









备注:
Hive 版本 2.1.1
一.Hive SELECT(数据查询语言)概述
select语句是Hive中使用的最频繁,也是语法最为复杂的语句。select语句很多语法与传统的关系型数据库类似,这也就给从传统数据库转大数据hive数据仓库提供了便利。
语法:
[WITH CommonTableExpression (, CommonTableExpression)*] (Note: Only available starting with Hive 0.13.0)
SELECT [ALL | DISTINCT] select_expr, select_expr, ...
FROM table_reference
[WHERE where_condition]
[GROUP BY col_list]
[ORDER BY col_list]
[CLUSTER BY col_list
| [DISTRIBUTE BY col_list] [SORT BY col_list]
]
[LIMIT [offset,] rows]
测试数据准备:
drop table if exists dept;
drop table if exists emp;
drop table if exists bonus;
drop table if exists salgrade;
create table DEPT
( deptno INT,
dname VARCHAR(14),
loc VARCHAR(13)
);
insert into DEPT(deptno, dname, loc) values ('10', 'ACCOUNTING', 'NEW YORK');
insert into DEPT(deptno, dname, loc) values ('20', 'RESEARCH', 'DALLAS');
insert into DEPT(deptno, dname, loc) values ('30', 'SALES', 'CHICAGO');
insert into DEPT(deptno, dname, loc) values ('40', 'OPERATIONS', 'BOSTON');
-- Create table
create table EMP
(
empno INT,
ename VARCHAR(10),
job VARCHAR(9),
mgr INT,
hiredate DATE,
sal decimal(7,2),
comm decimal(7,2),
deptno INT
) ;
insert into EMP(empno, ename, job, mgr, hiredate, sal, comm, deptno)
values ('7369', 'SMITH', 'CLERK', '7902','1980-12-17', '800', null, '20');
insert into EMP(empno, ename, job, mgr, hiredate, sal, comm, deptno)
values ('7499', 'ALLEN', 'SALESMAN', '7698', '1981-02-20', '1600', '300', '30');
insert into EMP(empno, ename, job, mgr, hiredate, sal, comm, deptno)
values ('7521', 'WARD', 'SALESMAN', '7698', '1981-02-22', '1250', '500', '30');
insert into EMP(empno, ename, job, mgr, hiredate, sal, comm, deptno)
values ('7566', 'JONES', 'MANAGER', '7839', '1981-04-02', '2975', null, '20');
insert into EMP(empno, ename, job, mgr, hiredate, sal, comm, deptno)
values ('7654', 'MARTIN', 'SALESMAN', '7698', '1981-09-28', '1250', '1400', '30');
insert into EMP(empno, ename, job, mgr, hiredate, sal, comm, deptno)
values ('7698', 'BLAKE', 'MANAGER', '7839', '1981-05-01', '2850', null, '30');
insert into EMP(empno, ename, job, mgr, hiredate, sal, comm, deptno)
values ('7782', 'CLARK', 'MANAGER', '7839', '1981-06-09', '2450', null, '10');
insert into EMP(empno, ename, job, mgr, hiredate, sal, comm, deptno)
values ('7788', 'SCOTT', 'ANALYST', '7566', '1987-06-13', '3000', null, '20');
insert into EMP(empno, ename, job, mgr, hiredate, sal, comm, deptno)
values ('7839', 'KING', 'PRESIDENT', null, '1981-11-17', '5000', null, '10');
insert into EMP(empno, ename, job, mgr, hiredate, sal, comm, deptno)
values ('7844', 'TURNER', 'SALESMAN', '7698', '1981-09-08', '1500', '0', '30');
insert into EMP(empno, ename, job, mgr, hiredate, sal, comm, deptno)
values ('7876', 'ADAMS', 'CLERK', '7788', '1987-06-13', '1100', null, '20');
insert into EMP(empno, ename, job, mgr, hiredate, sal, comm, deptno)
values ('7900', 'JAMES', 'CLERK', '7698', '1981-12-03', '950', null, '30');
insert into EMP(empno, ename, job, mgr, hiredate, sal, comm, deptno)
values ('7902', 'FORD', 'ANALYST', '7566', '1981-12-03', '3000', null, '20');
insert into EMP(empno, ename, job, mgr, hiredate, sal, comm, deptno)
values ('7934', 'MILLER', 'CLERK', '7782', '1982-01-23', '1300', null, '10');
create table SALGRADE
(
grade INT,
losal INT,
hisal INT
) ;
insert into SALGRADE(grade, losal, hisal)
values ('1', '700', '1200');
insert into SALGRADE(grade, losal, hisal)
values ('2', '1201', '1400');
insert into SALGRADE(grade, losal, hisal)
values ('3', '1401', '2000');
insert into SALGRADE(grade, losal, hisal)
values ('4', '2001', '3000');
insert into SALGRADE(grade, losal, hisal)
values ('5', '3001', '9999');
create table BONUS
(
ename VARCHAR(10),
job VARCHAR(9),
sal INT,
comm INT
) ;
二.Select的几个简单例子
打开hive的列头输出:
set hive.cli.print.header=true;
下面以几个简单的例子来认识下select语句
2.1 表别名
当select中有多个表时,可以给表一个别名,一些可视化工具,例如DBeaver中,有别名可以直接带出相应的列。
select ename,sal from emp;
select e.ename,e.sal from emp e;
测试记录:
hive>
> select ename,sal from emp;
OK
ename sal
SMITH 800.00
ALLEN 1600.00
ADAMS 1100.00
JAMES 950.00
FORD 3000.00
MILLER 1300.00
WARD 1250.00
JONES 2975.00
MARTIN 1250.00
BLAKE 2850.00
CLARK 2450.00
SCOTT 3000.00
KING 5000.00
TURNER 1500.00
Time taken: 0.073 seconds, Fetched: 14 row(s)
hive> select e.ename,e.sal from emp e;
OK
e.ename e.sal
SMITH 800.00
ALLEN 1600.00
ADAMS 1100.00
JAMES 950.00
FORD 3000.00
MILLER 1300.00
WARD 1250.00
JONES 2975.00
MARTIN 1250.00
BLAKE 2850.00
CLARK 2450.00
SCOTT 3000.00
KING 5000.00
TURNER 1500.00
Time taken: 0.07 seconds, Fetched: 14 row(s)
2.2 字段值的计算
实际的数据开发过程中,有时候会对表的列进行一些的计算。
代码:
SELECT count(*), avg(sal) FROM emp;
测试记录:
hive>
> SELECT count(*), avg(sal) FROM emp;
Query ID = root_20201204164822_8e00e473-82d2-406c-af03-f6236729d963
Total jobs = 1
Launching Job 1 out of 1
Number of reduce tasks determined at compile time: 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
Starting Job = job_1606698967173_0088, Tracking URL = http://hp1:8088/proxy/application_1606698967173_0088/
Kill Command = /opt/cloudera/parcels/CDH-6.3.1-1.cdh6.3.1.p0.1470567/lib/hadoop/bin/hadoop job -kill job_1606698967173_0088
Hadoop job information for Stage-1: number of mappers: 2; number of reducers: 1
2020-12-04 16:48:30,047 Stage-1 map = 0%, reduce = 0%
2020-12-04 16:48:36,234 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 4.25 sec
2020-12-04 16:48:41,388 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 6.31 sec
MapReduce Total cumulative CPU time: 6 seconds 310 msec
Ended Job = job_1606698967173_0088
MapReduce Jobs Launched:
Stage-Stage-1: Map: 2 Reduce: 1 Cumulative CPU: 6.31 sec HDFS Read: 17740 HDFS Write: 114 HDFS EC Read: 0 SUCCESS
Total MapReduce CPU Time Spent: 6 seconds 310 msec
OK
_c0 _c1
14 2073.214286
Time taken: 19.467 seconds, Fetched: 1 row(s)
2.3 字段别名
我们看到上面的例子,没有给字段加别名,导致系统随机的给了_c0 _c1这样的。
除了可以给表别名之外,还可以给列加别名。
代码:
SELECT count(*) as emp_count, avg(sal) as avg_salary FROM emp;
测试记录:
hive>
> SELECT count(*) as emp_count, avg(sal) as avg_salary FROM emp;
Query ID = root_20201204165143_ce11cb13-1464-4b7c-8e65-327395c82bed
Total jobs = 1
Launching Job 1 out of 1
Number of reduce tasks determined at compile time: 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
Starting Job = job_1606698967173_0089, Tracking URL = http://hp1:8088/proxy/application_1606698967173_0089/
Kill Command = /opt/cloudera/parcels/CDH-6.3.1-1.cdh6.3.1.p0.1470567/lib/hadoop/bin/hadoop job -kill job_1606698967173_0089
Hadoop job information for Stage-1: number of mappers: 2; number of reducers: 1
2020-12-04 16:51:49,569 Stage-1 map = 0%, reduce = 0%
2020-12-04 16:51:55,759 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 4.17 sec
2020-12-04 16:52:01,934 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 6.4 sec
MapReduce Total cumulative CPU time: 6 seconds 400 msec
Ended Job = job_1606698967173_0089
MapReduce Jobs Launched:
Stage-Stage-1: Map: 2 Reduce: 1 Cumulative CPU: 6.4 sec HDFS Read: 17733 HDFS Write: 114 HDFS EC Read: 0 SUCCESS
Total MapReduce CPU Time Spent: 6 seconds 400 msec
OK
emp_count avg_salary
14 2073.214286
Time taken: 19.514 seconds, Fetched: 1 row(s)
2.4 LIMIT
LIMIT用于限制输出的行,例如我只想输出10行,就用limit 10
代码:
SELECT ename, sal FROM emp LIMIT 10;
测试记录:
hive>
> SELECT ename, sal FROM emp LIMIT 10;
OK
ename sal
SMITH 800.00
ALLEN 1600.00
ADAMS 1100.00
JAMES 950.00
FORD 3000.00
MILLER 1300.00
WARD 1250.00
JONES 2975.00
MARTIN 1250.00
BLAKE 2850.00
Time taken: 0.077 seconds, Fetched: 10 row(s)
2.5 FROM子查询
有时候逻辑相对而言比较复杂,需要用到from 子查询语句。
代码:
SELECT ename,sal
from
(select ename,sal from emp) e;
测试记录:
hive>
> SELECT ename,sal
> from
> (select ename,sal from emp) e;
OK
ename sal
SMITH 800.00
ALLEN 1600.00
ADAMS 1100.00
JAMES 950.00
FORD 3000.00
MILLER 1300.00
WARD 1250.00
JONES 2975.00
MARTIN 1250.00
BLAKE 2850.00
CLARK 2450.00
SCOTT 3000.00
KING 5000.00
TURNER 1500.00
Time taken: 0.069 seconds, Fetched: 14 row(s)
2.6 case when 判断
假设我此时需要根据薪酬来判断薪资的级别,可以通过case when语句进行判断。
代码:
select ename,
sal,
case when sal >= 3000 then 'High SAL'
when sal >= 2000 and sal < 3000 then 'Middle SAL'
else 'Low SAL'
end as sal_grade
from emp;
测试记录:
hive>
> select ename,
> sal,
> case when sal >= 3000 then 'High SAL'
> when sal >= 2000 and sal < 3000 then 'Middle SAL'
> else 'Low SAL'
> end as sal_grade
> from emp;
Query ID = root_20201204165914_7229d9ea-b045-423b-a240-b04e6e8276e1
Total jobs = 1
Launching Job 1 out of 1
Number of reduce tasks is set to 0 since there's no reduce operator
Starting Job = job_1606698967173_0090, Tracking URL = http://hp1:8088/proxy/application_1606698967173_0090/
Kill Command = /opt/cloudera/parcels/CDH-6.3.1-1.cdh6.3.1.p0.1470567/lib/hadoop/bin/hadoop job -kill job_1606698967173_0090
Hadoop job information for Stage-1: number of mappers: 2; number of reducers: 0
2020-12-04 16:59:21,504 Stage-1 map = 0%, reduce = 0%
2020-12-04 16:59:28,775 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 6.75 sec
MapReduce Total cumulative CPU time: 6 seconds 750 msec
Ended Job = job_1606698967173_0090
MapReduce Jobs Launched:
Stage-Stage-1: Map: 2 Cumulative CPU: 6.75 sec HDFS Read: 13014 HDFS Write: 660 HDFS EC Read: 0 SUCCESS
Total MapReduce CPU Time Spent: 6 seconds 750 msec
OK
ename sal sal_grade
ALLEN 1600.00 Low SAL
ADAMS 1100.00 Low SAL
MILLER 1300.00 Low SAL
WARD 1250.00 Low SAL
MARTIN 1250.00 Low SAL
BLAKE 2850.00 Middle SAL
SCOTT 3000.00 High SAL
SMITH 800.00 Low SAL
JAMES 950.00 Low SAL
FORD 3000.00 High SAL
JONES 2975.00 Middle SAL
CLARK 2450.00 Middle SAL
KING 5000.00 High SAL
TURNER 1500.00 Low SAL
Time taken: 15.382 seconds, Fetched: 14 row(s)
hive>
2.7 where过滤
此时我只想看dept 为10的员工信息,并不想看所有,此时可以通过where子句进行过滤
代码:
select ename,sal from emp where deptno = '10';
测试记录:
hive> select ename,sal from emp where deptno = '10';
Query ID = root_20201204170244_78b7dc0a-5e43-4183-bd47-9379092687cc
Total jobs = 1
Launching Job 1 out of 1
Number of reduce tasks is set to 0 since there's no reduce operator
Starting Job = job_1606698967173_0091, Tracking URL = http://hp1:8088/proxy/application_1606698967173_0091/
Kill Command = /opt/cloudera/parcels/CDH-6.3.1-1.cdh6.3.1.p0.1470567/lib/hadoop/bin/hadoop job -kill job_1606698967173_0091
Hadoop job information for Stage-1: number of mappers: 2; number of reducers: 0
2020-12-04 17:02:52,315 Stage-1 map = 0%, reduce = 0%
2020-12-04 17:02:58,494 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 6.73 sec
MapReduce Total cumulative CPU time: 6 seconds 730 msec
Ended Job = job_1606698967173_0091
MapReduce Jobs Launched:
Stage-Stage-1: Map: 2 Cumulative CPU: 6.73 sec HDFS Read: 12664 HDFS Write: 252 HDFS EC Read: 0 SUCCESS
Total MapReduce CPU Time Spent: 6 seconds 730 msec
OK
ename sal
MILLER 1300.00
CLARK 2450.00
KING 5000.00
Time taken: 14.775 seconds, Fetched: 3 row(s)
2.8 group by分组
加上此时我想知道每个部门的平均工资,此时可以通过group by分组语句实现
代码:
select deptno,avg(sal) from emp group by deptno;
测试记录:
hive>
> select deptno,avg(sal) from emp group by deptno;
Query ID = root_20201204170424_288f6ce3-a3ee-4f7c-99b9-5634269bb613
Total jobs = 1
Launching Job 1 out of 1
Number of reduce tasks not specified. Estimated from input data size: 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
Starting Job = job_1606698967173_0092, Tracking URL = http://hp1:8088/proxy/application_1606698967173_0092/
Kill Command = /opt/cloudera/parcels/CDH-6.3.1-1.cdh6.3.1.p0.1470567/lib/hadoop/bin/hadoop job -kill job_1606698967173_0092
Hadoop job information for Stage-1: number of mappers: 2; number of reducers: 1
2020-12-04 17:04:31,900 Stage-1 map = 0%, reduce = 0%
2020-12-04 17:04:39,100 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 4.19 sec
2020-12-04 17:04:44,246 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 6.29 sec
MapReduce Total cumulative CPU time: 6 seconds 290 msec
Ended Job = job_1606698967173_0092
MapReduce Jobs Launched:
Stage-Stage-1: Map: 2 Reduce: 1 Cumulative CPU: 6.29 sec HDFS Read: 17311 HDFS Write: 168 HDFS EC Read: 0 SUCCESS
Total MapReduce CPU Time Spent: 6 seconds 290 msec
OK
deptno _c1
10 2916.666667
20 2175.000000
30 1566.666667
Time taken: 20.501 seconds, Fetched: 3 row(s)
hive>
2.9 Having子句
HAVING用于约束结果集,只给出符合HAVING条件的结果
代码:
select deptno,avg(sal) avg_sal from emp group by deptno having avg(sal) > 2000;
测试记录:
hive>
> select deptno,avg(sal) avg_sal from emp group by deptno having avg(sal) > 2000;
Query ID = root_20201204170622_ee515280-33b8-4cf7-af56-a1cdb9731d38
Total jobs = 1
Launching Job 1 out of 1
Number of reduce tasks not specified. Estimated from input data size: 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
Starting Job = job_1606698967173_0093, Tracking URL = http://hp1:8088/proxy/application_1606698967173_0093/
Kill Command = /opt/cloudera/parcels/CDH-6.3.1-1.cdh6.3.1.p0.1470567/lib/hadoop/bin/hadoop job -kill job_1606698967173_0093
Hadoop job information for Stage-1: number of mappers: 2; number of reducers: 1
2020-12-04 17:06:29,633 Stage-1 map = 0%, reduce = 0%
2020-12-04 17:06:36,835 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 4.31 sec
2020-12-04 17:06:43,012 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 7.56 sec
MapReduce Total cumulative CPU time: 7 seconds 560 msec
Ended Job = job_1606698967173_0093
MapReduce Jobs Launched:
Stage-Stage-1: Map: 2 Reduce: 1 Cumulative CPU: 7.56 sec HDFS Read: 17746 HDFS Write: 141 HDFS EC Read: 0 SUCCESS
Total MapReduce CPU Time Spent: 7 seconds 560 msec
OK
deptno avg_sal
10 2916.666667
20 2175.000000
Time taken: 21.566 seconds, Fetched: 2 row(s)
hive>
三.Hive的join
Hive的join与关系型数据库的类似,但是要注意,hive不支持非等值连接。
语法:
join_table:
table_reference [INNER] JOIN table_factor [join_condition]
| table_reference {LEFT|RIGHT|FULL} [OUTER] JOIN table_reference join_condition
| table_reference LEFT SEMI JOIN table_reference join_condition
| table_reference CROSS JOIN table_reference [join_condition] (as of Hive 0.10)
table_reference:
table_factor
| join_table
table_factor:
tbl_name [alias]
| table_subquery alias
| ( table_references )
join_condition:
ON expression
hive 支持如下连接:
INNER JOIN
LEFT OUTER JOIN
RIGHT OUTER JOIN
FULL OUTER JOIN
LEFT SEMI JOIN
Join MapReduce实现
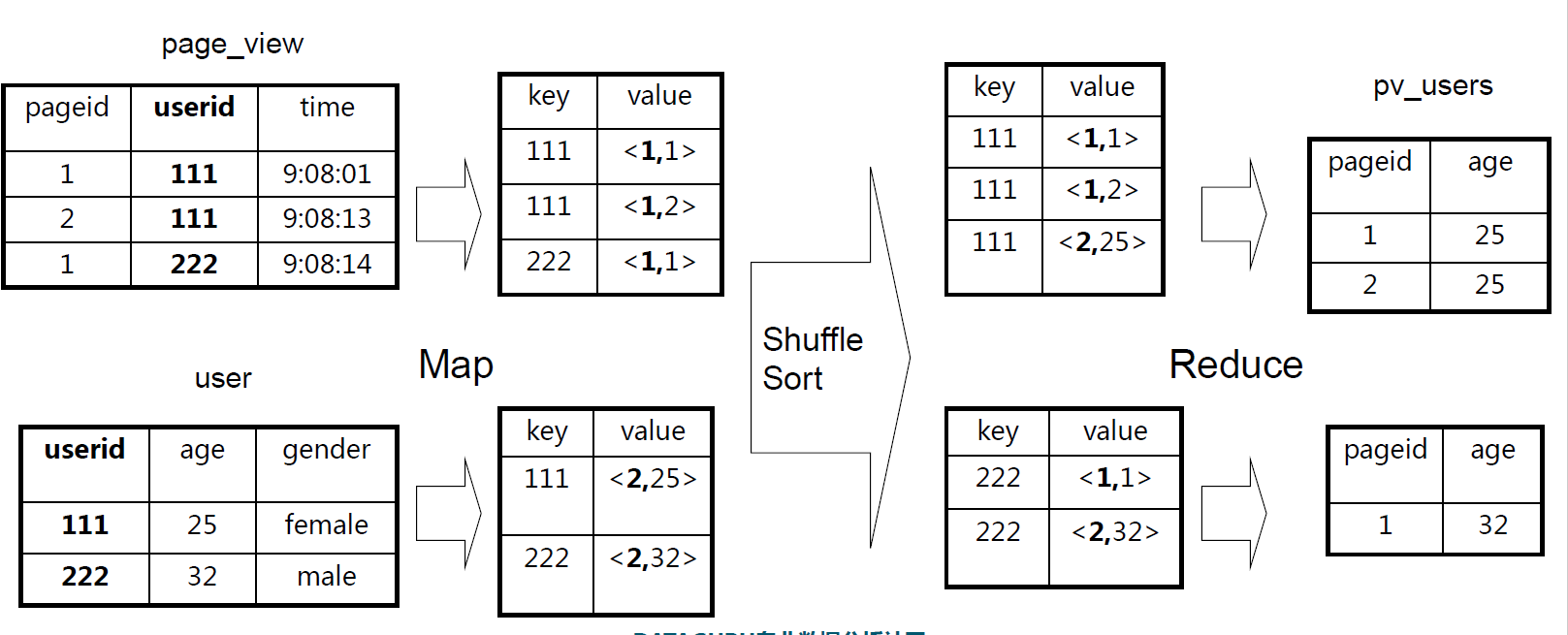
测试数据:
create table t1(id int);
create table t2(id int);
insert into t1 values(1);
insert into t1 values(2);
insert into t2 values(2);
insert into t2 values(3);
3.1 内连接 --求交集
select t1.id,t2.id id2
from t1
inner join t2
on t1.id = t2.id;
--或者
select t1.id,t2.id id2
from t1,t2
where t1.id = t2.id;
hive>
> select t1.id,t2.id id2
> from t1
> inner join t2
> on t1.id = t2.id;
Query ID = root_20201204191120_3861be11-a271-4bc4-b240-a5ec96b9794e
Total jobs = 1
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/cloudera/parcels/CDH-6.3.1-1.cdh6.3.1.p0.1470567/jars/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
Execution completed successfully
MapredLocal task succeeded
Launching Job 1 out of 1
Number of reduce tasks is set to 0 since there's no reduce operator
Starting Job = job_1606698967173_0114, Tracking URL = http://hp1:8088/proxy/application_1606698967173_0114/
Kill Command = /opt/cloudera/parcels/CDH-6.3.1-1.cdh6.3.1.p0.1470567/lib/hadoop/bin/hadoop job -kill job_1606698967173_0114
Hadoop job information for Stage-3: number of mappers: 2; number of reducers: 0
2020-12-04 19:11:34,556 Stage-3 map = 0%, reduce = 0%
2020-12-04 19:11:42,800 Stage-3 map = 100%, reduce = 0%, Cumulative CPU 6.34 sec
MapReduce Total cumulative CPU time: 6 seconds 340 msec
Ended Job = job_1606698967173_0114
MapReduce Jobs Launched:
Stage-Stage-3: Map: 2 Cumulative CPU: 6.34 sec HDFS Read: 12447 HDFS Write: 190 HDFS EC Read: 0 SUCCESS
Total MapReduce CPU Time Spent: 6 seconds 340 msec
OK
t1.id id2
2 2
Time taken: 23.749 seconds, Fetched: 1 row(s)
hive> select t1.id,t2.id id2
> from t1,t2
> where t1.id = t2.id;
Query ID = root_20201204191146_2e3e53c9-5f29-4d17-84f6-8222f5b4c742
Total jobs = 1
Execution completed successfully
MapredLocal task succeeded
Launching Job 1 out of 1
Number of reduce tasks is set to 0 since there's no reduce operator
Starting Job = job_1606698967173_0115, Tracking URL = http://hp1:8088/proxy/application_1606698967173_0115/
Kill Command = /opt/cloudera/parcels/CDH-6.3.1-1.cdh6.3.1.p0.1470567/lib/hadoop/bin/hadoop job -kill job_1606698967173_0115
Hadoop job information for Stage-3: number of mappers: 2; number of reducers: 0
2020-12-04 19:12:01,580 Stage-3 map = 0%, reduce = 0%
2020-12-04 19:12:07,771 Stage-3 map = 100%, reduce = 0%, Cumulative CPU 6.67 sec
MapReduce Total cumulative CPU time: 6 seconds 670 msec
Ended Job = job_1606698967173_0115
MapReduce Jobs Launched:
Stage-Stage-3: Map: 2 Cumulative CPU: 6.67 sec HDFS Read: 12773 HDFS Write: 190 HDFS EC Read: 0 SUCCESS
Total MapReduce CPU Time Spent: 6 seconds 670 msec
OK
t1.id id2
2 2
Time taken: 22.941 seconds, Fetched: 1 row(s)
hive>
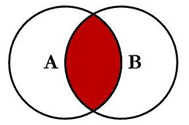
3.2 左连接 --求A的全部
select t1.id,t2.id id2
from t1
left join t2
on t1.id = t2.id;
hive> select t1.id,t2.id id2
> from t1
> left join t2
> on t1.id = t2.id;
Query ID = root_20201204191035_0e063217-a8b4-4669-8a30-5e1be3e903eb
Total jobs = 1
WARNING: Use "yarn jar" to launch YARN applications.
2020-12-04 19:10:42 Uploaded 1 File to: file:/tmp/root/e8ed4bca-fbbf-4db0-b223-33d23b3bbc3a/hive_2020-12-04_19-10-35_645_5302676112925292414-1/-local-10003/HashTable-Stage-3/MapJoin-mapfile91--.hashtable (296 bytes)
2020-12-04 19:10:42 End of local task; Time Taken: 0.963 sec.
Execution completed successfully
MapredLocal task succeeded
Launching Job 1 out of 1
Number of reduce tasks is set to 0 since there's no reduce operator
Starting Job = job_1606698967173_0113, Tracking URL = http://hp1:8088/proxy/application_1606698967173_0113/
Kill Command = /opt/cloudera/parcels/CDH-6.3.1-1.cdh6.3.1.p0.1470567/lib/hadoop/bin/hadoop job -kill job_1606698967173_0113
Hadoop job information for Stage-3: number of mappers: 1; number of reducers: 0
2020-12-04 19:10:49,515 Stage-3 map = 0%, reduce = 0%
2020-12-04 19:10:56,723 Stage-3 map = 100%, reduce = 0%, Cumulative CPU 1.98 sec
MapReduce Total cumulative CPU time: 1 seconds 980 msec
Ended Job = job_1606698967173_0113
MapReduce Jobs Launched:
Stage-Stage-3: Map: 1 Cumulative CPU: 1.98 sec HDFS Read: 6112 HDFS Write: 120 HDFS EC Read: 0 SUCCESS
Total MapReduce CPU Time Spent: 1 seconds 980 msec
OK
t1.id id2
1 NULL
2 2
Time taken: 22.147 seconds, Fetched: 2 row(s)
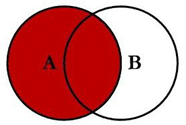
3.3 左连接 --实现A-B的差集
select t1.id,t2.id id2
from t1
left join t2
on t1.id = t2.id
where t2.id is null;
hive> select t1.id,t2.id id2
> from t1
> left join t2
> on t1.id = t2.id
> where t2.id is null;
Query ID = root_20201204190954_8ea563bb-c5e6-4d00-8262-ed1264c1c1cc
Total jobs = 1
Execution completed successfully
MapredLocal task succeeded
Launching Job 1 out of 1
Number of reduce tasks is set to 0 since there's no reduce operator
Starting Job = job_1606698967173_0112, Tracking URL = http://hp1:8088/proxy/application_1606698967173_0112/
Kill Command = /opt/cloudera/parcels/CDH-6.3.1-1.cdh6.3.1.p0.1470567/lib/hadoop/bin/hadoop job -kill job_1606698967173_0112
Hadoop job information for Stage-3: number of mappers: 1; number of reducers: 0
2020-12-04 19:10:08,983 Stage-3 map = 0%, reduce = 0%
2020-12-04 19:10:15,161 Stage-3 map = 100%, reduce = 0%, Cumulative CPU 3.0 sec
MapReduce Total cumulative CPU time: 3 seconds 0 msec
Ended Job = job_1606698967173_0112
MapReduce Jobs Launched:
Stage-Stage-3: Map: 1 Cumulative CPU: 3.0 sec HDFS Read: 6586 HDFS Write: 104 HDFS EC Read: 0 SUCCESS
Total MapReduce CPU Time Spent: 3 seconds 0 msec
OK
t1.id id2
1 NULL
Time taken: 22.658 seconds, Fetched: 1 row(s)
3.4 全连接 – A union B 求合集
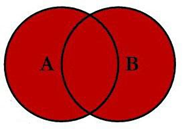
select t1.id id1,t2.id id2
from t1
full join t2
on t1.id = t2.id
hive>
> select t1.id id1,t2.id id2
> from t1
> full join t2
> on t1.id = t2.id
> ;
Query ID = root_20201204190853_888f4198-8453-4c53-b8ce-bc06c59ebc6a
Total jobs = 1
Launching Job 1 out of 1
Number of reduce tasks not specified. Estimated from input data size: 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
Starting Job = job_1606698967173_0111, Tracking URL = http://hp1:8088/proxy/application_1606698967173_0111/
Kill Command = /opt/cloudera/parcels/CDH-6.3.1-1.cdh6.3.1.p0.1470567/lib/hadoop/bin/hadoop job -kill job_1606698967173_0111
Hadoop job information for Stage-1: number of mappers: 3; number of reducers: 1
2020-12-04 19:09:00,901 Stage-1 map = 0%, reduce = 0%
2020-12-04 19:09:07,088 Stage-1 map = 67%, reduce = 0%, Cumulative CPU 3.77 sec
2020-12-04 19:09:10,186 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 5.55 sec
2020-12-04 19:09:15,339 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 7.94 sec
MapReduce Total cumulative CPU time: 7 seconds 940 msec
Ended Job = job_1606698967173_0111
MapReduce Jobs Launched:
Stage-Stage-1: Map: 3 Reduce: 1 Cumulative CPU: 7.94 sec HDFS Read: 17569 HDFS Write: 137 HDFS EC Read: 0 SUCCESS
Total MapReduce CPU Time Spent: 7 seconds 940 msec
OK
id1 id2
1 NULL
2 2
NULL 3
Time taken: 22.535 seconds, Fetched: 3 row(s)
3.5 全连接实现-去交集
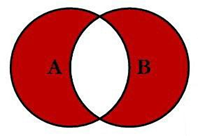
select t1.id id1,t2.id id2
from t1
left join t2
on t1.id = t2.id
where t2.id is null
union all
select t1.id id1,t2.id id2
from t1
right join t2
on t1.id = t2.id
where t1.id is null;
hive>
> select t1.id id1,t2.id id2
> from t1
> left join t2
> on t1.id = t2.id
> where t2.id is null
> union all
> select t1.id id1,t2.id id2
> from t1
> right join t2
> on t1.id = t2.id
> where t1.id is null;
Query ID = root_20201204190745_d1e37397-4a04-44b5-920b-cc9e3327d6ac
Total jobs = 1
Execution completed successfully
MapredLocal task succeeded
Launching Job 1 out of 1
Number of reduce tasks is set to 0 since there's no reduce operator
Starting Job = job_1606698967173_0110, Tracking URL = http://hp1:8088/proxy/application_1606698967173_0110/
Kill Command = /opt/cloudera/parcels/CDH-6.3.1-1.cdh6.3.1.p0.1470567/lib/hadoop/bin/hadoop job -kill job_1606698967173_0110
Hadoop job information for Stage-2: number of mappers: 3; number of reducers: 0
2020-12-04 19:07:59,931 Stage-2 map = 0%, reduce = 0%
2020-12-04 19:08:08,176 Stage-2 map = 67%, reduce = 0%, Cumulative CPU 5.88 sec
2020-12-04 19:08:12,287 Stage-2 map = 100%, reduce = 0%, Cumulative CPU 8.79 sec
MapReduce Total cumulative CPU time: 8 seconds 790 msec
Ended Job = job_1606698967173_0110
MapReduce Jobs Launched:
Stage-Stage-2: Map: 3 Cumulative CPU: 8.79 sec HDFS Read: 23996 HDFS Write: 295 HDFS EC Read: 0 SUCCESS
Total MapReduce CPU Time Spent: 8 seconds 790 msec
OK
_u1.id1 _u1.id2
1 NULL
NULL 3
Time taken: 27.58 seconds, Fetched: 2 row(s)
3.6 右连接实现-B-A 求差集
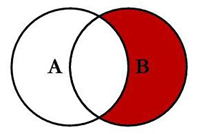
select t1.id,t2.id id2
from t1
right join t2
on t1.id = t2.id
where t1.id is null;
hive> select t1.id,t2.id id2
> from t1
> right join t2
> on t1.id = t2.id
> where t1.id is null;
Query ID = root_20201204190148_850cffa0-f440-4feb-b85f-6d014f9c6c3f
Total jobs = 1
Execution completed successfully
MapredLocal task succeeded
Launching Job 1 out of 1
Number of reduce tasks is set to 0 since there's no reduce operator
Starting Job = job_1606698967173_0105, Tracking URL = http://hp1:8088/proxy/application_1606698967173_0105/
Kill Command = /opt/cloudera/parcels/CDH-6.3.1-1.cdh6.3.1.p0.1470567/lib/hadoop/bin/hadoop job -kill job_1606698967173_0105
Hadoop job information for Stage-3: number of mappers: 2; number of reducers: 0
2020-12-04 19:02:03,141 Stage-3 map = 0%, reduce = 0%
2020-12-04 19:02:09,326 Stage-3 map = 100%, reduce = 0%, Cumulative CPU 6.04 sec
MapReduce Total cumulative CPU time: 6 seconds 40 msec
Ended Job = job_1606698967173_0105
MapReduce Jobs Launched:
Stage-Stage-3: Map: 2 Cumulative CPU: 6.04 sec HDFS Read: 13009 HDFS Write: 191 HDFS EC Read: 0 SUCCESS
Total MapReduce CPU Time Spent: 6 seconds 40 msec
OK
t1.id id2
NULL 3
Time taken: 22.345 seconds, Fetched: 1 row(s)
hive>
3.7 右连接 --求B的全部
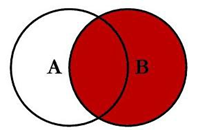
select t1.id,t2.id id2
from t1
right join t2
on t1.id = t2.id;
hive> select t1.id,t2.id id2
> from t1
> right join t2
> on t1.id = t2.id;
Query ID = root_20201204190106_2d049d88-62e4-4e51-88e4-f005248cff60
Total jobs = 1
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/cloudera/parcels/CDH-6.3.1-1.cdh6.3.1.p0.1470567/jars/log4j-slf4j-impl-2.8.2.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/cloudera/parcels/CDH-6.3.1-1.cdh6.3.1.p0.1470567/jars/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
2020-12-04 19:01:12 Starting to launch local task to process map join; maximum memory = 1908932608
2020-12-04 19:01:13 Dump the side-table for tag: 0 with group count: 2 into file: file:/tmp/root/e8ed4bca-fbbf-4db0-b223-33d23b3bbc3a/hive_2020-12-04_19-01-06_491_8753533712871347988-1/-local-10003/HashTable-Stage-3/MapJoin-mapfile40--.hashtable
Execution completed successfully
MapredLocal task succeeded
Launching Job 1 out of 1
Number of reduce tasks is set to 0 since there's no reduce operator
Starting Job = job_1606698967173_0104, Tracking URL = http://hp1:8088/proxy/application_1606698967173_0104/
Kill Command = /opt/cloudera/parcels/CDH-6.3.1-1.cdh6.3.1.p0.1470567/lib/hadoop/bin/hadoop job -kill job_1606698967173_0104
Hadoop job information for Stage-3: number of mappers: 2; number of reducers: 0
2020-12-04 19:01:20,696 Stage-3 map = 0%, reduce = 0%
2020-12-04 19:01:26,882 Stage-3 map = 50%, reduce = 0%, Cumulative CPU 1.97 sec
2020-12-04 19:01:27,911 Stage-3 map = 100%, reduce = 0%, Cumulative CPU 3.95 sec
MapReduce Total cumulative CPU time: 3 seconds 950 msec
Ended Job = job_1606698967173_0104
MapReduce Jobs Launched:
Stage-Stage-3: Map: 2 Cumulative CPU: 3.95 sec HDFS Read: 12061 HDFS Write: 207 HDFS EC Read: 0 SUCCESS
Total MapReduce CPU Time Spent: 3 seconds 950 msec
OK
t1.id id2
2 2
NULL 3
Time taken: 22.507 seconds, Fetched: 2 row(s)
hive>
3.8 left semi join
对于一对多的情况下,经常使用in 和exists,在hive里面其实也可以使用left semi join
SELECT a.* FROM a WHERE a.key IN
(SELECT b.key FROM b WHERE b.value > 100)
等价于
SELECT a.* FROM a LEFT SEMI JOIN b ON
(a.key = b.key AND b.value > 100)
四.排序子句
排序子句有
1) ORDER BY
与传统RDBMS SQL语义一致,对结果集全局排序
对于MapReduce的实现,是需要将结果集shuffle到一个reducer
如果数据量非常大,则会导致reducer执行时间非常长
通常会加LIMIT来限制排序结果的数量
2) SORT BY
Hive特有,reducer本地排序,而非全局排序
当reducer = 1时,与Order By语义相同,否则得到的结果集不同
3) DISTRIBUTE BY
控制map输出的shuffle key
默认是按照key的hashcode
一般用于控制将相同key的数据shuffle到同一个reducer
4) CLUSTER BY
等于DISTRIBUTE BY … SORT BY …
DISTRIBUTE BY 和 SORT BY的字段相同,并正序排序
五.抽样(TABLESAMPLE)
当数据量特别大时,对全体数据进行处理存在困难时,抽样就显得尤其重要了。抽样可以从被抽取的数据中估计和推断出整体的特性,是科学实验、质量检验、社会调查普遍采用的一种经济有效的工作和研究方法。
Hive支持桶表抽样和块抽样。所谓桶表指的是在创建表时使用CLUSTERED BY子句创建了桶的表。桶表抽样的语法如下:
table_sample: TABLESAMPLE (BUCKET x OUT OF y [ON colname])
TABLESAMPLE子句允许用户编写用于数据抽样而不是整个表的查询,该子句出现FROM子句中,可用于任何表中。桶编号从1开始,colname表明抽取样本的列,可以是非分区列中的任意一列,或者使用rand()表明在整个行中抽取样本而不是单个列。在colname上分桶的行随机进入1到y个桶中,返回属于桶x的行。下面的例子中,返回32个桶中的第3个桶中的行:
SELECT *
FROM source TABLESAMPLE(BUCKET 3 OUT OF 32 ON rand()) s;
通常情况下,TABLESAMPLE将会扫描整个表然后抽取样本,显然这种做法效率不是很高。替代方法是,由于在使用CLUSTERED BY时指定了分桶的列,如果抽样时TABLESAMPLE子句中指定的列匹配CLUSTERED BY子句中的列,TABLESAMPLE只扫描表中要求的分区。假如上面的例子中,source表在创建时使用了CLUSTEREDBY id INTO 32 BUCKETS,那么下面的语句将返回第3个和第19个簇中的行,因为每个桶由(32/16)=2个簇组成。为什么是3和19呢,因为要返回的是第3个桶,而每个桶由原来的2个簇组成,第3个桶就由原来的第3个和19个簇组成,根据简单的哈希算法(3%16=19%16)。
TABLESAMPLE(BUCKET 3 OUT OF 16 ON id)
相反,下面的语句将会返回第3个簇的一半,因为每个桶由(32/64)=1/2个簇组成。
TABLESAMPLE(BUCKET 3 OUT OF 64 ON id)
从Hive-0.8开始可以使用块抽样,语法为:
block_sample: TABLESAMPLE (n PERCENT)
该语句允许抽取数据大小的至少n%(不是行数,而是数据大小)做为输入,支持CombineHiveInputFormat而一些特殊的压缩格式是不能够被处理的,如果抽样失败,MapReduce作业的输入将是整个表。由于在HDFS块层级进行抽样,所以抽样粒度为块的大小,例如如果块大小为256MB,即使输入的n%仅为100MB,也会得到256MB的数据。下面的例子中输入的0.1%或更多将用于查询:
SELECT *
ROM source TABLESAMPLE(0.1 PERCENT) s;
如果希望在不同的块中抽取相同的数据,可以改变下面的参数:
set hive.sample.seednumber=<INTEGER>;
也可以指定读取数据的长度,该方法与PERCENT抽样具有一样的限制,为什么有相同的限制,是因为该语法仅将百分比改为了具体值,但没有改变基于块抽样这一前提条件。该语法为:
block_sample: TABLESAMPLE (ByteLengthLiteral)
ByteLengthLiteral : (Digit)+ ('b' | 'B' | 'k' | 'K' | 'm' | 'M' | 'g' | 'G')
下面的例子中输入的100M或更多将用于查询:
SELECT *
FROM source TABLESAMPLE(100M) s;
Hive也支持基于行数的输入限制,当效果与上面介绍的两个不同。首先不需要CombineHiveInputFormat,这意味着可以被用在非原生表中。其次行数被用在每个split中。因此总的行数根据输入的split数而变化很大。语法格式为:
block_sample: TABLESAMPLE (n ROWS)
例如下面的查询将从每个split中抽取10行:
SELECT * FROM source TABLESAMPLE(10 ROWS);
参考:
1.https://cwiki.apache.org/confluence/display/Hive/LanguageManual+Select















 6245
6245











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









