这几天无聊,正好想起来以前谁说有同学做人脸识别,感觉好高大上,所以找来一些基础的人脸识别算法来自己实现一下,正好锻炼一下numpy的使用。
特征脸方法基本是将人脸识别推向真正可用的第一种方法,了解一下还是很有必要的。特征脸用到的理论基础PCA我在这里就不说了,百度一大堆,主要讲一下实现步骤和自己在用python实现是发现的问题。这里我所使用的训练图片是YALE的人脸数据库点击打开链接,这里面有15位志愿者的165张图片,包含光照,表情和姿态的变化。(我们做实验的时候就会发现,特征脸算法对光照敏感。)在unpadded文件夹下。每张图片的尺寸是98*116。

特征脸实现步骤(大家如果英语好可以看看这个点击打开链接):
1.获取包含M张人脸图像的集合 。我们这里使用15张xxx.normal.pgm来作为人脸训练图像,所以这里M=15.我们把导入的图像拉平,
。我们这里使用15张xxx.normal.pgm来作为人脸训练图像,所以这里M=15.我们把导入的图像拉平,
本来是98*116的矩阵,我们拉平也就是一个11368*1的矩阵,然后M张放在一个大矩阵下,该矩阵为11368*15。
2.我们计算平均图像 ,并获得偏差矩阵
,并获得偏差矩阵 。为11368*15.平均图像也就把每一行的15个元素平均计算,
。为11368*15.平均图像也就把每一行的15个元素平均计算,
这样最后的平均图像就是一个我们所谓的大众脸。然后每张人脸都减去这个平均图像,最后得到。


3.求得的协方差矩阵。并计算的特征值和特征向量。这是标准的PCA算法流程。但是在这里一个很大的问题就是,协方差矩阵的维度会大到无法计算,例如我们这个11368*15的矩阵,它的协方差矩阵是11368*11368,这个计算量非常大,而且储存也很困难,所以有大神推导出了下面的方法:
设 T 是预处理图像的矩阵,每一列对应一个减去均值图像之后的图像。则,协方差矩阵为 S = TTT ,并且对 S 的特征值分解为
-

然而, TTT 是一个非常大的矩阵。因此,如果转而使用如下的特征值分解
-
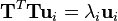
此时,我们发现如果在等式两边乘以T,可得到
-
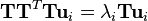
这就意味着,如果 ui 是 TTT的一个特征向量,则 vi = Tui 是 S 的一个特征向量。
看懂上面这一些需要一些线性代数知识,这里的T 就是上面的偏差矩阵, 反正到最后我们得TTT的一个特征向量,再用T与之相乘就是协方差矩阵的特征向量 。而此时我们求的特征向量是11368*15的矩阵,
。而此时我们求的特征向量是11368*15的矩阵,
每一行(11368*1)如果变成图像大小矩阵(98*116)的话,都可以看做是一个新人脸,被称为特征脸。这里展现我试验中的其中一部分。

4.主成分分析。在求得的特征向量和特征值中,越大的特征值对于我们区分越重要,也就是我们说的主成分,我们只需要那些大的特征值对应的特征向量,
而那些十分小甚至为0的特征值对于我们来说,对应的特征向量几乎没有意义。在这里我们通过一个阈值selecthr来控制,当排序后的特征值的一部分相加
大于该阈值时,我们选择这部分特征值对应的特征向量,此时我们剩下的矩阵是11368*M',M'根据情况在变化。 这样我们不仅减少了计算量,而且保留
了主成分,减少了噪声的干扰。
5.这一步就是开始进行人脸识别了。此时我们导入一个新的人脸,我们使用上面主成分分析后得到的特征向量,来求得一个每一个特征向量对于导入人脸的权重向量 。
。

这里的 就是上面第2步求得的平均图像。 特征向量其实就是训练集合的图像与均值图像在该方向上的偏差,通过未知人脸在特征向量的投影,我们就可以知道未知人脸与平均图像在不同方向上的差距。此时我们用上面第2步我们求得的偏差矩阵的每一行做这样的处理,每一行都会得到一个权重向量。我们利用求得
就是上面第2步求得的平均图像。 特征向量其实就是训练集合的图像与均值图像在该方向上的偏差,通过未知人脸在特征向量的投影,我们就可以知道未知人脸与平均图像在不同方向上的差距。此时我们用上面第2步我们求得的偏差矩阵的每一行做这样的处理,每一行都会得到一个权重向量。我们利用求得 与
与 的欧式距离来判断未知人脸与第k张训练人脸之间的差距。
的欧式距离来判断未知人脸与第k张训练人脸之间的差距。

在这里因为我假设我要识别的未知人肯定是训练集合里有的,所以我通过比较 ,选择最小的k就是这个人脸对应的训练集合的脸。实际上,一般都是设定距离阈值,当距离小于阈值时说明要判别的脸和训练集内的第k个脸是同一个人的。当遍历所有训练集都大于阈值时,根据距离值的大小又可分为是新的人脸或者不是人脸的两种情况。根据训练集的不同,阈值设定并不是固定的。
,选择最小的k就是这个人脸对应的训练集合的脸。实际上,一般都是设定距离阈值,当距离小于阈值时说明要判别的脸和训练集内的第k个脸是同一个人的。当遍历所有训练集都大于阈值时,根据距离值的大小又可分为是新的人脸或者不是人脸的两种情况。根据训练集的不同,阈值设定并不是固定的。
最后附上python代码,这里的 ReconginitionVector函数就是求得特征向量的函数,就是按照上面说的顺序写下来的,judgeFace函数用来识别人脸。(大家可以借鉴一下,如果发现有什么不对的欢迎讨论):
-
- from numpy import *
- from numpy import linalg as la
- import cv2
- import os
-
- def loadImageSet(add):
- FaceMat = mat(zeros((15,98*116)))
- j =0
- for i in os.listdir(add):
- if i.split('.')[1] == 'normal':
- try:
- img = cv2.imread(add+i,0)
- except:
- print 'load %s failed'%i
- FaceMat[j,:] = mat(img).flatten()
- j += 1
- return FaceMat
-
- def ReconginitionVector(selecthr = 0.8):
-
- FaceMat = loadImageSet('D:\python/face recongnition\YALE\YALE\unpadded/').T
-
- avgImg = mean(FaceMat,1)
-
- diffTrain = FaceMat-avgImg
-
- eigvals,eigVects = linalg.eig(mat(diffTrain.T*diffTrain))
- eigSortIndex = argsort(-eigvals)
- for i in xrange(shape(FaceMat)[1]):
- if (eigvals[eigSortIndex[:i]]/eigvals.sum()).sum() >= selecthr:
- eigSortIndex = eigSortIndex[:i]
- break
- covVects = diffTrain * eigVects[:,eigSortIndex]
-
- return avgImg,covVects,diffTrain
-
- def judgeFace(judgeImg,FaceVector,avgImg,diffTrain):
- diff = judgeImg.T - avgImg
- weiVec = FaceVector.T* diff
- res = 0
- resVal = inf
- for i in range(15):
- TrainVec = FaceVector.T*diffTrain[:,i]
- if (array(weiVec-TrainVec)**2).sum() < resVal:
- res = i
- resVal = (array(weiVec-TrainVec)**2).sum()
- return res+1
-
- if __name__ == '__main__':
-
- avgImg,FaceVector,diffTrain = ReconginitionVector(selecthr = 0.9)
- nameList = ['01','02','03','04','05','06','07','08','09','10','11','12','13','14','15']
- characteristic = ['centerlight','glasses','happy','leftlight','noglasses','rightlight','sad','sleepy','surprised','wink']
-
- for c in characteristic:
-
- count = 0
- for i in range(len(nameList)):
-
-
- loadname = 'D:\python/face recongnition\YALE\YALE\unpadded\subject'+nameList[i]+'.'+c+'.pgm'
- judgeImg = cv2.imread(loadname,0)
- if judgeFace(mat(judgeImg).flatten(),FaceVector,avgImg,diffTrain) == int(nameList[i]):
- count += 1
- print 'accuracy of %s is %f'%(c, float(count)/len(nameList))























 15
15

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









