







刚刚学习python的时候在网上看到一位大牛写的关于python教程的文章,里面详细介绍了关于编码的问题,虽然学习了这么久的编程,其实对于编码还是有一点头昏。。。
前段时间搞了一个小项目,处理前端输入的时候,发送的get请求有中文,当时就想应该是编码问题,可是写了好久都没有解决,最后吧输入的中文转成url编码,然后交给后端数据库处理才算勉强的解决了问题,不过对于编码还是没有足够的认识,今天总算是开拓了一下视野,话不多说,先来说一下这几个编码
首先是ascii码,我记得当初学c的时候,老师就说过字符'A'的编码是65,当然这里的编码就是ascii编码,历史上因为美国是计算机的起源地,所以英文和数字,字符最早地被添加进了计算机编码中,也就是美国国家标准组织(ANSI)发布的ascii码表
这是从百度上找来的ascii码表
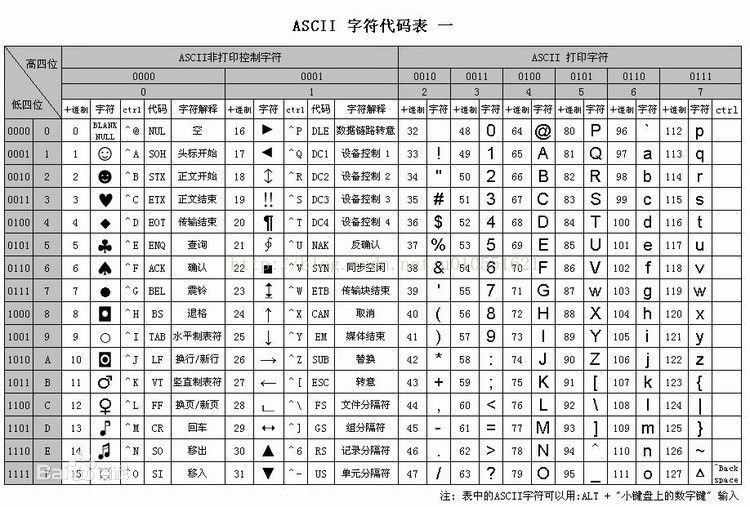
可以看到ascii编码中,每一个字符(数字,字母,符号)用1个字节来表示(8位),这些字符虽然看上去很多(128),但是表示中文,日语,韩语以及一些其他的语言特有的字符,还是有局限
所以unicode编码就应运而生,就是为了解决不同国家语言不同字符的编码混乱问题,其实unicode简单的来说,就是用两个字节来表示一个字符(常用的unicode标准),对于ascii码表中的字符,unicode编码只是在前面加上了8个前导0,这里举一个例子:
比如上图的表中,字符‘6’的ascii编码就是 00110110,那么它对应的unicode编码就是 00000000 00110110,原因就在于unicode编码需要用16位(2个字节)去表示一个字符,所以在某种意义上也可以说字母,数字的ascii编码和unicode编码是相同的(但实际上是不同的,unicode占2个字节,ascii只占1个字节),但是对于其他字符,比如中文字符,显然就没有那么简单了
看到这里的时候,我终于明白为什么unicode编码又称为万国码了(惭愧! 惭愧!)
虽然unicode对于各种语言的字符普遍适用,但是存储空间上的开销同样会增大很多,尤其对于一片英文字母出现较多的文本,这个时候,我们的科学家们又推出了一种可变长编码utf-8
从字面的意思上来说,utf-8就是基于unicode编码的一种再编码(更准确的说是根据unicode编码的数值大小),对于英文字母和数字而言,他们被编码为1个字节,而常规汉字一般是3个字节(有些生僻字符可能需要4-6个字节),如果我门在编程的时候,会涉及到少量中文的输入和输出,utf8编码方式比起unicode就再好不过了,因为它大大地节省了存储空间;另外要说的一点就是,ascii编码包含在utf-8编码中,这是因为unicode转换到utf8的过程中,编码的数值是没有变化的,变化的是所占字节数的多少(2变1)
至此,简单的理清了一下ascii,unicode和utf8的关系
时间短,写得比较糙,希望大家发现有不对的地方积极帮我指出来,一起学习,一起进步!















 1744
1744

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









