







前面文章,和大家分享了很多免费开源的 TTS 项目:
- 永久免费语音服务!微软 Azure 注册实操,零成本实现TTS自由
- F5-TTS 开源语音克隆:本地部署实测,2秒复刻你的声音
- 开源最快语音克隆方案,FishSpeech 焕新升级,本地部署实测
- 阿里开源TTS CosyVoice 再升级!语音克隆玩出新花样,支持流式输出
- 最新开源TTS语音克隆,本地部署实测!跨语言、高保真
就体验而言,笔者用的最多的当属:edge-tts FishSpeech 和 CosyVoice
其中,edge-tts 需联网,而 FishSpeech 和 CosyVoice 则需显卡。
有没有端侧可运行的轻量级 TTS 模型?
之前还真发现过一个潜力股:Kokoro,不过当时对中文不太友好,暂且搁置。
最近,Kokoro 上新了,新增 100 种中文音色,且支持中英混合。
这就有必要来聊聊了,希望能为您本地 TTS 选型提供一个参考。
1. Kokoro 简介
一款超轻量级的 TTS 模型,只有 82M 参数。
别看它架构轻巧,音质仍可媲美动辄 0.5B 的大模型。
且看语音合成领域的 TTS Arena 排行榜,荣登榜一,且遥遥领先!
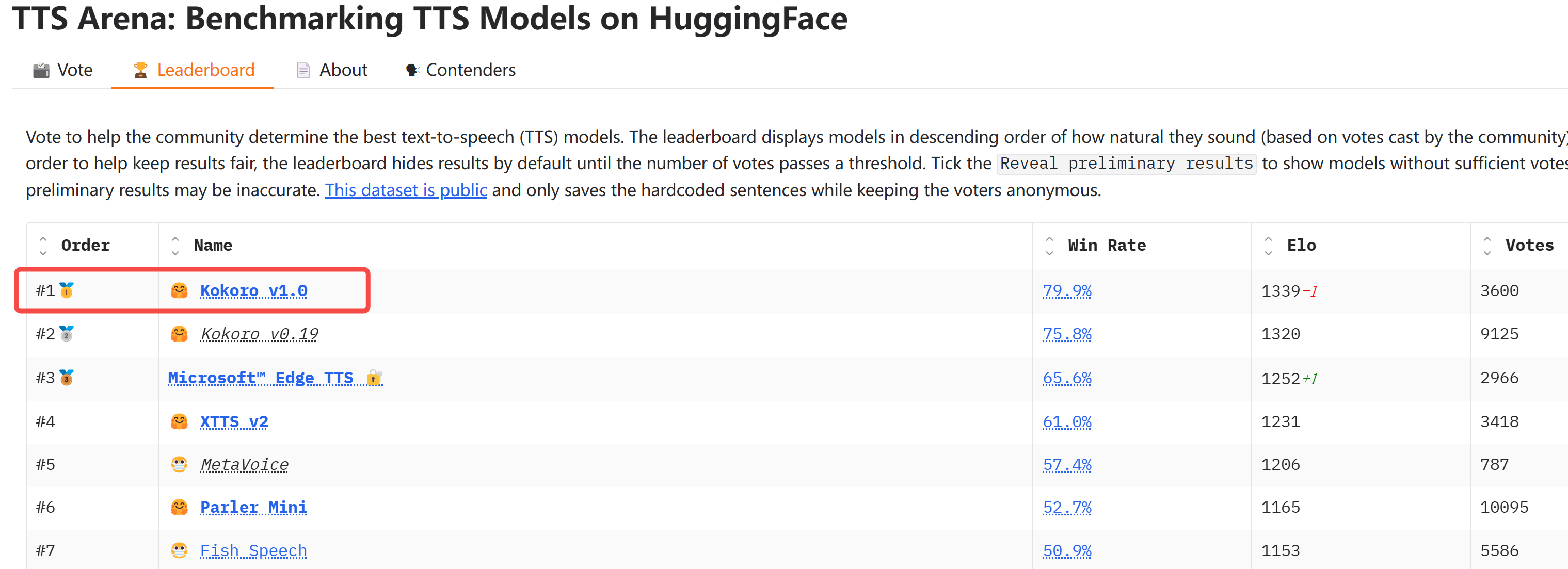
相比 v0.19,v1.0 训练数据规模增加了,支持的音色更多:
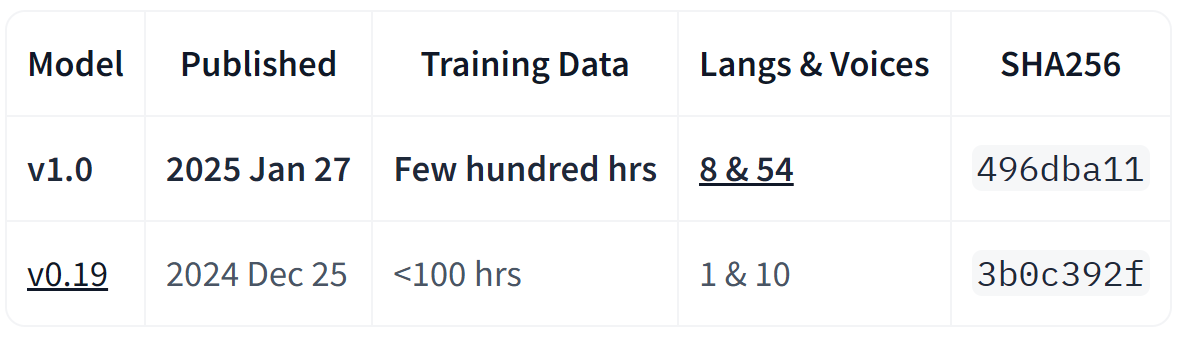
老规矩,简短介绍下亮点:
- 多语言支持:支持中、英、日、法、意大利、葡萄牙、西班牙、印地语共 8 种语言。
- 多音色支持:提供了多种男女人物音色,不断更新中。
- 实时语音生成:CPU上可近乎实时,而在GPU上,则达到了50倍实时速度。
- 自然语音生成:不只是快,生成的语音还超逼真。
1.1 音色地址
Kokoro 的所有音色均以 pt 文件,存放在 huggingface,国内用户可通过以下地址下载:
v1.0:https://hf-mirror.com/hexgrad/Kokoro-82M
v1.1 https://hf-mirror.com/hexgrad/Kokoro-82M-v1.1-zh,新增更多中文音色。
2. Kokoro 实测
2.1 安装依赖
需安装如下依赖:
pip install kokoro
pip install ordered-set
pip install cn2an
pip install pypinyin_dict
2.2 模型和音色下载
从 huggingface 上拉取模型权重,以及音色文件:
export HF_ENDPOINT=https://hf-mirror.com # 引入镜像地址
huggingface-cli download --resume-download hexgrad/Kokoro-82M --local-dir ./ckpts/kokoro-v1.0
huggingface-cli download --resume-download hexgrad/Kokoro-82M-v1.1-zh --local-dir ./ckpts/kokoro-v1.1
2.3 模型推理
下面以中文语音合成为例,进行演示。
kokoro 模型推理,只需以下 4 步~
step 1:引入依赖
import torch
import time
from kokoro import KPipeline, KModel
import soundfile as sf
step 2:加载音色
尽管 kokoro 支持运行时下载音色,不过在 2.2 部分,我们已将音色文件下载到本地,这里直接 load 进来:
voice_zf = "zf_001"
voice_zf_tensor = torch.load(f'ckpts/kokoro-v1.1/voices/{voice_zf}.pt', weights_only=True)
voice_af = 'af_maple'
voice_af_tensor = torch.load(f'ckpts/kokoro-v1.1/voices/{voice_af}.pt', weights_only=True)
step 3:加载模型
repo_id = 'hexgrad/Kokoro-82M-v1.1-zh'
device = 'cuda' if torch.cuda.is_available() else 'cpu'
model_path = 'ckpts/kokoro-v1.1/kokoro-v1_1-zh.pth'
config_path = 'ckpts/kokoro-v1.1/config.json'
model = KModel(model=model_path, config=config_path, repo_id=repo_id).to(device).eval()
step 4:开始推理
zh_pipeline = KPipeline(lang_code='z', repo_id=repo_id, model=model)
sentence = '如果您愿意帮助进一步完成这一使命,请考虑为此贡献许可的音频数据。'
start_time = time.time()
generator = zh_pipeline(sentence, voice=voice_zf_tensor, speed=speed_callable)
result = next(generator)
wav = result.audio
speech_len = len(wav) / 24000
print('yield speech len {}, rtf {}'.format(speech_len, (time.time() - start_time) / speech_len))
sf.write('output.wav', wav, 24000)
其中,speed 支持 float 类型的语速控制,speed_callable为官方提供的默认回调函数(主要和训练数据有关):
def speed_callable(len_ps):
speed = 0.8
if len_ps <= 83:
speed = 1
elif len_ps < 183:
speed = 1 - (len_ps - 83) / 500
return speed * 1.1
对于中英混杂的文本,需要在 KPipeline 中增加 en_callable 回调函数,并传入英文音色,如下:
en_pipeline = KPipeline(lang_code='a', repo_id=repo_id, model=model)
def en_callable(text):
if text == 'Kokoro':
return 'kˈOkəɹO'
elif text == 'Sol':
return 'sˈOl'
return next(en_pipeline(text, voice=voice_zf_tensor)).phonemes
zh_pipeline = KPipeline(lang_code='z', repo_id=repo_id, model=model, en_callable=en_callable)
最后,来听听合成效果:
中文语音合成:
如果您愿意帮助进一步完成这一使命,请考虑为此贡献许可的音频数据。
中英混语合成:
该 Apache 许可模式也符合 OpenAI 所宣称的广泛传播 AI 优势的使命。
2.4 速度测试
GPU 推理显存占用:
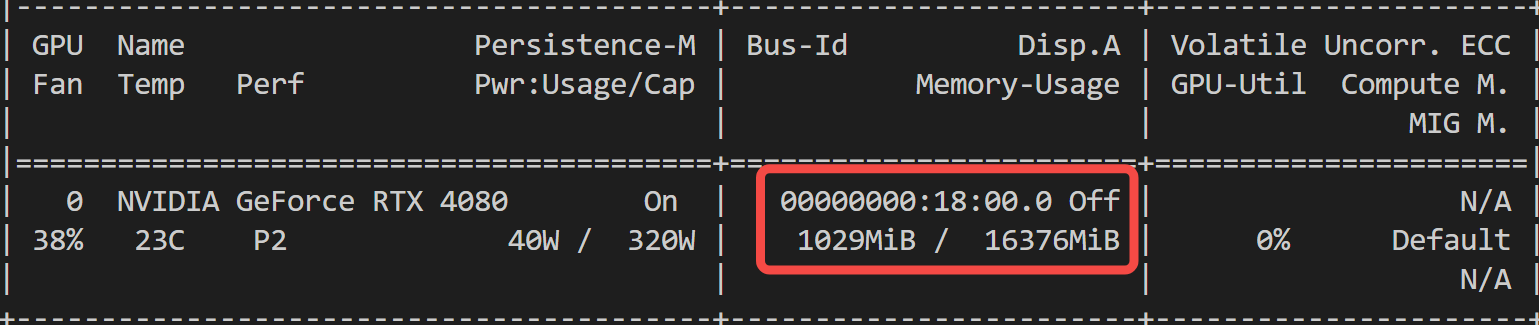
TTS 通用的速度评估指标为 rtf,也即 推理耗时/生成音频耗时,指标越低,代表推理速度越快!
kokoro GPU 推理:
yield speech len 6.825, rtf 0.2680429521497789
kokoro CPU 推理:
yield speech len 6.825, rtf 0.4242438012427026
可以发现,即便是 CPU 推理,rtf 依然远小于 1,强啊!
2.5 服务端部署
下面我们采用 FastAPI 完成服务部署。(完整代码,可在文末自取)
首先,定义数据模型,用于接收POST请求中的数据:
class TTSRequest(BaseModel):
tts_text: str # 待合成的文本
voice_id: Optional[str] = "zf_001" # 参考语音的id
speed: Optional[float] = None # 语速
接口功能函数:
@app.post('/tts')
def tts(request: TTSRequest):
voice_path = f'ckpts/kokoro-v1.1/voices/{request.voice_id}.pt'
if not os.path.exists(voice_path):
return JSONResponse(status_code=400, content={"error": "voice_id not found"})
voice_tensor = torch.load(voice_path, weights_only=True)
speed = speed_callable if request.speed is None else request.speed
generator = zh_pipeline(request.tts_text, voice=voice_tensor, speed=speed)
result = next(generator)
wav = result.audio.cpu().numpy()
wav = (wav * 32767).astype(np.int16)
wav_bytes = io.BytesIO()
wav_bytes.write(wav.tobytes())
wav_bytes.seek(0)
return StreamingResponse(wav_bytes, media_type='audio/pcm', headers=headers)
注意:模型原始输出为 torch.tensor,可转成 int16 以 pcm 格式输出。
最后,启动服务:
nohup uvicorn server:app --host 0.0.0.0 --port 3008 > server.log 2>&1 &
echo "Server started"
客户端测试代码:
def test():
data = {
'tts_text': '2024年12月21日,你好,欢迎使用语音合成服务,共收录2000余种语言。',
}
response = requests.post(f"{url}/tts", json=data)
pcm2wav(response.content)
对于数字播报这一老大难问题,kokoro 也能轻松拿捏,来听效果:
就凭这,kokoro 吊打一众 TTS 巨无霸模型!
写在最后
本文分享了轻量级语音合成工具:kokoro,并进行了本地部署实测。
有一说一,抛开语气 情绪等细粒度控制不谈,kokoro 绝对的性价比之王!
对中文支持友好,CPU 实时可跑,单凭这两点,强烈推荐您一试!
如果对你有帮助,欢迎点赞收藏备用。
本文服务部署代码已上传云盘,需要的朋友,公众号后台回复kokoro自取!
为方便大家交流,新建了一个 AI 交流群,公众号后台「联系我」,拉你进群。

















 429
429

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









