










文章目录
一. 神经网络模型的概述
1.1 什么是人工神经网络模型
人工神经网络(Artificial Neural Network, ANN)没有一个严格的正式定义。它的基本特点,是试图模仿大脑的神经元之间传递,处理信息的模式。
一个计算模型,要被称为为神经网络,通常需要大量彼此连接的节点 (也称 ‘神经元’),并且具备两个特性:
- 每个神经元,通过某种特定的输出函数 (也叫激励函数 activation function),计算处理来自其它相邻神经元的加权输入值
- 神经元之间的信息传递的强度,用所谓加权值来定义,算法会不断自我学习,调整这个加权值
**总结:**神经网络算法的核心就是:计算、连接、评估、纠错、学习
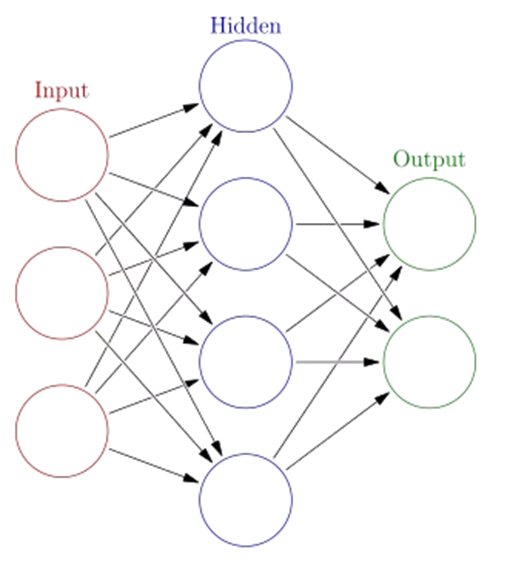
1.2 ANN的类型
ANN类型的划分主要考虑网络连接的拓扑结构、神经元的特征、学习规则等。目前,已有近40种神经网络模型,其中有反传网络、感知器、自组织映射、Hopfield网络、波耳兹曼机、适应谐振理论等。根据连接的拓扑结构,神经网络模型可以分为:
-
前向网络
网络中各个神经元接受前一级的输入,并输出到下一级,网络中没有反馈,可以用一个有向无环路图表示。这种网络实现信号从输入空间到输出空间的变换,它的信息处理能力来自于简单非线性函数的多次复合。网络结构简单,易于实现。反传网络是一种典型的前向网络。 -
反馈网络
网络内神经元间有反馈,可以用一个无向的完备图表示。这种神经网络的信息处理是状态的变换,可以用动力学系统理论处理。系统的稳定性与联想记忆功能有密切关系。Hopfield网络、波耳兹曼机均属于这种类型。
1.3 ANN的一个结构样例
单层感知机是最简单的ANN模型
二类分类的线性分类模型,其输入为样本的特征向量,输出为样本的类别,取1和0二值,即通过某样本的特征,就可以准确判断该样本属于哪一类
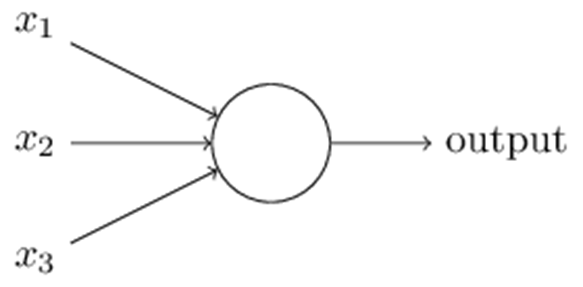

二. 激活函数与损失函数
2.1 激活函数
用于处理复杂的非线性分类情况。比线性回归、logistic回归灵活。训练的时候注意过拟合。
非线性激活函数
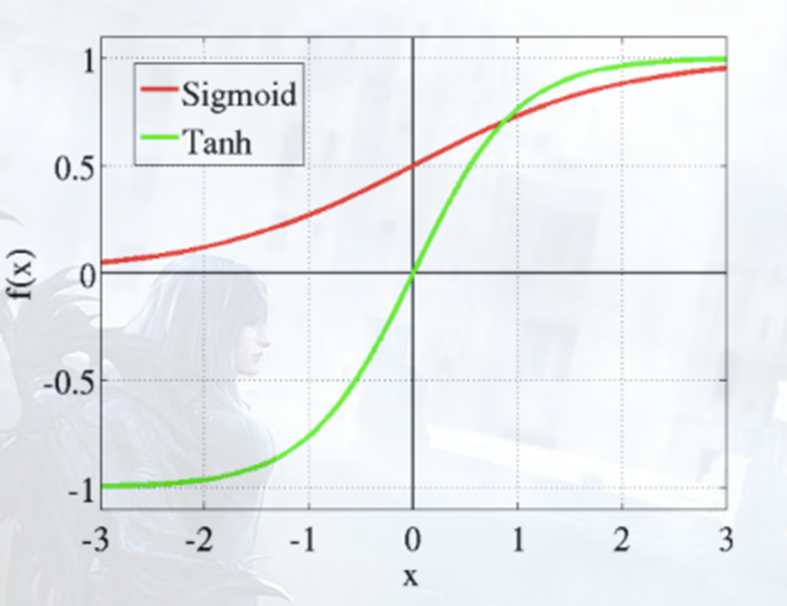
2.1.1 Sigmoid
𝑓(𝑥)=1/(1+exp(−𝑥))
特点:
- 当x趋近负无穷时,y趋近于0;趋近于正无穷时,y趋近于1;
- x超出[-6,6]的范围后,函数值基本上没有变化,值非常接近0或者1
- 该函数的值域范围限制在(0,1)之间,这样sigmoid函数就能与一个概率分布联系起来了。
- 𝑓 ′ ( 𝑥 ) = 𝑓 ( 𝑥 ) ( 1 − 𝑓 ( 𝑥 ) ) 𝑓^′ (𝑥)=𝑓(𝑥)(1−𝑓(𝑥)) f′(x)=f(x)(1−f(x))
2.1.2 双曲正切
t a n h ( 𝑥 ) = ( 𝑒 𝑥 − 𝑒 ( − 𝑥 ) ) / ( 𝑒 𝑥 + 𝑒 ( − 𝑥 ) ) tanh(𝑥)=(𝑒^𝑥−𝑒^(−𝑥))/(𝑒^𝑥+𝑒^(−𝑥) ) tanh(x)=(ex−e(−x))/(ex+e(−x))
特点:
- 当x趋近负无穷时,y趋近于-1;趋近于正无穷时,y趋近于1;
- x超出[-3,3]的范围后,函数值基本上没有变化,值非常接近-1或者1
- 该函数的值域范围限制在(-1,1)之间
- t a n h ′ ( 𝑥 ) = 1 − t a n h ( x ) 2 tanh^′ (𝑥)=1−tanh(x)^2 tanh′(x)=1−tanh(x)2
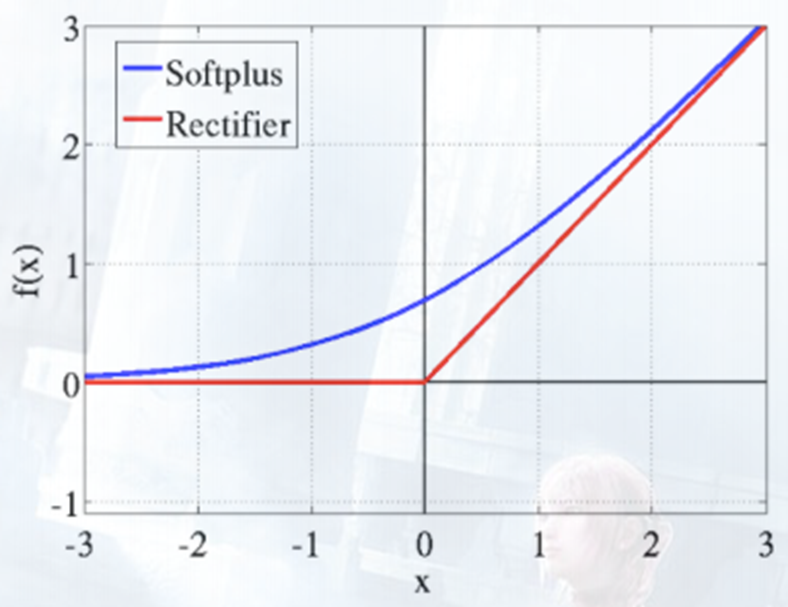
2.1.3 修正线性单元Rectifier Linear Units(ReLU)
𝑓 ( 𝑥 ) = m a x ( 0 , 𝑥 ) 𝑓(𝑥)=max(0,𝑥) f(x)=max(0,x)
特点:
- 只有有一半隐含层是处于激活状态,其余都是输出为0
- 不会出现梯度消失的问题(即在sigmoid接近饱和区时,导数趋于0,这种情况会造成信息丢失)
- 只需比较、乘加运算,因此计算方便,计算速度快,加速了网络的训练
- ReLU比sigmoid更接近生物学的激活模型
- 还有一些改进或的变体
2.1.4 Softplus
𝑓 ( 𝑥 ) = l o g ( 1 + 𝑒 𝑥 ) 𝑓(𝑥)=log(1+𝑒^𝑥 ) f(x)=log(1+ex)
特点:
- x趋于负无穷时,softplus趋于0;x趋于正无穷时, softplus趋于x
- 它是ReLU的平滑版
- 它是sigmoid的原函数
2.1.5 激活函数对比
Sigmoid & Tanh
Softplus & Relu
2.2 损失函数
常见的损失函数
用于回归中的均方损失:
KaTeX parse error: Expected 'EOF', got '̂' at position 15: 𝐸=1/2 (𝑦−𝑦 ̲̂ )^2
用于分类中的交叉熵损失函数:
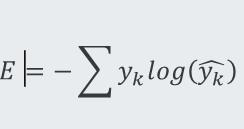
k=1,2,…,m表示m种类别。在违约预测中m=2
关于交叉熵的简单说明

三. 反向传播法
前向神经网络的计算是前向传播,即信息沿着输入层->隐藏层1->隐藏层2->… ->输出层的路线由前往后。一次传播后,输出层的结果与真实标签存在在一定的误差。此时可以根据误差的结果对每一层的权值进行调整,调整的原则是使得在当前结构下,调优后最终的输出与标签的误差“最小化”。
由于神经网络的层级的特点,每一层节点的权值都会对最后的误差产生影响;反之,得到误差后每一层节点的权值都要进行修正。和之前介绍的逻辑回归模型一样,权值修正的方法也是梯度法,即
更新的权值=当前权值-误差梯度*学习速率
下面以带一个隐藏层的神经网络结构为例介绍权值调整的方法。多隐藏层的调整方法类似。
3.1 变量、节点、权重的标记
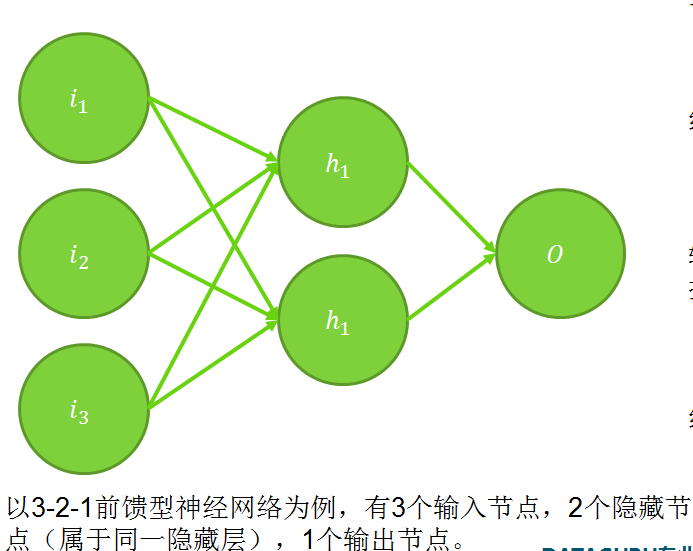

3.2 链式求导



3.3 梯度消失与梯度爆炸

3.4 梯度消失与梯度爆炸的解决办法
方案1: 梯度剪切、正则
这个方案主要是针对梯度爆炸提出的,其思想是设置一个梯度剪切阈值,然后更新梯度的时候,如果梯度超过这个阈值,那么就将其强制限制在这个范围之内这可以防止梯度爆炸。
方案2: ReLU等激活函数
ReLU激活函数的导数为1,因此不存在梯度消失爆炸的问题了,每层的网络都可以得到相同的更新速度
方案3: batchnorm
全名是batch normalization,简称BN,即批规范化,通过规范化操作将输出信号x规范化保证网络的稳定性。 BN就是通过对每一层的输出规范为均值和方差一致的方法,消除了带来的放大缩小的影响,进而解决梯度消失和爆炸的问题,或者可以理解为BN将输出从饱和区拉倒了非饱和区。
More:其他一些复杂的结构:残差结构、LSTM等
参考:
- http://www.dataguru.cn/mycourse.php?mod=intro&lessonid=1701















 3289
3289











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









