







前言
某天朋友说,能不能帮忙扒下ins的博主帖子,要所有帖子的点赞和评论,我本来准备让会python的同事写的,最后还是自己顺手写了,本来一开始准备用nodejs或者js写的,想着前端本地测试代理和导excel比较麻烦还是用Java吧,正好好久没写Java了,就当回忆一波吧。
注意点
ss梯子大家自己准备好,不然连不上ins的,还有ins的一些反扒规则等等我就不一一列举了,
下面说下大概的几个点:
-
instagram的首页数据是
服务端渲染的,所以首页出现的11或12条数据是以html中的一个json结构存在的(additionalData),之后的帖子加载才是走ajax请求的。 -
在2019/06之前,ins是有反爬机制的,请求时需要在请求头加了’X-Instagram-GIS’字段。其算法是:吧啦吧啦吧啦,,,,但是在在2019/06之后, instagram已经取消了X-Instagram-GIS的校验,所以无需再生成X-Instagram-GIS,上一点内容可以当做历史来了解了
-
关于query_hash,一般这个哈希值不用怎么管,可以直接写死
-
特别注意:在每次请求时务必带上自定义的header,且header里面要有user-agent,这样子才能使用rhx_gis来进行签名访问并且获取到数据。切记!是每次访问!
例如:
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36'
}
- api的分页(请求下一页数据),如用户帖子列表,大概就是下页的参数再上一页的page里面,
ins中一个带分页的ajax请求,一般请求参数会类似下面:
query_hash: a5164aed103f24b03e7b7747a2d94e3c
variables: {
"id":"1664922478",
"first":12,
"after":"AQBJ8AGqCb5c9rO-dl2Z8ojZW12jrFbYZHxJKC1hP-nJKLtedNJ6VHzKAZtAd0oeUfgJqw8DmusHbQTa5DcoqQ5E3urx0BH9NkqZFePTP1Ie7A"}
– id表示用户id,可在html中的sharedData中获取
– first表示初始时获取多少条记录,好像最多是50
– after表示分页游标,记录了分页获取的位置
大概思路
1,前12条数据只能能html里面解析。
2,后面的分页数据都可以走http请求。
3,关于分页,第一次的分页参数也在html里面,后面的分页参数都在上一个请求结果里面。
4,所以思路就是先获取ins的html从里面截取前12条数据和第一次的分页参数,后面再循环分页请求就行。
5,最后汇总导出excel,完事。
代码截图
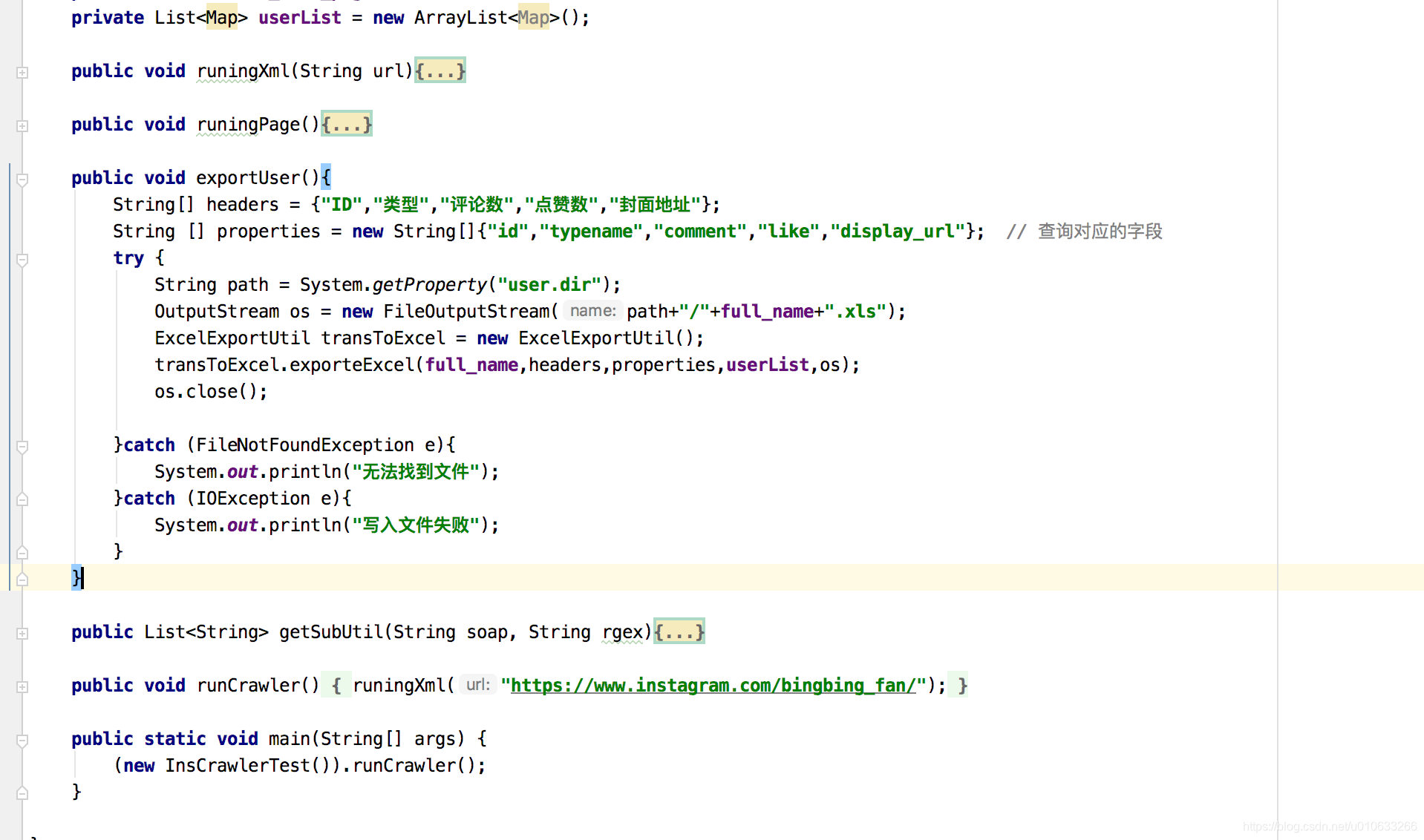
效果
这里我选了范冰冰的ins导出,毕竟上面都是老外,其他人咋也不认识。。。。
- 范冰冰ins首页:
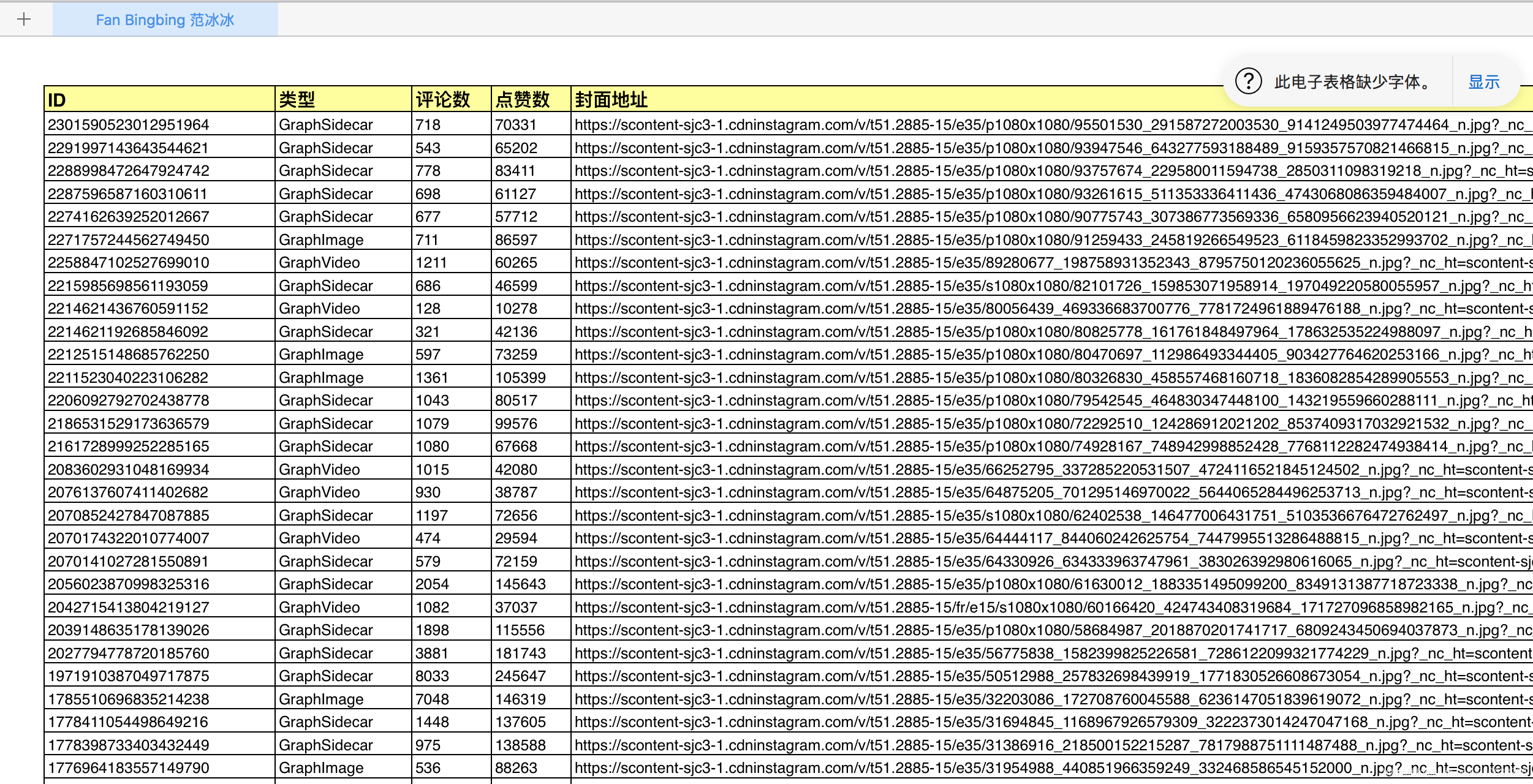
- 导出excel:
GitHub
最后附上GitHub地址,对大家有帮助就start吧。。。欢迎star和PR~ 感谢泥萌!!

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









