thread(s) per core: #每个核心线程
- Core(s) per socket: #每个cpu插槽核数/每个物理cpu核数
- CPU socket(s): #cpu插槽数 ,物理CPU个数
- Vendor ID: #cpu厂商ID
- CPU family: #cpu系列
- Model: #型号
- Stepping: #步进
- CPU MHz: #cpu主频
- Virtualization: #cpu支持的虚拟化技术
- L1d cache: #一级缓存(google了下,这具体表示表示cpu的L1数据缓存)
- L1i cache: #一级缓存(具体为L1指令缓存)
- L2 cache: #二级缓存
二、Linux Kernel对NUMA内存的使用
实际我们使用NUMA的时候期望是:优先使用本NUMA上的内存,如果本NUMA不够了不要优先回收PageCache而是优先使用其它NUMA上的内存。
1. zone_reclaim_mode
事实上Linux识别到NUMA架构后,默认的内存分配方案就是:优先尝试在请求线程当前所处的CPU的Local内存上分配空间。如果local内存不足,优先淘汰local内存中无用的Page(Inactive,Unmapped)。然后才到其它NUMA上分配内存。
intel 芯片跨node延迟远低于其他家,所以跨node性能损耗不大
zone_reclaim_mode,它用来管理当一个内存区域(zone)内部的内存耗尽时,是从其内部进行内存回收还是可以从其他zone进行回收的选项:
zone_reclaim_mode:
Zone_reclaim_mode allows someone to set more or less aggressive approaches to
reclaim memory when a zone runs out of memory. If it is set to zero then no
zone reclaim occurs. Allocations will be satisfied from other zones / nodes
in the system.
zone_reclaim_mode的四个参数值的意义分别是:
- 0 = Allocate from all nodes before reclaiming memory(其值默认为 0,表示从其他 node/zone 分配)
- 1 = Reclaim memory from local node vs allocating from next node(如果该值设为 1,虽然会回收,也尽量选用轻量级的方式,即只回收 unmmaped 的 page cache 页面(unmapped 的页面是指没有被进程页表映射的 page frame,这样的页面在 reclaim 时不需要通过 reserve mapping 解除映射关系,回收最为迅速,所以保持一定比例的 unmapped 页面是有必要的,这又引出另一个内核配置参数,即 “/proc/sys/vm/min_unmapped_ratio”(默认为 1%)))
- 2 = Zone reclaim writes dirty pages out(如果为 2,则可以回收造成开销更大的,需要 writeback 的页面。)
- 4 = Zone reclaim swaps pages(为 4 的话,那么需要 swap 操作的匿名页面也会被包含。)
可以使用以下命令查看当前zone_reclaim_mode配置:
# cat /proc/sys/vm/zone_reclaim_mode
0
可以使用如下方法对zone_reclaim_mode进行修改:
echo 0 > /proc/sys/vm/zone_reclaim_mode
或
sysctl -w vm.zone_reclaim_mode=0
或编辑/etc/sysctl.conf 文件,加入vm.zone_reclaim_mode=0
我查了2.6.32以及4.19.91内核的机器 zone_reclaim_mode 都是默认0 ,也就是kernel会:优先使用本NUMA上的内存,如果本NUMA不够了不要优先回收PageCache而是优先使用其它NUMA上的内存。这也是我们想要的
Kernel文档也告诉大家默认就是0,但是为什么会出现优先回收了PageCache呢?
2. 查看kernel提交记录
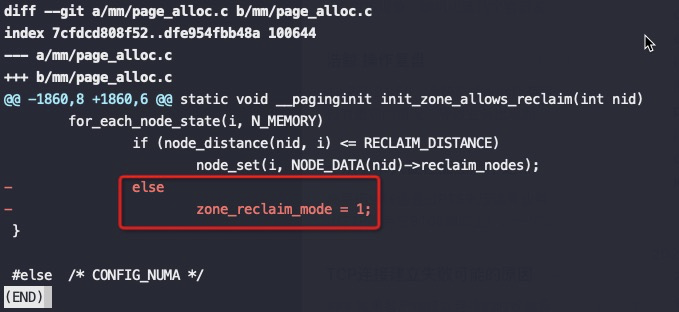
关键是上图红框中的代码,node distance比较大(也就是开启了NUMA的话),强制将 zone_reclaim_mode设为1,这是2014年提交的代码,将这个强制设为1的逻辑去掉了。
这也就是为什么之前大佬们碰到NUMA问题后尝试修改 zone_reclaim_mode 没有效果,也就是2014年前只要开启了NUMA就强制线回收PageCache,即使设置zone_reclaim_mode也没有意义,真是个可怕的Bug。
3. 验证一下zone_reclaim_mode 0是生效的
内核版本:3.10.0-327.ali2017.alios7.x86_64
3.1 测试方法
先将一个160G的文件加载到内存里,然后再用代码分配64G的内存出来使用。
单个NUMA node的内存为256G,本身用掉了60G,加上这次的160G的PageCache,和之前的一些其他PageCache,总的 PageCache用了179G,那么这个node总内存还剩256G-60G-179G,
如果这个时候再分配64G内存的话,本node肯定不够了,我们来看在 zone_reclaim_mode=0 的时候是优先回收PageCache还是分配了到另外一个NUMA node(这个NUMA node 有240G以上的内存空闲)
3.2 测试过程
分配64G内存
#taskset -c 0 ./alloc 64
To allocate 64GB memory
Used time: 39 seconds
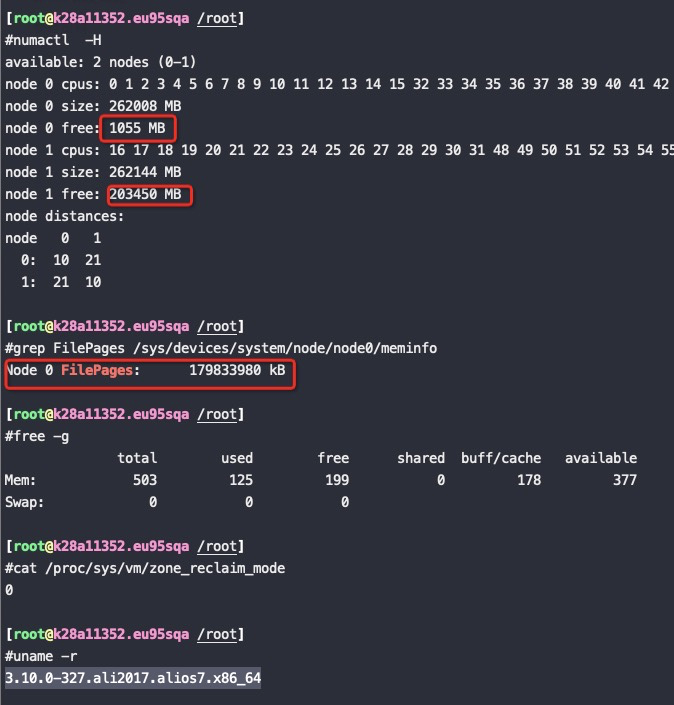
从如上截图来看,再分配64G内存的时候即使node0不够了也没有回收node0上的PageCache,而是将内存跨NUMA分配到了node1上,符合预期!
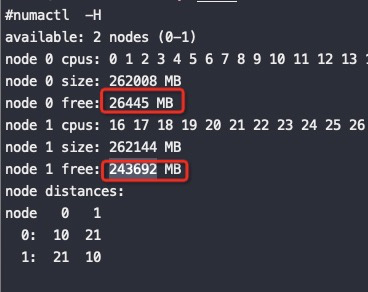
释放这64G内存后,如下图可以看到node0回收了25G,剩下的39G都是在node1上:
4. 将 /proc/sys/vm/zone_reclaim_mode 改成 1 继续同样的测试
可以看到zone_reclaim_mode 改成 1,node0内存不够了也没有分配node1上的内存,而是从PageCache回收了40G内存,整个分配64G内存的过程也比不回收PageCache慢了12秒,这12秒就是额外的卡顿
测试结论:从这个测试可以看到NUMA 在内存使用上不会优先回收 PageCache 了
5. innodb_numa_interleave
从5.7开始,mysql增加了对NUMA的无感知:innodb_numa_interleave,也就是在开了NUMA的机器上,使用内错交错来分配内存,相当于使用上关掉 NUMA
For the
innodb_numa_interleaveoption to be available, MySQL must be compiled on a NUMA-enabled Linux system.
当开启了 innodb_numa_interleave 的话在为innodb buffer pool分配内存的时候将 NUMA memory policy 设置为 MPOL_INTERLEAVE 分配完后再设置回 MPOL_DEFAULT(OS默认内存分配行为,也就是zone_reclaim_mode指定的行为)。
innodb_numa_interleave参数是为innodb更精细化地分配innodb buffer pool 而增加的。很典型地innodb_numa_interleave为on只是更好地规避了前面所说的zone_reclaim_mode的kernel bug,修复后这个参数没有意义了。
5. 1 几种其他关闭NUMA的方案
有了innodb_numa_interleave方案后,就可以废弃以下方案了:
-
在BIOS设置层面关闭NUMA,缺点是需要重启OS。
BIOS:interleave = Disable / Enable -
修改GRUB配置文件,缺点也是要重启OS。具体可参考文章:关于 NUMA 绑核,你需要了解的。。。
-
在/etc/grub.conf的GRUB_CMDLINE_LINUX行添加
numa=off,如下所示:GRUB_CMDLINE_LINUX="crashkernel=auto numa=off rd.lvm.lv=centos/root rd.lvm.lv=centos/swap rhgb quiet" -
重新生成 /etc/grub2.cfg 配置文件:
grub2-mkconfig -o /etc/grub2.cfg -
重启操作系统
-
确认
cat /proc/cmdline
-
三、AUTOMATIC NUMA BALANCING
RedHat 7默认会自动让内存或者进程就近迁移,让内存和CPU距离更近以达到最好的效果
Automatic NUMA balancing improves the performance of applications running on NUMA hardware systems. It is enabled by default on Red Hat Enterprise Linux 7 systems.
An application will generally perform best when the threads of its processes are accessing memory on the same NUMA node as the threads are scheduled. Automatic NUMA balancing moves tasks (which can be threads or processes) closer to the memory they are accessing. It also moves application data to memory closer to the tasks that reference it. This is all done automatically by the kernel when automatic NUMA balancing is active.
对应参数
cat /proc/sys/kernel/numa_balancing shows 1
关闭numa balance:
echo 0 > /proc/sys/kernel/numa_balancing
打开numa balance:
echo 1 > /proc/sys/kernel/numa_balancing
监控
查找相应的内存和调度器事件
#perf stat -e sched:sched_stick_numa,sched:sched_move_numa,sched:sched_swap_numa,migrate:mm_migrate_pages,minor-faults -p 7191
Performance counter stats for process id '7191':
0 sched:sched_stick_numa (100.00%)
1 sched:sched_move_numa (100.00%)
0 sched:sched_swap_numa
0 migrate:mm_migrate_pages
286 minor-faults
# perf stat -e sched:sched_stick_numa,sched:sched_move_numa,sched:sched_swap_numa,migrate:mm_migrate_pages,minor-faults -p PID
...
1 sched:sched_stick_numa
3 sched:sched_move_numa
41 sched:sched_swap_numa
5,239 migrate:mm_migrate_pages
50,161 minor-faults
#perf stat -e sched:sched_stick_numa,sched:sched_move_numa,sched:sched_swap_numa,migrate:mm_migrate_pages,minor-faults -p 676322
Performance counter stats for process id '676322':
0 sched:sched_stick_numa
16 sched:sched_move_numa
0 sched:sched_swap_numa
24 migrate:mm_migrate_pages
2,079 minor-faults















 4009
4009











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-BeNuM38K-1679976116868)(https://plantegg.github.io/images/951413iMgBlog/1620956491058-09a1ebc6-c248-41db-9def-67b4f489c4f4.png)]](https://plantegg.github.io/images/951413iMgBlog/1620956491058-09a1ebc6-c248-41db-9def-67b4f489c4f4.png){kind=link}
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-osK5LoPG-1679976116870)(https://plantegg.github.io/images/951413iMgBlog/1620956524069-85ec2c06-ff55-48e9-8c26-96e738456ed4.png)]](https://plantegg.github.io/images/951413iMgBlog/1620956524069-85ec2c06-ff55-48e9-8c26-96e738456ed4.png){kind=link}
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-WM2UsMxi-1679976116884)(https://plantegg.github.io/images/951413iMgBlog/1620977108922-a2f67827-cf00-43a0-bba1-4ba105a33201.png)]](https://plantegg.github.io/images/951413iMgBlog/1620977108922-a2f67827-cf00-43a0-bba1-4ba105a33201.png){kind=link}