







前几篇,分享了低延迟小智AI服务端搭建的 ASR 和 LLM 部分:
从实测来看:
-
当采用音频流式输入,VAD + ASR 部分的延时几乎可忽略。
-
LLM 采用流式推理,延时在 0.3-0.5s。
接下来,压力给到 TTS 部分。
本篇,继续实测 TTS 流式推理,聊聊如何把延时降到最低。
1. 技术方案选型
和 LLM 一样,TTS 也有两种方案:
- 本地部署:
支持流式推理的开源模型,相比 LLM,对 GPU 要求没那么高,成本可控。 - 在线 API:音色丰富,按需付费,不过价格并不便宜(下文测算)。
对于本地部署而言,笔者之前分享过两款支持流式推理的开源模型:
- fishspeech-1.5:速度超快,显存占用低(性价比之王)。
- cosyvocie-2:音质更优,显存占用高。
其中,cosyvocie-2 经过一定优化,同样可以做到 rtf < 1,不过首帧延时依然是硬伤。
关于更多支持流式推理的开源模型,欢迎评论区聊!
本篇,重点聊两款 在线 API,并实测首帧延时!
- 阿里百炼-cosyvoice
- 火山引擎-大模型语音合成
其中,小智火爆出圈的台湾腔-湾湾小何,正是来自火山引擎!
2. 流式推理实现
上述两款 API 均支持 websocket 协议调用,支持流式输出。
在测试之前,你需要申请对应的 API key。
阿里云:https://bailian.console.aliyun.com/?tab=model#/api-key
火山引擎:https://console.volcengine.com/speech/app

然后,了解对应的交互逻辑,可参考官方文档:
小智官方仓库也已实现两款 API 的交互逻辑,在此不再赘述。
这里提供一个测试方法:
static test() {
const client = new DashscopeTtsClient();
client.on('ready', () => {
console.log(new Date(), 'TTS服务器就绪。');
const session = client.newSession();
session.on('started', async () => {
console.log(new Date(), 'TTS会话已开始。');
session.write('你好');
session.write('今天的天气真的不错啊');
session.finish();
console.log(new Date(), '已发送 finish');
});
let t = Buffer.alloc(0);
session.on('audio', (audio) => {
console.log(new Date(), '收到', audio.length, '字节');
t = Buffer.concat([t, audio]);
});
session.on('finished', () => {
console.log(new Date(), 'TTS会话已结束。');
client.finishConnection();
const fs = require('fs');
fs.writeFileSync('tts.pcm', t);
console.log('音频数据已写入 tts.pcm,大小:', t.length);
console.log('要播放音频,请运行: ffplay -f s16le -ar 24000 -ac 1 tts.pcm');
});
session.on('sentence_start', (text) => {
console.log('句子开始', text);
});
session.on('sentence_end', (text) => {
console.log('句子结束', text);
});
});
client.on('error', (err) => console.error(new Date(), 'TTS客户端错误:', err));
client.on('close', () => console.log('TTS客户端已关闭'));
}
}
3. 延时实测和成本对比
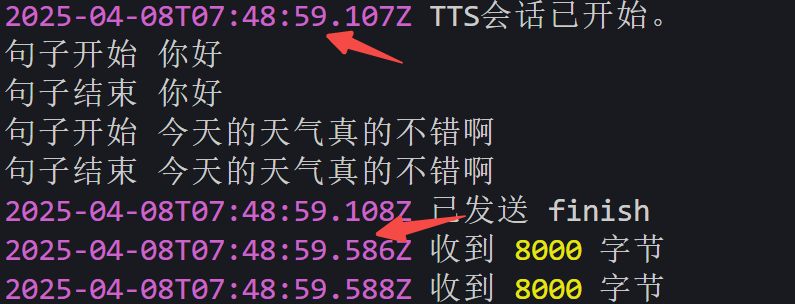
阿里云-cosyvoice 实测:首个包 0.4-0.5s
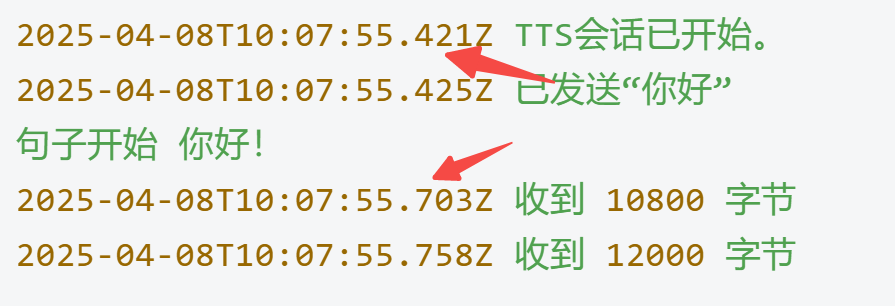
火山引擎-大模型语音合成 实测:首个包 0.3s
再看成本呢?
两家的定价策略还不一样。
- 阿里百炼-cosyvoice:¥2/万字符

- 火山引擎-大模型语音合成:更贵!
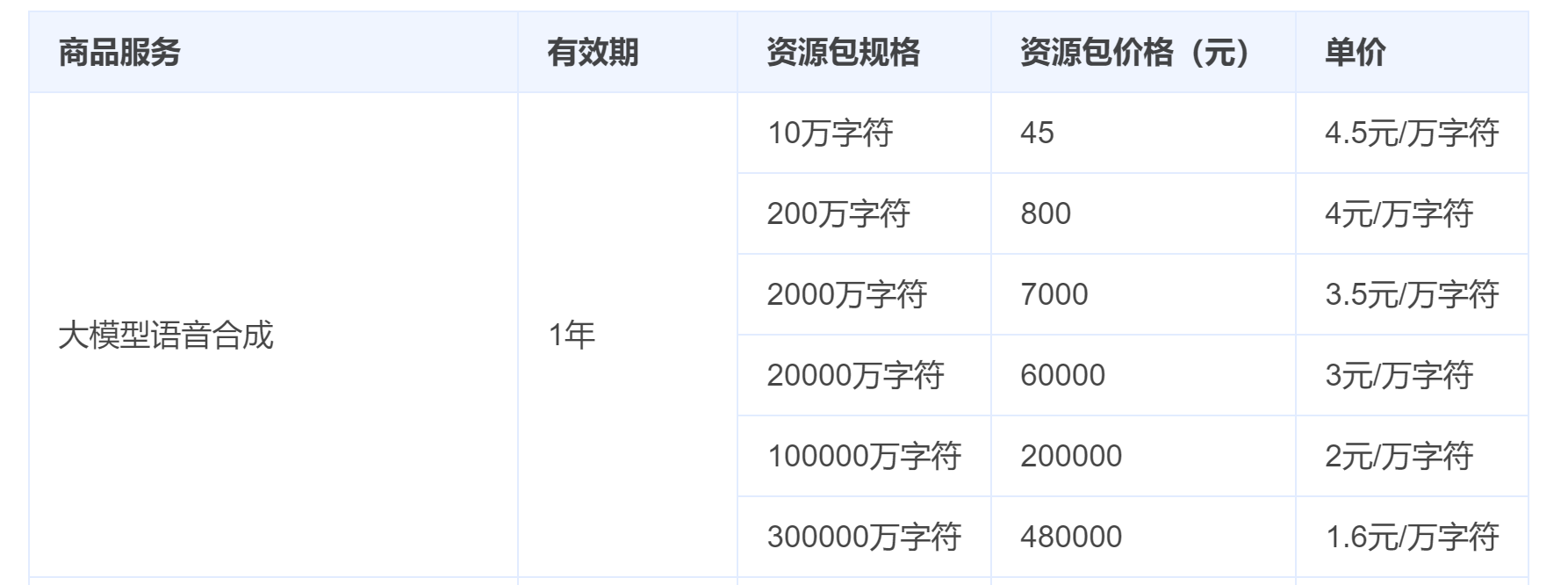
简单讲:充值越多越便宜,但打包出售,设置 1 年有效期!
万字符什么概念?
根据1s=5个字符的计算规则,万字符大约是 0.5 小时的音频输出。
因此,想要自建服务端的朋友,单 TTS 这笔费用,你可省的了?
写在最后
本文分享了小智AI服务端 TTS的实现,对在线 API的延时进行了实测,并简单测算了成本。
综合这两篇:LLM 0.5s + TTS 0.3s。
因此,平均语音响应延迟低于 0.8s 完全没问题。
如果对你有帮助,欢迎点赞收藏备用。
后续,我们将实测几款支持流式推理的 TTS 模型-本地部署,下篇见。
为方便大家交流,新建了一个 AI 交流群,公众号后台「联系我」,拉你进群。

















 596
596

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









