






继上一篇logstash采集日志。
之前用logstash做日志采集,但是发现logstash很占用机器资源导致机器运行有点慢。查询资料表明logstash使用Java编写,插件是使用jruby编写,对机器的资源要求会比较高,网上有一篇关于其性能测试的报告。之前做过和filebeat的测试对比。在采集日志方面,对CPU,内存上都要比前者高很多。那么果断使用filebeat作为替代方案。走起!
1.下载安装
2.采集某个文件到es中
进入主目录,可以看到filebeat.yml 文件,我们备份一下。然后编辑filebeat.yml文件(将此文件内容清空,重新编辑)。
yml文件格式要求严格缩进
filebeat.inputs:
- type: log #默认log,从日志文件读取每一行。stdin,从标准输入读取
paths:
- F:/test/service-thymeleaf.log # 这里也可用通配符采集多个文件如F:/test/*.log
output.elasticsearch:
hosts: ["localhost:9200"]
在主目录下命令行执行 filebeat.exe -e -c filebeat.yml,观察es的索引多了filebeat-日期格式样式的索引。
这个自动生成的索引名称看着别扭,我们自己修改。日期后缀每天新建一个索引。setup.template.name setup.template.pattern 两项的值可以随意起
filebeat.inputs:
- type: log #默认log,从日志文件读取每一行。stdin,从标准输入读取
paths:
- F:/test/service-thymeleaf.log
setup.template.name: "my-log"
setup.template.pattern: "my-log-*"
output.elasticsearch:
hosts: ["localhost:9200"]
index: "service-thymeleaf-%{+yyyy.MM.dd}"
采集java多行日志合并
filebeat.inputs:
- type: log #默认log,从日志文件读取每一行。stdin,从标准输入读取
paths:
- F:/test/service-thymeleaf.log
multiline.pattern: '^\d{4}\-\d{2}\-\d{2}\s\d{2}:\d{2}:\d{2}' #匹配的正则 不是以2019-09-08 12:23:23 格式开头的将合并到上一行
multiline.negate: true #多行匹配模式后配置的模式是否取反,默认false
multiline.match: after #定义多行内容被添加到模式匹配行之后还是之前,默认无,可以被设置为after或者before
setup.template.name: "my-log"
setup.template.pattern: "my-log-*"
output.elasticsearch:
hosts: ["localhost:9200"]
index: "service-thymeleaf-%{+yyyy.MM.dd}"
采集多个文件到不同的索引
例如将a.log 采集到a-2019-09-09索引,b.log 采集到b-2019-09-09索引
filebeat.inputs:
- type: log #默认log,从日志文件读取每一行。stdin,从标准输入读取
paths:
- F:/test/service-thymeleaf.log
multiline.pattern: '^\d{4}\-\d{2}\-\d{2}\s\d{2}:\d{2}:\d{2}' #匹配的正则 不是以2019-09-08 12:23:23 格式开头的将合并到上一行
multiline.negate: true #多行匹配模式后配置的模式是否取反,默认false
multiline.match: after #定义多行内容被添加到模式匹配行之后还是之前,默认无,可以被设置为after或者before
fields:
index: 'service-thymeleaf'
- type: log #默认log,从日志文件读取每一行。stdin,从标准输入读取
paths:
- F:/test/service-es.log
multiline.pattern: '^\d{4}\-\d{2}\-\d{2}\s\d{2}:\d{2}:\d{2}' #匹配的正则
multiline.negate: true #多行匹配模式后配置的模式是否取反,默认false
multiline.match: after #定义多行内容被添加到模式匹配行之后还是之前,默认无,可以被设置为after或者before
fields:
index: 'service-es'
setup.template.name: "my-log"
setup.template.pattern: "my-log-*"
output.elasticsearch:
hosts: ["localhost:9200"]
indices:
- index: "service-thymeleaf-%{+yyyy.MM.dd}"
when.contains:
fields:
index: "service-thymeleaf"
- index: "service-es-%{+yyyy.MM.dd}"
when.contains:
fields:
index: "service-es"
如果想对采集的内容进行预处理(过滤等),比如从日志中提取某些字段filebeat不像logstash那么灵活需要借助es的pipeline,而此处主要是将@timestamps时间修改日志的时间(默认是采集的时间)
(1)在es中创建一个pipeline,timestamp-pipeline-id 是唯一的
PUT _ingest/pipeline/timestamp-pipeline-id
{
"description": "timestamp pipeline",
"processors": [
{
"grok": {
"field": "message",
"patterns": [
"%{TIMESTAMP_ISO8601:timestamp} "
]
}
},
{
"date": {
"field": "timestamp",
"formats": [
"yyyy-MM-dd HH:mm:ss.SSS"
]
},
"remove": {
"field": "timestamp"
}
}
],
"on_failure": [
{
"set": {
"field": "_index",
"value": "failed-{{ _index }}"
}
}
]
}
创建pipeline可以在es-head中执行
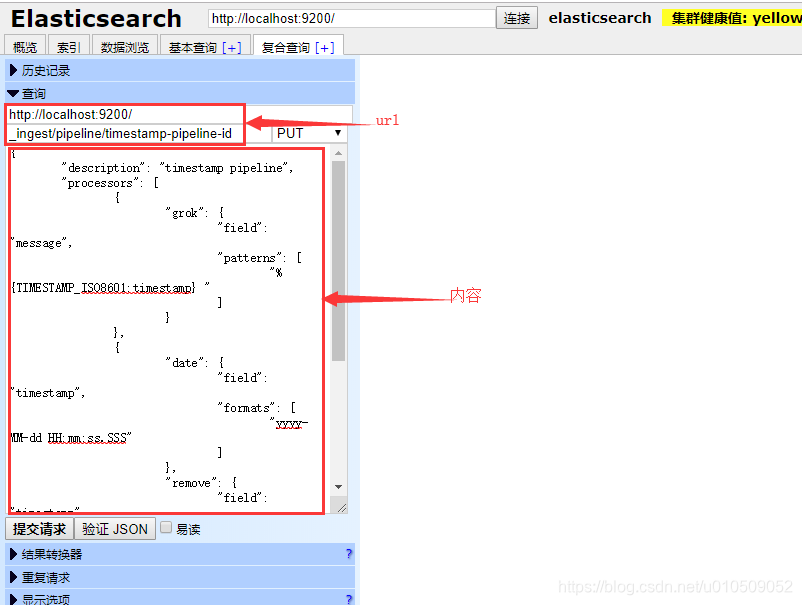
也可以在kibana中的开发工具执行
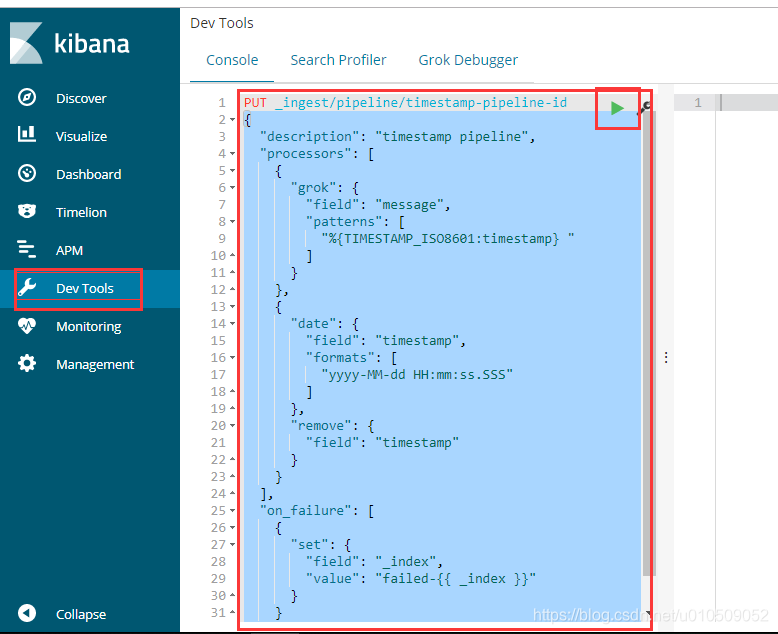
2.然后filebeat.yml中添加
pipeline: “timestamp-pipeline-id”
filebeat.inputs:
- type: log #默认log,从日志文件读取每一行。stdin,从标准输入读取
paths:
- F:/test/service-thymeleaf.log
multiline.pattern: '^\d{4}\-\d{2}\-\d{2}\s\d{2}:\d{2}:\d{2}' #匹配的正则
multiline.negate: true #多行匹配模式后配置的模式是否取反,默认false
multiline.match: after #定义多行内容被添加到模式匹配行之后还是之前,默认无,可以被设置为after或者before
fields:
index: 'service-thymeleaf'
- type: log #默认log,从日志文件读取每一行。stdin,从标准输入读取
paths:
- F:/test/service-es.log
multiline.pattern: '^\d{4}\-\d{2}\-\d{2}\s\d{2}:\d{2}:\d{2}' #匹配的正则
multiline.negate: true #多行匹配模式后配置的模式是否取反,默认false
multiline.match: after #定义多行内容被添加到模式匹配行之后还是之前,默认无,可以被设置为after或者before
fields:
index: 'service-es'
setup.template.name: "my-log"
setup.template.pattern: "my-log-*"
output.elasticsearch:
hosts: ["localhost:9200"]
indices:
- index: "service-thymeleaf-%{+yyyy.MM.dd}"
when.contains:
fields:
index: "service-thymeleaf"
- index: "service-es-%{+yyyy.MM.dd}"
when.contains:
fields:
index: "service-es"
pipeline: "timestamp-pipeline-id"
document_type: log #该type会被添加到type字段,对于输出到ES来说,这个输入时的type字段会被存储,默认log
max_retries: 3 #ES重试次数,默认3次,超过3次后,当前事件将被丢弃
如有问题,私信一起学习交流。

















 905
905

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









