







该文主要写统计学习过程中遇到的距和差。
例:大学篮球队有学员毕业,现需招一个新人进入球队。在经过多场比赛后,球队教练得到了如下数据:
| 王二 | 每场比赛得分 | 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 频数 | 1 | 1 | 2 | 2 | 2 | 1 | 1 | |
| 张三 | 每场比赛得分 | 7 | 9 | 10 | 11 | 13 | ||
| 频数 | 1 | 2 | 4 | 2 | 1 | |||
| 李四 | 每场比赛得分 | 3 | 6 | 7 | 10 | 11 | 13 | 30 |
| 频数 | 2 | 1 | 2 | 3 | 1 | 1 | 1 |
根据当前的数据,教练发现这三个人得分的算术平均数、中位数、众数都一致,均为10。名额只有一个,该选哪位同学入校队?
全距
全距又叫极差,是用于度量数据集分散程度的一种方法。其算法为最大值(又称上界)与最小值(又称下界)的差。
由此可以得出新球员的全距分别是6,6,27。新的问题来了球员王二和张三具有相同的全距值。虽然全距值能看出数据集的宽度,但是看不出数据的分布形态,特别容易收异常值的影响。
例如数据集(1,1,1,2,2,2,2,3,3,3,3,3,4,4,4,4,5,5,5,10)。如果没有数据10则该数据集的全距为4,加上10之后,全距变为9,两者差异较大。
四分位距
四分位数也称四分位点,是指在统计学中把所有数值由小到大排列并分成四等份,处于三个分割点位置的数值。四分位数是通过3个点将全部数据等分为4部分,其中每部分包含25%的数据。很显然,中间的四分位数就是中位数,因此通常所说的四分位数是指处在25%位置上的数值(称为下四分位数)和处在75%位置上的数值(称为上四分位数)。
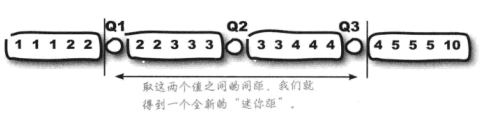
第一四分位数 (Q1),又称“较小四分位数”,等于该样本中所有数值由小到大排列后第25%的数字。
第二四分位数 (Q2),又称“中位数”,等于该样本中所有数值由小到大排列后第50%的数字。
第三四分位数 (Q3),又称“较大四分位数”,等于该样本中所有数值由小到大排列后第75%的数字。
第三四分位数与第一四分位数的差距又称四分位距(InterQuartile Range,IQR)
四分位数计算公式如下:
首先确定四分位数的位置:
Q1的位置= (n+1) × 0.25
Q2的位置= (n+1) × 0.5
Q3的位置= (n+1) × 0.75
n表示项数
对于四分位数的确定,有不同的方法,另外一种方法基于N-1 基础。即
Q1的位置=1+(n-1)x 0.25
Q2的位置=1+(n-1)x 0.5
Q3的位置=1+(n-1)x 0.75
Excel 中有两个四分位数的函数。QUARTILE.EXC 和QUARTILE.INC
QUARTILE.EXC 基于 N+1 的方法,QUARTILE.INC基于N-1的方法。
注:将n个数从小到大排列:
Q2为n个数组成的数列的中数(Median);
当n为奇数时,中数Q2将该数列分为数量相等的两组数,每组有 (n-1)/2 个数,Q1为第一组 (n-1)/2 个数的中数,Q3为为第二组(n-1)/2个数的中数;
当n为偶数时,中数Q2将该数列分为数量相等的两组数,每组有n/2数,Q1为第一组 n/2个数的中数,Q3为为第二组 n/2 个数的中数。
除了四分位距之外还有十分位距、百分位距等
方差
方差是度量数据分散性的一种方法,是数值与均值的距的平方数据的平均值,是衡量源数据和期望值相差的度量值,具体公式如下:
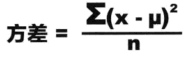
注:当数据分布比较分散(即数据在平均数附近波动较大)时,各个数据与平均数的差的平方和较大,方差就较大;当数据分布比较集中时,各个数据与平均数的差的平方和较小。因此方差越大,数据的波动越大;方差越小,数据的波动就越小。
标准差
标准差是反映一组数据离散程度最常用的一种量化形式,是表示精确度的重要指标。是离均差平方的算术平均数(即:方差)的算术平方根。计算公式如下:
总体标准差:
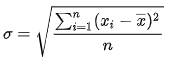
样本标准差:
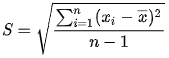
标准误差:
![]()
与方差:方差=标准差的平方。
在实验中单次测量总是难免会产生误差,为此我们经常测量多次,然后用测量值的平均值表示测量的量,并用误差条来表征数据的分布,其中误差条的高度为±标准误差。这里即标准差。
变异系数:
![]()
其中,![]() (读:X bar)指数据的平均数。
(读:X bar)指数据的平均数。
注:文中部分引用了百度百科,感觉对文中认识不足或者不理解的地方也可以参看百度百科
能有限,短文将不断进行完善更新,欢迎对不足和错误之处进行批评指正。















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









