







1、Hadoop 1.x 的局限性
(1) 扩展性
集群最大节点数-4000;最大并发任务数40000;
(2) 可用性
JobTracker负载较重,存在单点故障
(3)批处理模式,时效性低
仅支持MapReduce一种计算方式
(4) 低效的资源管理
资源强制划分为map task slot和reduce task slot,且两种slot不可以相互转换。
2、Hadoop 2.x 架构及工作原理
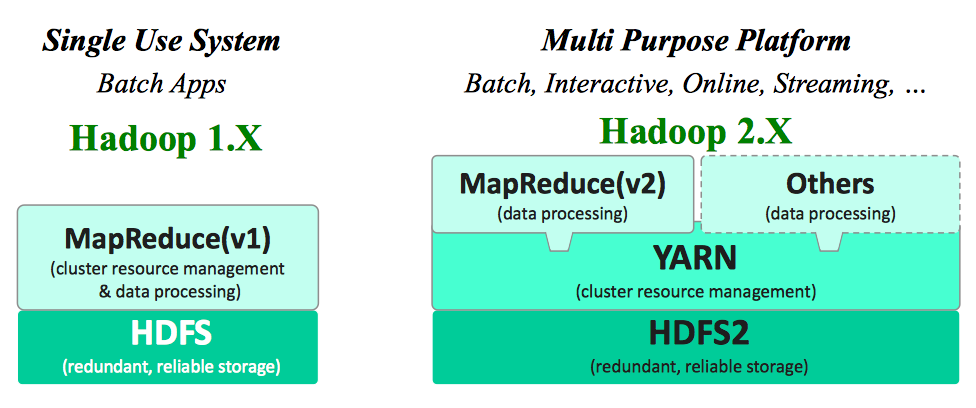
图 1 Hadoop 1.x VS Hadoop 2.x
(1)Yarn的架构及组件
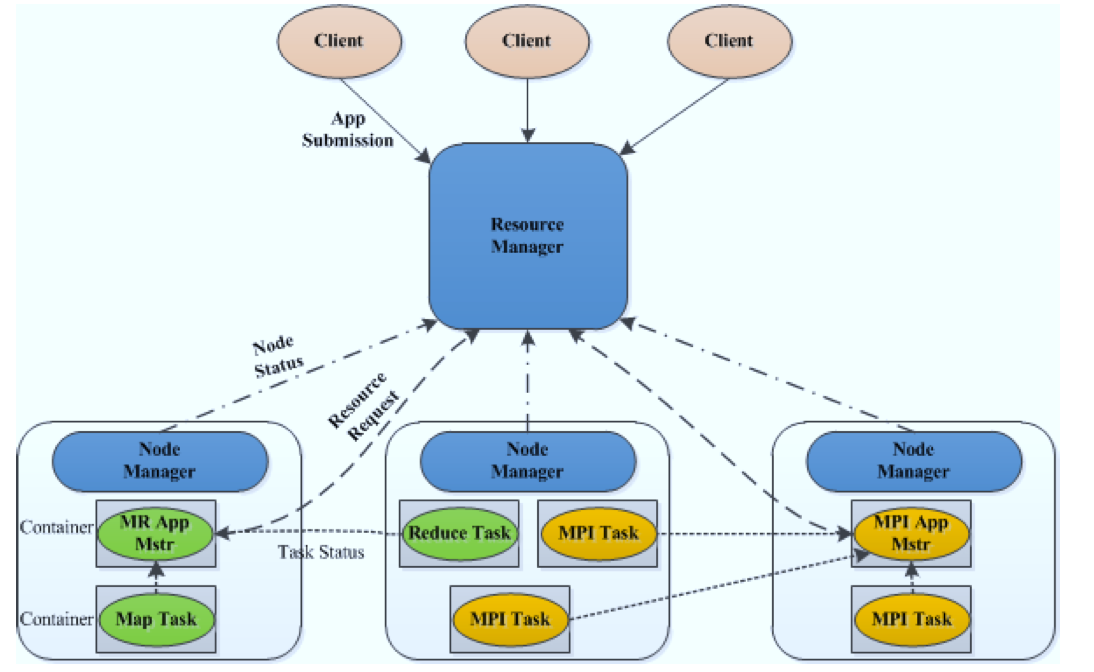
图2 Yarn架构图
ResourceManager(RM):处理客户端请求;启动/监控ApplicationMaster;监控NodeManager;资源分配与调度;
NodeManager(NM):单个节点上的资源管理;处理来自RM的命令;处理来自AM的命令。
ApplicationMaster(AM): 数据切分;为应用程序申请资源,并分配给内部任务;任务监控与容错。
Container是绑定到特定集群节点的一组资源的逻辑组合(如内存,核)。
(2)Yarn 资源调度
Hadoop 1.x采用了静态资源分配的方式,Map slot 与 Reduce slot不能共享。Yarn 使用container的方式来请求资源,支持CPU和内存两种资源调度方式。支持划分虚拟CPU。
(3)Yarn 优点
- 一个集群部署多个版本
- 计算资源按需伸缩
- 不同负载应用混搭,集群利用率高
- 共享底层存储,避免数据跨集群迁移
(4)NameNode Heartbeat (HA)
a. Hadoop 1.x HA
Secondary NameNode: 阶段性合并edits和fsimage以缩短集群启动时间,不是HA,无法立刻接管失效的NN及保证数据完整性。
Backup NameNode:在内存中复制了NN的当前状态,是warm standby,无法保证数据完整性。也可通过手动把name.dir指向NFS,是 cold standy,可以保证数据完整性,但是集群恢复需要手动完成。
b. Hadoop 2.x HA
- 利用共享存储在两个NN间同步edits信息
- DataNode同时向两个NN汇报块信息,让Standby NN保持集群最新状态
- 用FailoverController watchdog进程监视和控制NN进程,防止因NN fullGC挂起无法发送HA
- 防止brain-split,即因主备切换不彻底导致slave误以为出现两个active master,通常采用fencing机制。
(5)NameNode Federation
a. Hadoop 1.x 缺陷
容量限制:1G内存可以保存1百万个块,一亿个文件需要上百G内存保存元数据信息,受制于Java内存管理能力限制,上百G内存基本达到上限。
性能限制:所有的元数据信息的读取操作都需要与NN进行通信,集群规模变大后,NN会成为性能瓶颈。
b. Hadoop 2.x Federation
Hadoop 2.x 利用Federation机制可以管理多个NN。Federation由多个NameService组成,每个NameService又由一个或两个NN组成。每个NN会定义一个存储池,单独对外提供服务,多个NN通用集群中的DN上的存储资源。使用客户端挂载表把不同的目录映射到不同的NameNode上,通过目录自动对应NameNode,使Federation配置改动对应用透明。















 478
478

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









