







并查集:朋友的朋友也是朋友
间接有联系的也算有联系
求所有直接或者间接有联系的事物的集合
并: union: 如果2个人是朋友关系,分别计算他们的带头大哥,如果他们的带头大哥不同,则将他们的带头大哥随机取一个作为最大的大哥
查: find:查找每个节点的带头大哥是谁
初始化:每个人的带头大哥都是他们自己/或者自己的下标
关键是:要得到每个人的带头大哥的字段parent,有了这个字典,然后对集合进行遍历,将同一个带头大哥下的节点进行聚合,答案几乎就出来了
注意下面的几个细节:
1)并查集的初始化:一般情况下,每个元素都是一个单独的集合,即其父节点指向自己
2)查找操作:是核心,需要实现路径压缩和按rank进行合并2个优化策略。路径压缩:将该节点的所有父节点都直接指向根节点,从而减少后续查找的时间复杂度。
3)合并操作:按rank合并,rank是用来记录每个集合的深度,即集合中元素的数量。是将较小的集合合并到较大的集合中,这样可以保证提高算法的效率,降低合并后结果不正确,保证算法的性能
4)在使用并查集时,要注意避免出现死循环、数组越界等常见错误
class UnionFind:
def __init__(self, n ):
self.parent = list(range(n))
self.size = [1] *n
self.circle_cnt = n
def find(self, a):
root = a
while root != parent[root]:
root = parent[root]
# 路径压缩,将该节点的所有父节点的带头大哥都指向根节点
while a != root:
pre_root = parent[a]
parent[a] = root
a = pre_root
return root
def union(self, a, b):
p_a = self.find(a)
p_b = self.find(b)
if p_a != p_b:
if self.size[p_a] < self.size[p_b]:
p_a, p_b = p_b, p_a
self.parent[p_b] = p_a
self.size[p_a] += self.size[p_b]
self.circle_cnt -=1
1. [ 婴儿名字]
(https://leetcode-cn.com/problems/baby-names-lcci/)
每年,政府都会公布一万个最常见的婴儿名字和它们出现的频率,也就是同名婴儿的数量。有些名字有多种拼法,例如,John 和 Jon 本质上是相同的名字,但被当成了两个名字公布出来。给定两个列表,一个是名字及对应的频率,另一个是本质相同的名字对。设计一个算法打印出每个真实名字的实际频率。注意,如果 John 和 Jon 是相同的,并且 Jon 和 Johnny 相同,则 John 与 Johnny 也相同,即它们有传递和对称性。
在结果列表中,选择字典序最小的名字作为真实名字。
示例:
输入:names = ["John(15)","Jon(12)","Chris(13)","Kris(4)","Christopher(19)"], synonyms = ["(Jon,John)","(John,Johnny)","(Chris,Kris)","(Chris,Christopher)"]
输出:["John(27)","Chris(36)"]
def nameFrequence():
def find(name):
root = name
while root != parent[root]:
root = parent[root]
# 路径压缩,将该节点的所有父节点的带头大哥都指向根节点
while name != root:
pre_root = parent[name]
parent[name] = root
name = pre_root
return root
def union(name1, name2):
p_name1 = find(name1)
p_name2 = find(name2)
if (p_name1 < p_name2):
parent[p_name2] = p_name1
elif (p_name2 < p_name1):
parent[p_name1] = p_name2
names = ["John(15)", "Jon(12)", "Chris(13)", "Kris(4)", "Christopher(19)"]
synonyms = ["(Jon,John,Johnny)", "(John,Johnny)", "(Chris,Kris)", "(Chris,Christopher)"]
name_dic = {}
parent = {}
for name in names:
(name, name_count) = name.replace("\"", "").replace(")", "").split("(")
name_dic[name] = int(name_count)
parent[name] = name
for name_pare in synonyms:
name_list = name_pare.replace("\"", "").replace(")", "").replace("(", "").split(",")
name1 = name_list[0]
name2 = name_list[1]
if name1 not in name_dic or name2 not in name_dic:
continue
union(name1, name2)
res = {}
for name, count in name_dic.items():
p_name = find(name)
if p_name not in res:
res[p_name] = count
else:
res[p_name] += count
return [p_name + "(" + str(count) + ")" for p_name, count in res.items()]
2. [. 账户合并]
(https://leetcode-cn.com/problems/accounts-merge/)
给定一个列表 accounts,每个元素 accounts[i] 是一个字符串列表,其中第一个元素 accounts[i][0] 是 名称 (name),其余元素是 emails 表示该帐户的邮箱地址。
现在,我们想合并这些帐户。如果两个帐户都有一些共同的邮件地址,则两个帐户必定属于同一个人。请注意,即使两个帐户具有相同的名称,它们也可能属于不同的人,因为人们可能具有相同的名称。一个人最初可以拥有任意数量的帐户,但其所有帐户都具有相同的名称。
合并帐户后,按以下格式返回帐户:每个帐户的第一个元素是名称,其余元素是按顺序排列的邮箱地址。accounts 本身可以以任意顺序返回。
例子 1:
Input:
accounts = [["John", "johnsmith@mail.com", "john00@mail.com"], ["John", "johnnybravo@mail.com"], ["John", "johnsmith@mail.com", "john_newyork@mail.com"], ["Mary", "mary@mail.com"]]
Output: [["John", 'john00@mail.com', 'john_newyork@mail.com', 'johnsmith@mail.com'], ["John", "johnnybravo@mail.com"], ["Mary", "mary@mail.com"]]
Explanation:
第一个和第三个 John 是同一个人,因为他们有共同的电子邮件 "johnsmith@mail.com"。
第二个 John 和 Mary 是不同的人,因为他们的电子邮件地址没有被其他帐户使用。
我们可以以任何顺序返回这些列表,例如答案[['Mary','mary@mail.com'],['John','johnnybravo@mail.com'],
['John','john00@mail.com','john_newyork@mail.com','johnsmith@mail.com']]仍然会被接受。
-
class UnionSet(object): def __init__(self): self.parent = {} def find(self,x): while x!=self.parent.get(x,x): x = self.parent.get(x,x) return x def union(self,x,y): p_x = self.find(x) p_y = self.find(y) self.parent[p_y] = p_x class Solution: def accountsMerge(self, accounts: List[List[str]]) -> List[List[str]]: us = UnionSet() email_to_name = {} for account in accounts: for i in range(1, len(account)): email_to_name[account[i]] = account[0] if i<len(account)-1: us.union(account[i], account[i+1]) res = {} for email in email_to_name: p_email = us.find(email) if p_email not in res: res[p_email] = [email] else: res[p_email].append(email) return [ [email_to_name[emails[0]]]+sorted(emails) for emails in res.values()]
3 [交换字符串中的元素]
(https://leetcode-cn.com/problems/smallest-string-with-swaps/)
给你一个字符串 s,以及该字符串中的一些「索引对」数组 pairs,其中 pairs[i] = [a, b] 表示字符串中的两个索引(编号从 0 开始)。
你可以 任意多次交换 在 pairs 中任意一对索引处的字符。
返回在经过若干次交换后,s 可以变成的按字典序最小的字符串。
示例 1:
输入:s = "dcab", pairs = [[0,3],[1,2]]
输出:"bacd"
解释:
交换 s[0] 和 s[3], s = "bcad"
交换 s[1] 和 s[2], s = "bacd"
示例 2:
输入:s = "dcab", pairs = [[0,3],[1,2],[0,2]]
输出:"abcd"
解释:
交换 s[0] 和 s[3], s = "bcad"
交换 s[0] 和 s[2], s = "acbd"
交换 s[1] 和 s[2], s = "abcd"
示例 3:
输入:s = "cba", pairs = [[0,1],[1,2]]
输出:"abc"
解释:
交换 s[0] 和 s[1], s = "bca"
交换 s[1] 和 s[2], s = "bac"
交换 s[0] 和 s[1], s = "abc"
-
class Solution: def smallestStringWithSwaps(self, s: str, pairs: List[List[int]]) -> str: s = list(s) n = len(s) parent = {i:i for i in range(n)} def find(x): if x != parent[x]: parent[x] = find(parent[x]) return parent[x] for x,y in pairs: parent[find(y)] = find(x) union_dic = collections.defaultdict(list) for i, p_i in parent.items(): p_i = find(p_i) union_dic[p_i].append(i) for union_index_list in union_dic.values(): union_value_list_sort = sorted([s[i] for i in union_index_list]) for i,c in zip(sorted(union_index_list), union_value_list_sort): s[i]=c return "".join(s)
import collections
def cal_swich_item(s, pairs):
uf = UnionFind(len(s))
for pair in pairs:
x, y = pair[0], pair[1]
uf.union(x, y)
groups = collections.defaultdict(list)
for i in range(len(s)):
groups[uf.parent[i]].append(i)
res = list(s)
for group in groups.values():
chars = sorted(res[i] for i in group)
for i , ch in zip(sorted(group), chars):
res[i] = ch
return ''.join(res)
4 朋友圈问题
朋友圈问题:
班上有 N 名学生。其中有些人是朋友,有些则不是。他们的友谊具有是传递性。如果已知 A 是 B 的朋友,B 是 C 的朋友,那么我们可以认为 A 也是 C 的朋友。所谓的朋友圈,是指所有朋友的集合。
给定一个 N * N 的矩阵 M,表示班级中学生之间的朋友关系。如果M[i][j] = 1,表示已知第 i 个和 j 个学生互为朋友关系,否则为不知道。你必须输出所有学生中的已知的朋友圈总数。
示例 1:
输入:
[[1,1,0],
[1,1,0],
[0,0,1]]
输出:2
解释:已知学生 0 和学生 1 互为朋友,他们在一个朋友圈。第2个学生自己在一个朋友圈。所以返回 2 。
class UnionFind:
def __init__(self, n ):
self.parent = list(range(n))
self.size = [1] *n
self.circle_cnt = n
def find(self, a):
while a != self.parent[a]:
a = self.parent[a]
return a
def union(self, a, b):
p_a = self.find(a)
p_b = self.find(b)
if p_a != p_b:
if self.size[p_a] < self.size[p_b]:
p_a, p_b = p_b, p_a
self.parent[p_b] = p_a
self.size[p_a] += self.size[p_b]
self.circle_cnt -=1
def cal_friend_circle(grid):
n = len(grid)
uf = UnionFind(n)
for i in range(n):
for j in range(i+1, n):
if grid[i][j] ==1:
uf.union(i, j)
print(uf.parent)
print(uf.size)
return uf.circle_cnt
5、计算被环绕的区域
题目
给你一个 m x n 的矩阵 board ,由若干字符 ‘X’ 和 ‘O’ ,找到所有被 ‘X’ 围绕的区域,并将这些区域里所有的 ‘O’ 用 ‘X’ 填充。
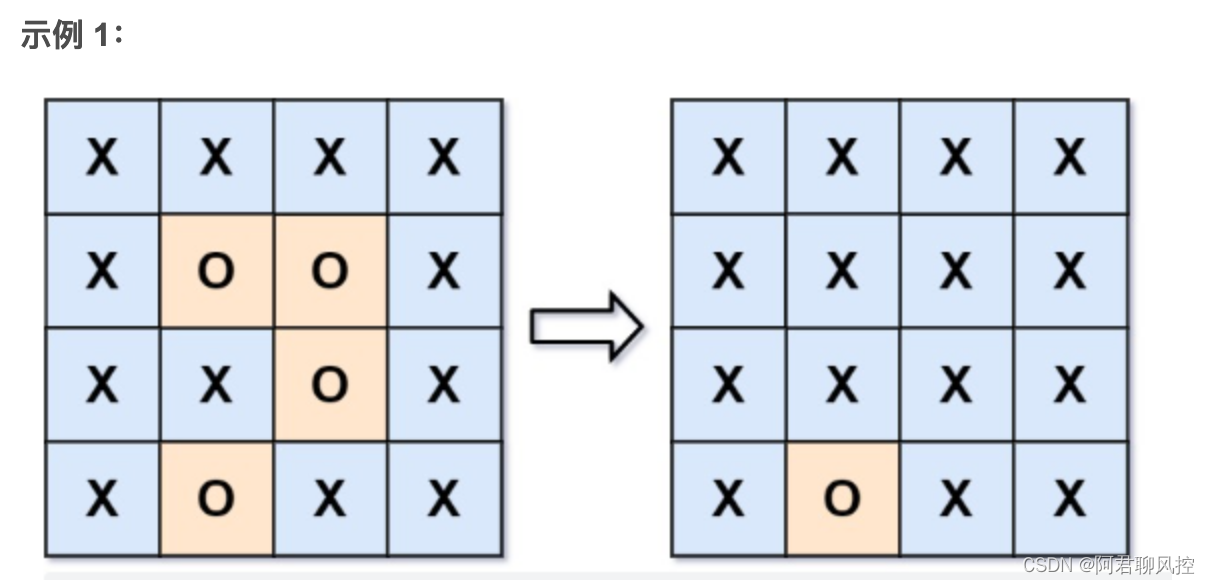
输入:board = [["X","X","X","X"],["X","O","O","X"],["X","X","O","X"],["X","O","X","X"]]
输出:[["X","X","X","X"],["X","X","X","X"],["X","X","X","X"],["X","O","X","X"]]
解释:被围绕的区间不会存在于边界上,换句话说,任何边界上的 'O' 都不会被填充为 'X'。 任何不在边界上,或不与边界上的 'O' 相连的 'O' 最终都会被填充为 'X'。如果两个元素在水平或垂直方向相邻,则称它们是“相连”的。
思路:
计算:所有o的并查集,分别判断集合内元素是否在边界上,如果在边界上,不处理;否则;将集合內元素替换为X
class UnionFind:
def __init__(self, n ):
self.parent = list(range(n))
self.size = [1] *n
self.circle_cnt = n
def find(self, a):
while a != self.parent[a]:
a = self.parent[a]
return a
def union(self, a, b):
p_a = self.find(a)
p_b = self.find(b)
if p_a != p_b:
if self.size[p_a] < self.size[p_b]:
p_a, p_b = p_b, p_a
self.parent[p_b] = p_a
self.size[p_a] += self.size[p_b]
self.circle_cnt -=1
def cal_round_area_cnt(board):
n = len(board)
m = len(board[0])
def idx(x, y):
return x*m+y
uf = UnionFind(n*m+1)
dummy = n*m
for i in range(n):
for j in range(m):
if board[i][j] == "O":
if i==0 or i== n-1 or j ==0 or j==m-1:
uf.union(idx(i, j), dummy )
else:
for x, y in [(i+1, j), (i-1, j), (i,j+1), (i, j-1)]:
if board[x][y] == "O":
uf.union(idx(i, j), idx(x, y))
for i in range(1,n-1):
for j in range(1,m-1):
if board[i][j] == "O":
if uf.find(idx(i,j)) != uf.find(dummy):
board[i][j] = "X"
print(uf.size)
print(uf.parent)
return board
6、计算岛屿的数量
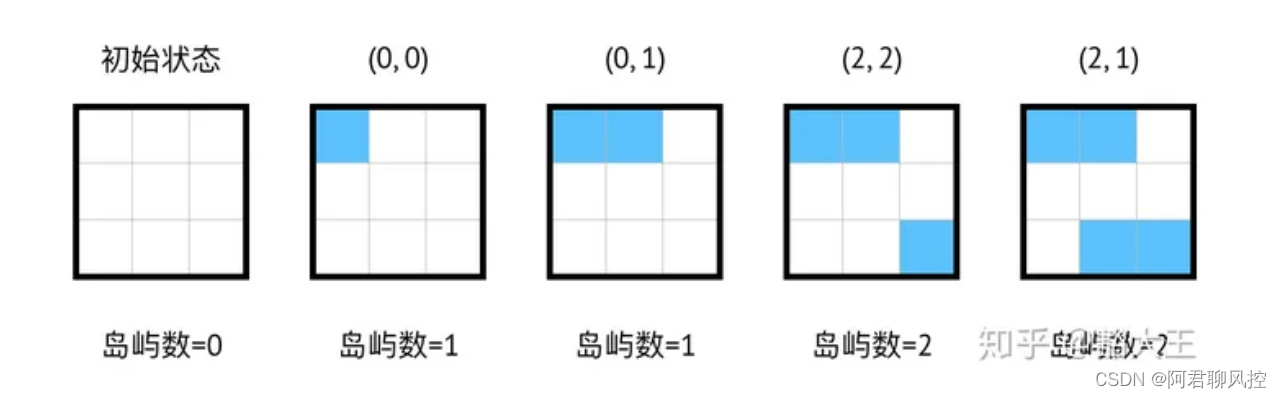
题目给出的样例为:水域大小为2*2,一共有4次造陆,位置分别为(0,0),(0,1),(2,2),(2,1)。那么每次造陆后的岛屿数如图所示:
def cal_island_cnt(n, operators):
uf = UnionFind(n*n)
grid = [[0 for j in range(n)] for i in range(n)]
def idx(i, j):
return i*n+j
res = []
island_cnt = 0
for operator in operators:
i, j = operator[0], operator[1]
if grid[i][j] ==0:
continue
grid[i][j] =1
island_cnt +=1
for x, y in [(i+1, j), (i-1,j), (i, j-1), (i, j+1)]:
if 0<=x <=n-1 and 0<=y<=n-1:
# 如果相邻的岛屿跟当前岛屿不相连
if uf.find(idx(i, j)) != uf.find(idx(x, y)) and grid[x][y]==1:
# 将岛屿个数-1
island_cnt-=1
# 将2个岛屿相连
uf.union(idx(i, j), idx(x, y))
res.append(island_cnt)
return res
7、# 计算连续数字的最大长度
nums = [100,4,200,1,3,2]
输出:4
def cal_max_cnt(nums):
uf = UnionFind(len(nums))
for num in nums:
if num+1 in nums:
uf.union(num, num+1)
if num-1 in nums:
uf.union(num, num-1)
return max(uf.size)















 2231
2231











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









