







话接上篇,自动化处理 PDF 文档,完美实现 WPS 会员功能
小伙伴们更关心的是如何去除 PDF 中的水印~
今天,就来分享一个超简单的 PDF 去水印方法~
1. 原理介绍
在上一篇中,我们介绍了如何将 PDF 文档转换成图片,图片就是 RGB 三通道像素点的集合。
我们发现:水印的像素点和正常文字的像素点是有显著区别的。
如何查看水印的像素是多少呢?
最简单的方式是打开一个截图工具,聚焦到水印位置即可看到:

所以,水印的像素值有如下特点:
- 像素分布在 180 - 250 (注:必要时,阈值需适当调整);
- RGB三通道的像素值基本相同。
基于上述两个特点,我们就可以找到水印像素点的位置。
2. 代码实操
为了完美实现上述的两个判断,当然你可以写两层 for 循环遍历像素值进行判断,不过一旦图像尺寸太大,处理速度就令人抓狂了。
最简单的方式就是采用 numpy 数组进行操作:
import numpy as np
def judege_wm(img, low=180, high=250):
# 通过像素判断
low_bound = np.array([low, low, low])
high_bound = np.array([high, high, high])
mask = (img > low_bound) & (img < high_bound) & (np.abs(img-img.mean(-1, keepdims=True)).sum(-1, keepdims=True) < 10) # 要求rgb值相差不能太大
img[mask] = 255
return img
最后,我们来看下处理后的效果:
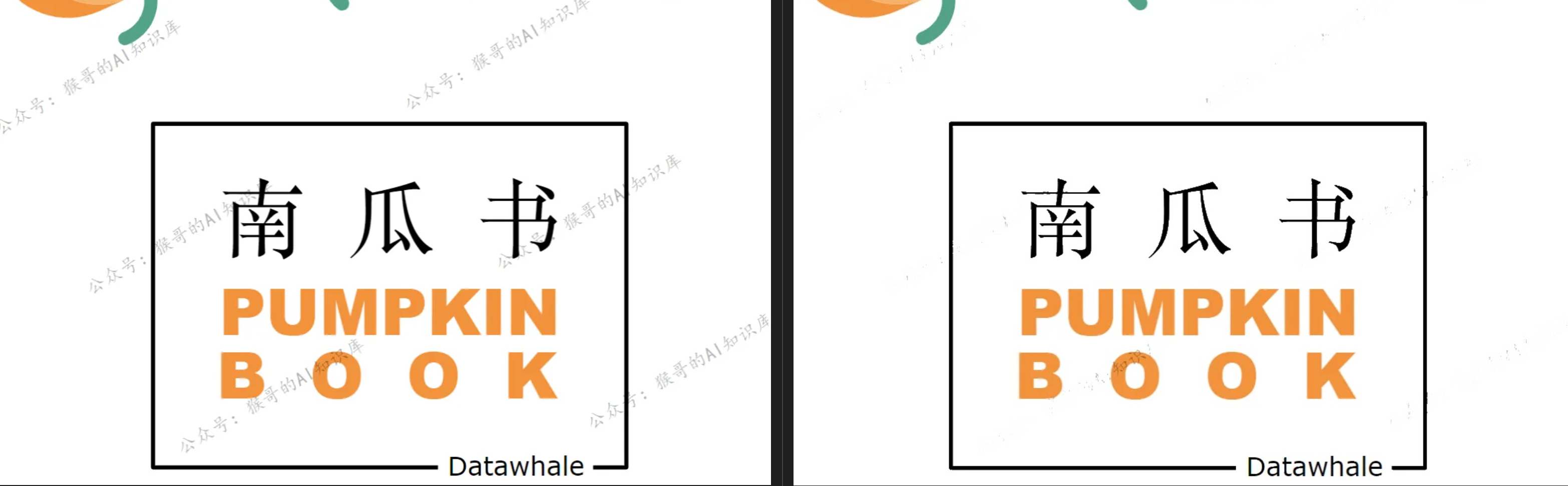
3. 整体流程
上述步骤,我们介绍了如何去除图片中的水印。
说好的 PDF 去水印呢?
来,参照下述流程走一遍:

关于如何实现:PDF转换成图片 以及 图片转换成PDF,上篇已经给出了详细教程:自动化处理 PDF 文档,完美实现 WPS 会员功能
写在最后
本文给大家带来了一种最简单的图片 & PDF 去水印方法,可以满足绝大部分白底黑字的文档场景。
如果背景图像纷繁复杂,本方法还无法完美解决。
欢迎有其他解决方案的小伙伴,评论区交流下啊~
如果本文对你有帮助,欢迎点赞收藏备用。

















 300
300

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









