







前两天,搞了个微信 AI 小助理,爸妈玩的不亦乐乎。
有朋友问,还能干点啥?
可玩的花样可多了~
最近关注的公众号有点多,根本看不完。我在想:把链接丢给小助理,让它帮我把文章大纲整理出来,这样岂不双赢:既不会遗漏重要内容,又节省了大量时间。
说干就干!
前两篇整体框架已经搭建好了,现在做的无非就是给小助理装上三头六臂!
本文将手把手带大家,实现小助理的 AI 摘要功能。
整个过程只需 4 步:
- 获取微信公众号文章链接;
- 爬取文章内容;
- 编写提示词,调用 LLM 进行总结;
- 调用发送消息接口,返回摘要内容。
话不多说,上实操!
友情提醒:注册小号使用,严禁用于违法用途(如发送广告/群发/诈骗、色情、政治等内容),否则封号是早晚的事哦。
1. 获取文章链接
微信公众号文章转发到微信,消息类型是 urlLink。
为此,只需要在上篇处理消息的逻辑基础上,修改下路由,单独处理urlLink类型的消息:
def handle_message(message_type='text', content='', source='', is_from_self="0"):
if is_from_self == "1":
return
if message_type == "text":
bot_answer = handle_text(content)
if message_type == "urlLink":
bot_answer = handle_url(content)
消息内容 content 中有一个 url 字段,这就是文章链接。
拿到文章链接,我们就可以写一个爬虫,爬取文章完整内容。
2. 爬取文章内容
爬取文章内容的方式有很多。
之前给大家分享 dify 使用教程 时,用过firecrawl这个爬虫插件,把网页自动转存为 markdown 内容,非常方便,免费用户有使用额度。
如果不想装整个插件,那么我们完全可以自己动手,写一个简单的爬虫!
只需要用到requests和bs4即可:
import requests
from bs4 import BeautifulSoup
response = requests.get(url, headers=headers)
soup = BeautifulSoup(response.text, 'html.parser')
content = soup.find('div', attrs={'id': 'js_content'}) # html文件
上面得到的内容是 html 格式,当然直接把它送给 LLM 也是没问题的。
如果吝啬你宝贵的 Token 资源,那么强烈建议你用上这个库:html2text,一键将html 转存成 markdown。
import html2text
h = html2text.HTML2Text()
markdown_content = h.handle(str(content))
有了文章内容,接下来我们送给 LLM,让它给提炼出文章大纲。
3. 调用 LLM 进行总结
直接丢给 LLM 么?
当然可以,但如果希望得到的结果可控且可靠,最好设计下角色提示词。
下面是我针对这个任务,编写的提示词,供小伙伴们参考:
sys_prompt_kp = '''
- Role: 文章分析专家
- Background: 用户需要对一篇给定的文章进行关键点总结,并生成文章的大纲。
- Profile: 你是一位经验丰富的编辑,擅长提炼文章核心思想和结构化信息。
- Skills: 文章阅读、关键点提取、信息组织、大纲创建。
- Goals: 帮助用户从文章中提取关键点,并生成清晰的大纲。
- Constrains: 确保大纲简洁明了,覆盖文章所有主要观点。
- OutputFormat: 文章大纲,以列表形式呈现。
- Workflow:
1. 阅读并理解文章内容。
2. 提取文章中的关键点和主要论点。
3. 根据提取的关键点创建文章大纲。
4. 只输出markdown格式的文章大纲,不要回答其他任何内容。
'''
来吧,这下应该没什么问题了:
def article_summary(data, model_name='gemini-1.5-pro'):
messages = [
{'role': 'system', 'content': sys_prompt_kp},
{'role': 'user', 'content': data['content']},
]
summary = unillm(model_name, messages)
return summary
4. 调用发送消息接口
最后,我们把上面两个函数打包一下:
def handle_url(content='', url=''):
# 处理公众号链接
if content:
content = json.loads(content)
url = content['url']
if 'weixin.qq.com' in url:
data = get_gzh_article(url, content_only=False)
else:
data = {}
summary = article_summary(data, model_name='gemini-1.5-flash')
return summary
一旦判定消息类型为 urlLink,直接调用上面的 handle_url 进行处理,并将结果用上篇提到的发送消息接口进行返回。
注:后面发现,转发文章中的链接,简单的爬虫无法搞定:当前环境异常,完成验证后即可继续访问。
所以:退而求其次,直接发送原文链接。
暂且先这么搞吧,小伙伴有其它方法的,欢迎评论区交流。
5. 看看效果吧
先找一篇技术干货,把之前写的 Ollama 教程发给它:本地部署大模型?Ollama 部署和实战,看这篇就够了
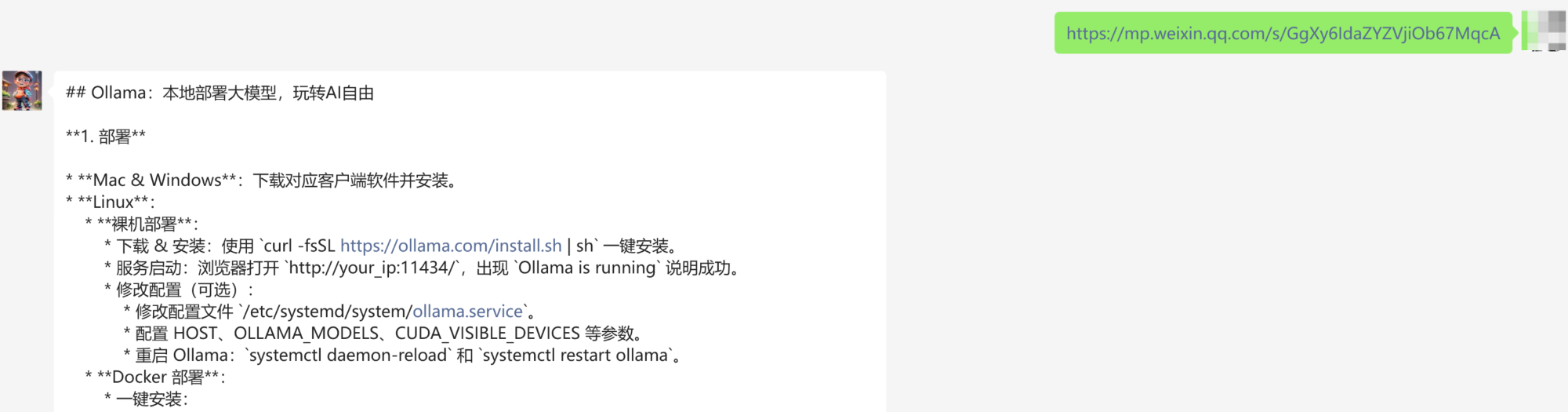
再来一篇宣传软文:
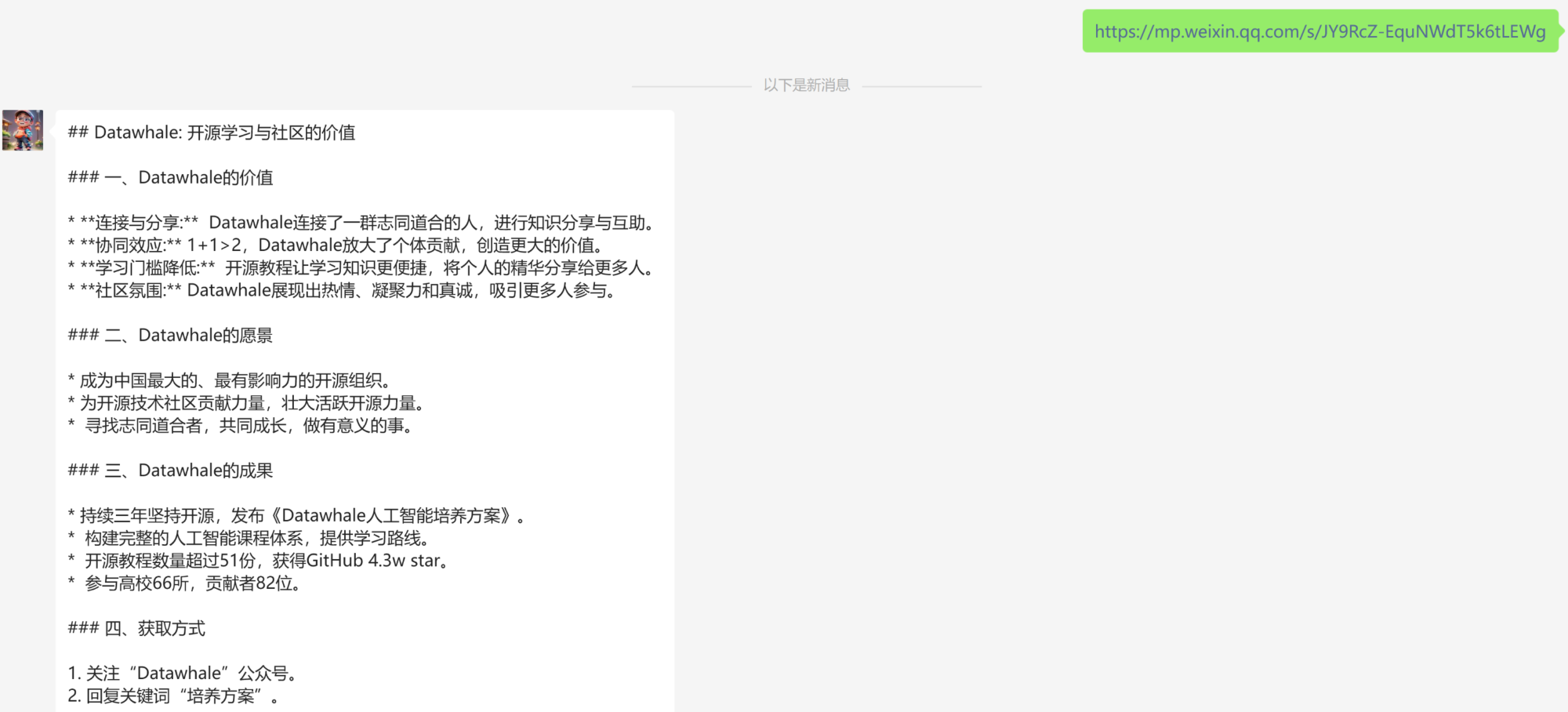
怎么样?
写在最后
终于,给小爱装上了阅读理解神器,以后再也不用担心错过重要文章了。
不管是硬核技术文还是软萌广告文,链接丢给它,精华吐出来。
我不想读,但我想知道的必备神器!
当然,小爱还有无限想象空间,之前部署了很多 AI 服务,我打算慢慢接进来,把小爱打造成身边的超级助理!
大家有什么需求 or 想法,欢迎评论区交流。
如果本文对你有帮助,不妨点个免费的赞和收藏备用。
为了方便大家交流,新建了一个 AI 交流群,欢迎感兴趣的小伙伴加入。
小爱也在群里,想进群体验的朋友,公众号后台「联系我」即可,拉你进群。

















 2333
2333

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









