









定义
Geohash是将一个地理位置编译为一个数字与字母组成的短字符串
算法逻辑
例如:天安门附近经纬度:116.403694,39.911836。我们按照geohash将其转为长度5的geohash
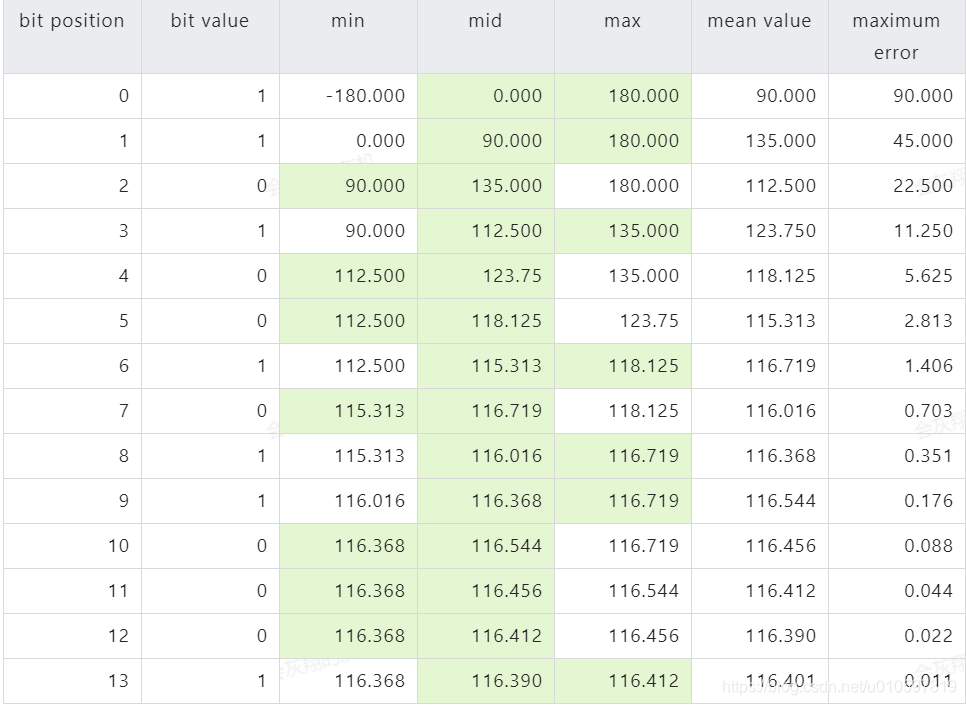
1. 经纬度按照二分法二分,经纬度如果属于二分后的左区间则取0,右区间则取1
- 绿色背景表示纬度落在区间
- bit value 代表转为二进制的取值
- mean value 代表二分后选中区间(绿色背景区间)的平均值=(左区间+右区间)/2
- maximum error 表示最大误差值。例如:第一次二分我们取值45,不论真实的纬度是多少,误差不会超过45
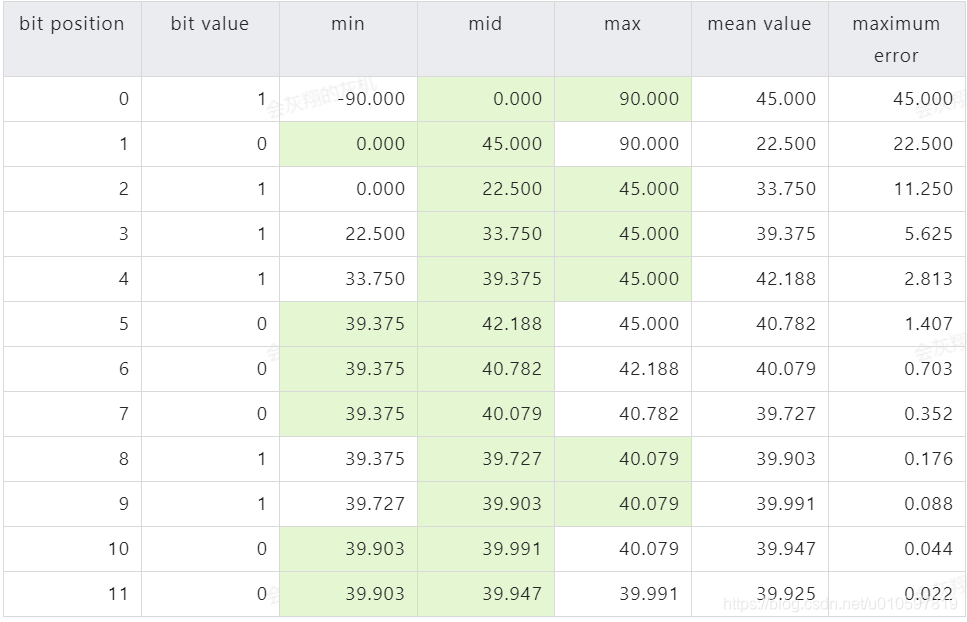
(为清楚起见,上表中的数字已四舍五入至小数点后三位)
2. 组合经纬度的二进制编码,从左第一个下标为0,偶数下标取经度二进制编码,奇数下标取纬度二进制编码
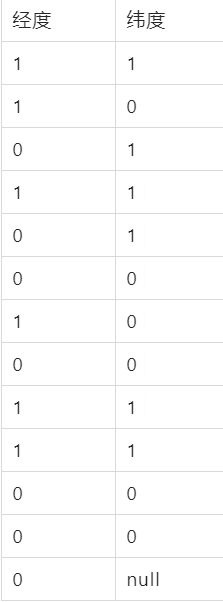
组合后二进制编码:11100 11101 00100 01111 00000
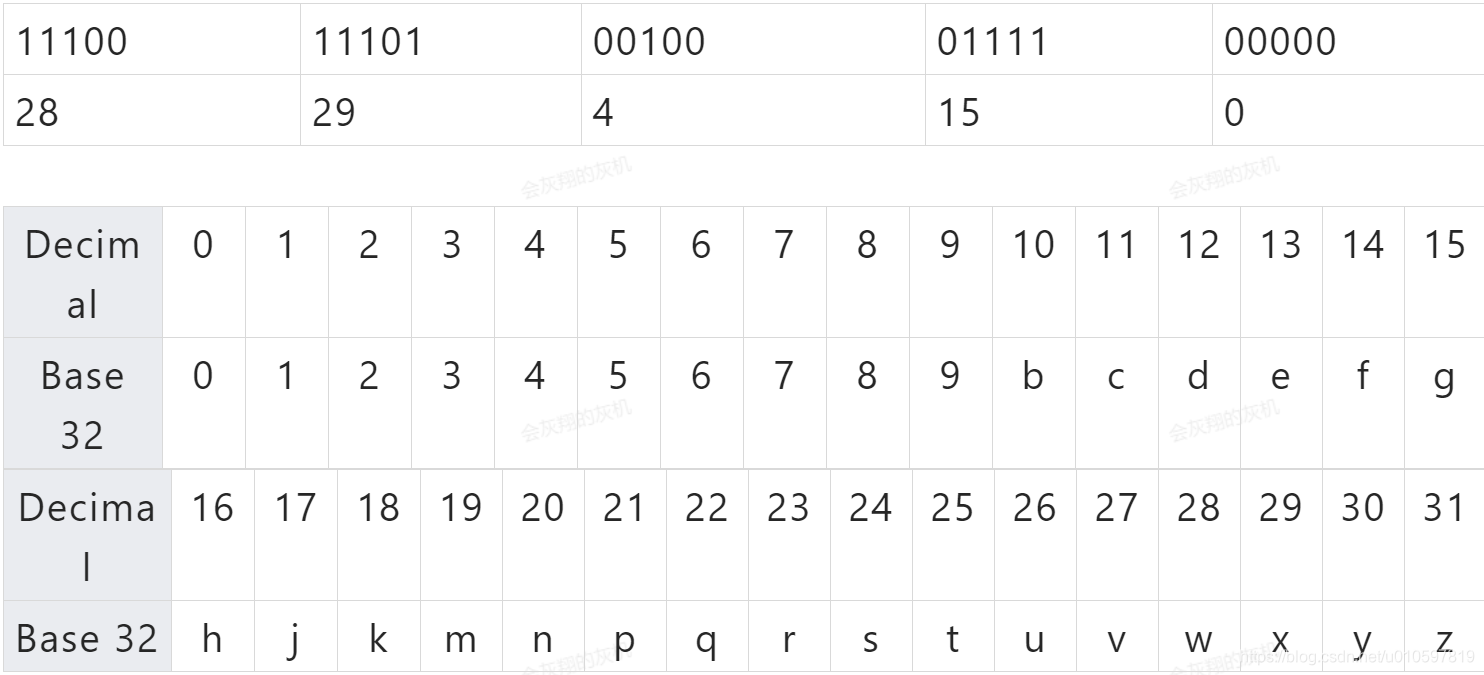
3. 按照base32编码
- 组合后二进制5位一切分转为十进制
- 按照base32编码表编码:w x 4 g 0
4. 校验
使用开源网站校验geohash结果是正确的:http://www.geohash.cn/
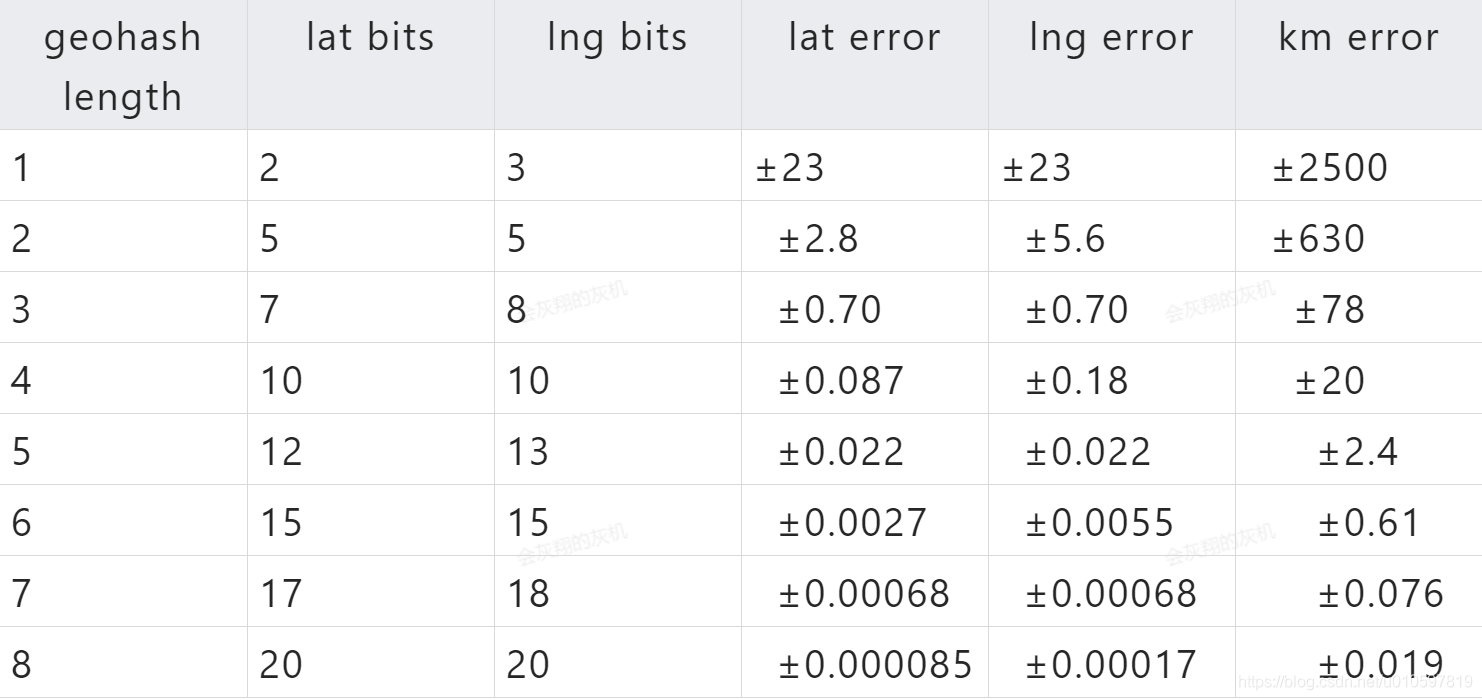
Geohash字符数和km的精度(误差)
用于确定距离时的限制
边缘情况
Geohashes通常用于查找邻近点基于每个点拥有公共的前缀。然而,边缘情况的点彼此相近,但是在180度子午线对立面的情况将导致Geohash编码没有公共的前缀(附近物理位置的经度不同)。接近南极点与北极点的点也同样有非常不同geohash(附近物理位置的经度不同)。
两个邻近位置在赤道(或子午线)两边将不会有一个长的公共前缀,因为他们属于世界的不同的半球。简单地说,一个位置的二进制纬度(或经度)将会是011111… 并且另一个是100000…,那么他们将不会有一个公共前缀并且几乎所有位是相反的。这也可以被看作依赖Z阶曲线(在本例中更恰当的称呼为N阶访问)排序点的结果,因为两个邻近的点可能在不同的时间被访问。但是,两个具有很长公共前缀的点将会很相近。
为了进行邻近搜索,可以计算边界框的西南角(低geohash与低经纬度)与东北角(高geohash与高经纬度),并搜索他们两个之间的geohash。该搜索将会检索z阶曲线两个角之间的所有点,这可能是很多点。这个方法在180度子午线与极点也会失效。Solr通过计算邻近geohash最近的正方形的前缀来使用一个前缀过滤器列表。
Z阶曲线
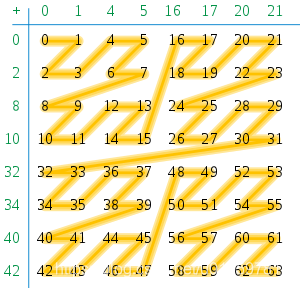
非线性
由于geohash(在本实现中)基于经纬度坐标,两个geohash之间的距离反映了两点之间的经纬度距离,这并不转换为实际距离,参见 Haversine formula公式.
经纬度系统非线性例子:
- 在赤道(0 度)处,1经度的长度是111.320 km,而1纬度为110.574 km,误差为0.67%
- 在30度处(中纬度)误差是110.852/96.486 = 14.89%
- 在60度(高北极)误差是111.412/55.800 = 99.67%,在两极点处达到无限大。
注意这些限制不是由geohash造成的,也不是由经纬度坐标造成的,而是由于难以将球体上的坐标(非线性且具有类似于模算术的值包装)映射到二维坐标,并且难以均匀的探索二维空间。第一个与地理坐标系统(Geographical coordinate system)和地图投影(Map projection)有关,而另一个与Hilbert曲线(Hilbert curve)与z阶曲线(z-order curve)有关。一旦找到一个坐标系统在距离上线性的表示点,并在边缘处包裹住它们,并且可以统一探索,将geohash应用至那些坐标将不会受上述限制。
虽然可以用笛卡尔坐标系(Cartesian coordinate system)将geohash应用到一个区域, 但是它仅应用到笛卡尔坐标系应用的区域。
尽管存在这些问题,还是有可行的应变方法,并且该算法已在Elasticsearch,[7] MongoDB,[8] HBase,Redis,[9]和Accumulo [10]中成功使用,以实现邻近搜索。

















 2220
2220

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









