






数据集构建
pdf文本提取
将计算机网络第五版pdf中的文字提取到result.json
from rapidocr_pdf import PDFExtracter
import json
pdf_extracter = PDFExtracter(print_verbose=True, use_cuda=True)
pdf_path = "computer_networks_5.pdf"
texts = pdf_extracter(pdf_path, force_ocr=False)
print(texts)
with open('./result.json', 'w', encoding='utf-8') as f:
json.dump(texts, f)注意如果提取的是中文数据,在保存到json时需要设置ensure_ascii为False
import json
src_f = open('./result.json')
out_f = open('./processed_result.json', 'w', encoding='utf-8')
result = json.load(src_f)
# print(json.dumps(result))
json.dump(result, out_f, ensure_ascii=False)原始的pdf格式
提取后的json数据

rapidocr_pdf会将提取的每页数据放到一个list中,其中每个元素都是一个list,形如["页码", "文本", "置信度"]
数据清洗
初步提取的文档数据中存在大量的换行符、空格、特殊字符、公式、页码、等影响数据集构建和模型训练的噪声数据,因此需要额外步骤进行数据清洗。
我采用的数据清洗手段有:去除特殊字符、分割段落和句子并去除长句、去除连续的数字字符、对特殊文本进行正则匹配、使用大模型进行数据过滤。
去除页码
观察发现rapidocr_pdf会将页码进行识别提取,因此需要根据json的页码将对应页面中的页码数据去除。
import json
def remove_numbers_from_text(data_list):
result = []
for item in data_list:
number = str(item[0])
text = item[1]
processed_text = text.replace(number, '')
result.append(processed_text)
return result
# 从json文件中读取数据
with open('data.json', 'r') as file:
data = json.load(file)
# 处理数据
processed_data = remove_numbers_from_text(data)
# 将处理后的文本拼接在一起
combined_text = ' '.join(processed_data)
# 输出到文件
with open('output.txt', 'w') as file:
file.write(combined_text)
去除特殊字符
首先读入json文件,将文本中的\n,\t,连续的空格等字符去除,
import re
def remove_special_chars(text):
text = re.sub(r'\n', '', text)
text = re.sub(r'\t', '', text)
text = re.sub(r'\s+', ' ', text)
return text
特殊文本正则匹配
将“(比如......)”、“图 2-35”这样的无意义文本去除
import re
def remove_data(string):
# 匹配形如"(比如...)"的数据
pattern1 = r'\(.*?\)'
# 匹配形如"图 2-35"的数据
pattern2 = r'图 \d+-\d+'
# 去除"(比如...)"的数据
string = re.sub(pattern1, '', string)
# 去除"图 2-35"的数据
string = re.sub(pattern2, '', string)
return string
# 测试示例
string = '这是一个示例(比如...), 这是另一个示例(比如...), 这是图 2-35的示例'
result = remove_data(string)
print(result)
使用大模型+任务提示的方式进行数据清洗
代码展示
from transformers import AutoTokenizer, AutoModel, AutoModelForCausalLM
from modelscope import AutoTokenizer, AutoModelForCausalLM
import time
import json
from tqdm import tqdm
import re
def split_chinese_text(text):
"""
将中文文本按句子划分成列表
:param text: 中文文本
:return: 划分后的句子列表
"""
# 去除原句中的换行符
text = text.replace('\n', '')
# 使用正则表达式划分句子,以句号、问号和感叹号作为句子分隔符
sentences = re.split(r'([。?!])', text)
# 去除空白句子
sentences = [sentence.strip() for sentence in sentences if sentence.strip()]
# 将分隔符与前一句合并
merged_sentences = []
for i in range(0, len(sentences), 2):
if i + 1 < len(sentences):
merged_sentences.append(sentences[i] + sentences[i+1])
else:
merged_sentences.append(sentences[i])
return merged_sentences
# 1.保留内容为描述、陈述事实、定义、解释的句子。
# 2、去除大段公式、无意义符号、其他语义信息不明的文本。
# 3、保留句子格式和标点。
# 4、除处理后的文本不要输出任何其他内容。
# 输入:比特填充还确保了转换的最小密度,这将有助于物理层保持同步。正是由于这个原因,USB(通用串行总线)采用了比特填充技术。当接收方看到5 个连续入境比特l ,并且后面紧跟一个比特0,它就自动剔除(即删除)比特0。比特填充和字节填充一样,对两台计算机上的网络层是完全透明的。如果用户数据中包含了标志模式。1111110,这个标志传输出去的是011111010,但在接收方内存中存储还是01111110 。图3-5 给出了一个比特填充的例子。0 I ro I I I I I I I I I I I I I I I I 0 0 I 0 (a) 飞---....... L ... ./’ 填充比特(b) 0110 I JI JI I I I JI I I JI I I 00 I 0 (c) 图3-5比特填充(a )原始数据g(b )出现在线路上的数据:(c )存储在接收方内存中的数据。有了比特填充技术,两帧之间的边界可以由标志模式明确区分。
# 输出:比特填充还确保了转换的最小密度,这将有助于物理层保持同步。正是由于这个原因,USB(通用串行总线)采用了比特填充技术。当接收方看到5 个连续入境比特l ,并且后面紧跟一个比特0,它就自动剔除(即删除)比特0。比特填充和字节填充一样,对两台计算机上的网络层是完全透明的。如果用户数据中包含了标志模式。1111110,这个标志传输出去的是011111010,但在接收方内存中存储还是01111110 。有了比特填充技术,两帧之间的边界可以由标志模式明确区分。
# 你的任务是将给定的文本做以下处理并输出处理后的句子:保留内容为描述、陈述事实、定义、解释的句子。去除大段公式、无意义符号、其他语义信息不明的文本。保留句子格式和标点。除了原始文本不要输出任何其他内容。
def process_batch_sentence(model, tokenizer, batch_sentence, history):
simple_prompt = f"""
将不严谨的语言和乱码去除:
"""
task__example_prompt = f"""
你的任务是将输入文本中语义不明的文字和符号去除并输出,不要输出除原文外的任何其他内容:
以下是两个例子:
样例输入:比特填充还确保了转换的最小密度,这将有助于物理层保持同步。
样例输出:比特填充还确保了转换的最小密度,这将有助于物理层保持同步。
样例输入:图3-5 给出了一个比特填充的例子。0 I ro II I I I 0 (a) 飞---....... L ... ./’ 填充比特(b) 0110 I JI I 00 I 0 有了比特填充技术,两帧之间的边界可以由标志模式明确区分。
样例输出:有了比特填充技术,两帧之间的边界可以由标志模式明确区分。
你的输入:
"""
dialog_prompt = f"""
<|system|>
你的任务是将给定的文本做以下处理并输出处理后的句子:保留内容为描述、陈述事实、定义、解释的句子。去除大段公式、无意义符号、其他语义信息不明的文本。保留句子格式和标点。除处理后的文本不要输出任何其他内容。
<|user|>
比特填充还确保了转换的最小密度,这将有助于物理层保持同步。正是由于这个原因,USB(通用串行总线)采用了比特填充技术。当接收方看到5 个连续入境比特l ,并且后面紧跟一个比特0,它就自动剔除(即删除)比特0。比特填充和字节填充一样,对两台计算机上的网络层是完全透明的。如果用户数据中包含了标志模式。
<|assistant|>
比特填充还确保了转换的最小密度,这将有助于物理层保持同步。正是由于这个原因,USB(通用串行总线)采用了比特填充技术。当接收方看到5 个连续入境比特l ,并且后面紧跟一个比特0,它就自动剔除(即删除)比特0。比特填充和字节填充一样,对两台计算机上的网络层是完全透明的。如果用户数据中包含了标志模式。
<|user|>
1111110,这个标志传输出去的是011111010,但在接收方内存中存储还是01111110 。图3-5 给出了一个比特填充的例子。0 I ro I I I I I I I I I I I I I I I I 0 0 I 0 (a) 飞---....... L ... ./’ 填充比特(b) 0110 I JI JI I I I JI I I JI I I 00 I 0 (c) 图3-5比特填充(a )原始数据g(b )出现在线路上的数据:(c )存储在接收方内存中的数据。有了比特填充技术,两帧之间的边界可以由标志模式明确区分。
<|assistant|>
1111110,这个标志传输出去的是011111010,但在接收方内存中存储还是01111110 。有了比特填充技术,两帧之间的边界可以由标志模式明确区分。
<|user|>
"""
system_prompt = f"""
将接下来输入文本中的乱码删除,其余内容不变直接输出,不要输出任何多余信息
"""
prompt_history = [
('另外还有一种可能,将NAT 盒子集成到路由器或者ADSL 调制解调器中。转换之后的数据包IP=l 98.60.42.12 端口号=3344客户路由,、器和LAN//、NAT盒子/防火墙『------·,,,,、\客户办公室边界图5-55NAT 盒子的放置和操作过程(逼向Internet)ISP路由器。至此,我们掩盖了一个微小但至关重要的细节z 当应答数据包返回时(比如从Web 服务器返回的应答包〉,本质上它的目标地址是198.60.42.12 ,那么,NAT 盒子如何知道该用哪一个地址来替代呢', '另外还有一种可能,将NAT 盒子集成到路由器或者ADSL 调制解调器中。至此,我们掩盖了一个微小但至关重要的细节z 当应答数据包返回时(比如从Web 服务器返回的应答包〉,本质上它的目标地址是198.60.42.12 ,那么,NAT 盒子如何知道该用哪一个地址来替代呢'),
('1111110,这个标志传输出去的是011111010,但在接收方内存中存储还是01111110 。图3-5 给出了一个比特填充的例子。0 I ro I I I I I I I I I I I I I I I I 0 0 I 0 (a) 飞---....... L ... ./’ 填充比特(b) 0110 I JI JI I I I JI I I JI I I 00 I 0 (c) 图3-5比特填充(a )原始数据g(b )出现在线路上的数据:(c )存储在接收方内存中的数据。有了比特填充技术,两帧之间的边界可以由标志模式明确区分。', '1111110,这个标志传输出去的是011111010,但在接收方内存中存储还是01111110 。有了比特填充技术,两帧之间的边界可以由标志模式明确区分。')
]
print("input:", simple_prompt + batch_sentence)
response, history = model.chat(tokenizer, simple_prompt + batch_sentence, history=[])
print("output:\n", response)
return response, history
if __name__ == "__main__":
#chat-glm3-6b
# tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm3-6b", trust_remote_code=True)
# model = AutoModel.from_pretrained("THUDM/chatglm3-6b", trust_remote_code=True, device='cuda')
# model = model.eval()
#Qwen-72B-Chat-Int4
tokenizer = AutoTokenizer.from_pretrained("qwen/Qwen-72B-Chat-Int4", revision='master', trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(
"qwen/Qwen-72B-Chat-Int4", revision='master',
device_map="auto",
trust_remote_code=True
).eval()
# src_f = open('./data/sample.json', 'r')
src_f = open('./data/computer_network_5_origin.json', 'r')
out_f = open('./data/computer_network_5_filted.json', 'w')
# read pages content from file
pages = json.load(src_f)
full_content = ''
for page in tqdm(pages):
full_content += page[1]
# split sentences and filted
sentences = split_chinese_text(full_content)
batch_sentence = ''
history = []
filted_sentence = []
max_len = 512
for sentence in tqdm(sentences):
if len(sentence) > max_len:
continue
if len(batch_sentence) + len(sentence) > max_len:
response, history = process_batch_sentence(model, tokenizer, batch_sentence, history)
filted_sentence.extend(split_chinese_text(response))
batch_sentence = sentence
else:
batch_sentence += sentence
if batch_sentence != '':
response, history = process_batch_sentence(model, tokenizer, batch_sentence, history)
filted_sentence.extend(split_chinese_text(response))
out_f.write(json.dumps(filted_sentence, ensure_ascii=False))
效果分析
在使用ChatGLM3的时候出现了文档清洗不完全、有多余输出信息、修改了原文内容等问题,
因此我们换用了Qwen72B模型进行清洗,部署Qwen72B模型需要过多的显存,我们为了在本地部署,选用了INT4参数的版本大概需要50GB显存,在三张3090显卡上运行。
最终的清洗效果如下:


词条数据爬取和格式转换
我们对之前分析的百度百科词条编写了爬虫进行数据爬取,获得了大量的词条和描述文档,并且同时获得了一些词条间的关系。
爬虫编写
网站分析
https://baike.baidu.com/item/%E8%AE%A1%E7%AE%97%E6%9C%BA%E7%BD%91%E7%BB%9C/18763
百度百科是类似于wiki pedia的百科网站,数据库里存储了大量的概念词条和相关描述,同时在每个概念的描述文档中还使用超链接连接到相关的概念。
该网站不需要登录即可游客访问,使用浏览器可以在未登录的情况下快速多次访问不受限制。
使用技术和工具
本次爬虫使用Python作为编程语言,使用了requests模块发送http请求,使用time进行随机等待请求时间间隔防止被反爬机制识别,使用re模块对爬取的html格式数据进行正则匹配提取有用信息,使用json模块进行数据的格式化和写入存储
另外本次爬虫还使用了企业提供的IP池,支持爬虫程序进行多线程并发的快速请求,提高爬取效率,支持大量数据爬取。
代码实现
首先设计爬虫机制,对指定的词条进行爬取,通过文档中的超链接和相关词条标题加入待爬取队列,进行递归爬取,对规模较大的数据集爬取3层,对规模较小的数据集爬取4层。
if __name__ == '__main__':
que = []
vis = set()
que.append(('面向对象', 2262089, 1))
vis.add('面向对象')
# que.append(('网络环境', 4422188, 1))
# vis.add('网络环境')
cur = 0
docs = []
mention_list = []
doc_f = open('./docs.json', 'w', encoding='utf-8')
mention_f = open('./mentions.json', 'w', encoding='utf-8')
while True:
if cur >= len(que):
break
print(f"cur/sum: {cur}/{len(que)}")
entity_name, entity_id, depth = que[cur]
cur += 1
print("request:", 'https://baike.baidu.com/item/' + entity_name + '/' + str(entity_id))
url = 'https://baike.baidu.com/item/' + urllib.parse.quote(entity_name) + '/' + str(entity_id)
text = query(url)
doc = {
'title': entity_name,
'id': entity_id,
'content': ''
}
pattern = r"<span class=\".*?\" data-text=\"true\">(.*?)</span>"
matches = re.findall(pattern, text)
for match in matches:
# print("match:", match)
pattern = r'href="/item/([^"]+)/(\d+).*?>(.*?)</a>'
sentence = re.search(pattern, match)
if sentence:
match_entity_name, match_entity_id, match_mention = re.findall(pattern, match)[0]
match_entity_id = int(match_entity_id)
# print("a:", match_mention)
if depth < 4 and match_entity_name not in vis:
que.append((match_entity_name, match_entity_id, depth + 1))
vis.add(match_entity_name)
start_pos = len(doc['content'])
doc['content'] += match_mention
end_pos = len(doc['content'])
mention = {
'doc_id': entity_id,
'entity_id': match_entity_id,
'entity_name': match_entity_name,
'mention': match_mention,
'start_pos': start_pos,
'end_pos': end_pos
}
mention_list.append(mention)
mention_f.write(json.dumps(mention, ensure_ascii=False) + '\n')
else:
# print("span:", match)
doc['content'] += match
docs.append(doc)
doc_f.write(json.dumps(doc, ensure_ascii=False) + '\n')
# print("doc:", doc)
time.sleep(1)
# break首先直接使用requests进行http请求,请求间隔为1秒,发现爬取约30条网页信息后被百度反爬机制侦测并爬取到人机验证界面。
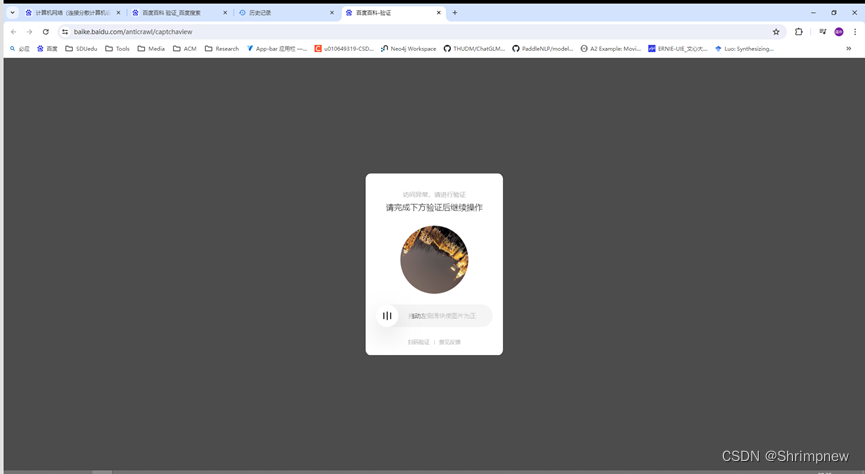
尝试设置时间间隔为随机20-30秒,重新爬取,发现在爬取约半小时后仍然被人机验证。虽然爬取时间变长,但因为爬取间隔边长,总的爬取数量仍没有什么提升。
发现浏览器请求可以不受限制,尝试携带agent请求头模拟chrome浏览器请求,并携带登录用户的cookie。
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7',
# 'User-Agent':'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US; rv:1.9.1.6) Gecko/20091201 Firefox/3.5.6'
# 'Accept-Encoding': 'gzip, deflate, br, zstd',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36',
# 'Cookie': 'zhishiTopicRequestTime=1714204958834; BIDUPSID=990AEC8E63B79ECEB2DCA3A7BEEA347E; PSTM=1688897620; BAIDUID=990AEC8E63B79ECE513E0A76649F94E7:FG=1; BDUSS=XY4cU5nUXU0NEZSRXFxRGM5UFdwUnBBRFQ5MlZUVFdWclM5Y2N5eHAtflhYTkprRVFBQUFBJCQAAAAAAAAAAAEAAAB~ktsyMjQ3MTExYQAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAANfPqmTXz6pkS; BDUSS_BFESS=XY4cU5nUXU0NEZSRXFxRGM5UFdwUnBBRFQ5MlZUVFdWclM5Y2N5eHAtflhYTkprRVFBQUFBJCQAAAAAAAAAAAEAAAB~ktsyMjQ3MTExYQAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAANfPqmTXz6pkS; Hm_lvt_55b574651fcae74b0a9f1cf9c8d7c93a=1700572499,1701322775; MCITY=-60949%3A288%3A; H_WISE_SIDS_BFESS=40416_40499_40446_40080_60129_60138; baikeVisitId=2efca0c8-7c1c-4797-8bb5-d03d9db4ab56; BAIDUID_BFESS=990AEC8E63B79ECE513E0A76649F94E7:FG=1; ZFY=hJ65HUmPh7OYnHjNKX2IUJefkgbBJUR9vLt4jjZ0hio:C; H_PS_PSSID=40499_40446_40080_60138; H_WISE_SIDS=40499_40446_40080_60138; BDORZ=B490B5EBF6F3CD402E515D22BCDA1598; BA_HECTOR=ag8k002g048l8420a0a0a180prrdan1j2pb881t; BDRCVFR[feWj1Vr5u3D]=I67x6TjHwwYf0; PSINO=1; delPer=0; channel=baidusearch; ab_sr=1.0.1_MjE4YTM5MzJkYmE0Njg1M2IxYmIwYTIyMWMzYjVmMjUwMThkZWE3NDExNzZjMjk0ODk1YWU4OGRhMjViNjRkYWYwNWYwZDUyMzhhMmY3ZjMzMGU1YWFlNjdmMjdhZTRjMjUyOTA5NDNhMzU3YjJkNDNkNTRlMTA1NjcyMTViN2MzYTQxOTE4OTQyOWZkNjMyZjU4OWE0N2M4MDJlYjkyYjU5Yjk5ZjBiYWQxMjkzNDNhZTJmYTVhMDA3YmU5YjFh; RT="z=1&dm=baidu.com&si=d50562e6-c279-4806-8422-2414ca533856&ss=lvhtdf0a&sl=9&tt=1yf&bcn=https%3A%2F%2Ffclog.baidu.com%2Flog%2Fweirwood%3Ftype%3Dperf&ld=gyo&ul=hla"'
'Connection': 'close'
}在爬取半天,约爬取1300条网页后仍然被人机验证,约半小时到一小时内可以恢复访问,中间的爬取会被阻塞,效率太低。
尝试配置IP池,使用IP代理的方式每次请求使用不同的IP,防止被反爬机制识别到同一IP的操作。
使用IP池的结果可以正确避免被反爬机制识别,但存在部分IP连接超时,因此需要对每次代理访问进行多次尝试。
使用IP池后,由于每次访问使用不同IP,即访问请求可以并发且时间间隔降低,因此时间间隔设置为随机1-5秒
爬虫结果
我们对计算机网络、面向对象、软件工程、计算机组织与结构进行了相关词条数据爬取,总共获得了约1.5GB的文本数据,包括词条描述和词条间关系,大概占比1:1


模型训练
UIE使用daccano进行数据标注,并提供了将daccano数据转化为训练数据格式的代码。

一、将爬虫获取的json数据转化为daccano数据的格式
我们根据爬取的大量文档文本和其中的超链接实体关系,对原文本中的已标注实体转化成daccano标注的实体的格式
import json
import re
def split_doc(doc):
single_sentences = re.split(r"(?<=[。!?])", docs[doc_title])
sentences = []
merged_sentence = ''
for sentence in single_sentences:
if len(merged_sentence) + len(sentence) < 512:
merged_sentence += sentence
else:
sentences.append(merged_sentence)
merged_sentence = sentence
if merged_sentence != '':
sentences.append(merged_sentence)
return sentences
if __name__ == '__main__':
domain_name = 'computer_network'
doc_f = open('/home/yunpu/Data/codes/VCRS/data/wiki_data/' + domain_name + '_docs.json' ,'r')
mention_f = open('/home/yunpu/Data/codes/VCRS/data/wiki_data/' + domain_name + '_mentions_with_title.json', 'r')
out_f = open('/home/yunpu/Data/codes/VCRS/UIE/data/' + domain_name + '_daccano.jsonl' ,'w')
# entitys = set()
# docs = {}
# for line in doc_f:
# doc = json.loads(line)
# assert doc['title'] not in entitys
# entitys.add(doc['title'])
# docs[doc['title']] = doc['content']
doc_titles = set()
docs = {}
entity_id = {}
cnt = 0
mentions = {}
for line in doc_f:
doc = json.loads(line)
assert doc['title'] not in doc_titles
doc_titles.add(doc['title'])
docs[doc['title']] = doc['content']
entity_id[doc['title']] = cnt
cnt += 1
for line in mention_f:
mention = json.loads(line)
if mention['doc_title'] not in mentions.keys():
mentions[mention['doc_title']] = [mention]
else:
mentions[mention['doc_title']].append(mention)
sample_cnt = 0
for doc_title in docs.keys():
if doc_title not in mentions.keys():
continue
# sentences = re.split(r"(?<=[。!?])", docs[doc_title])
sentences = split_doc(docs[doc_title])
if sample_cnt == 0:
print(sentences)
prelen = 0
cur = 0
for sentence in sentences:
if len(sentence) < 512:
sample = {}
sample['id'] = sample_cnt
sample_cnt += 1
sample['text'] = sentence
sample['relations'] = []
sample['entities'] = []
while cur < len(mentions[doc_title]) and mentions[doc_title][cur]['start_pos'] >= prelen and mentions[doc_title][cur]['end_pos'] <= prelen + len(sentence):
if mentions[doc_title][cur]['entity_name'] not in entity_id.keys():
entity_id[mentions[doc_title][cur]['entity_name']] = cnt
cnt += 1
entity = {
"id": entity_id[mentions[doc_title][cur]['entity_name']],
"start_offset": mentions[doc_title][cur]['start_pos'] - prelen,
"end_offset": mentions[doc_title][cur]['end_pos'] - prelen,
"label": "实体"
}
sample['entities'].append(entity)
cur += 1
if len(sample['entities']) == 0:
sample_cnt -= 1
else:
out_f.write(json.dumps(sample, ensure_ascii=False) + '\n')
prelen += len(sentence)
# if sample_cnt > 50:
# break
代码标注后的daccano数据
{"id": 0, "text": "计算机网络是指将地理位置不同的具有独立功能的多台计算机及其外部设备,通过通信线路和通信设备连接起来,在网络操作系统,网络管理软件及网络通信协议的管理和协调下,实现资源共享和信息传递的计算机系统。计算机网络主要是由一些通用的、可编程的硬件互连而成的。这些可编程的硬件能够用来传送多种不同类型的数据,并能支持广泛的和日益增长的应用。计算机网络Computer network计算机网络系统互联网信息的传输与共享网络操作系统计算机网络也称计算机通信网。关于计算机网络的最简单定义是:一些相互连接的、以共享资源为目的的、自治的计算机的集合。若按此定义,则早期的面向终端的网络都不能算是计算机网络,而只能称为联机系统(因为那时的许多终端不能算是自治的计算机)。但随着硬件价格的下降,许多终端都具有一定的智能,因而“终端”和“自治的计算机”逐渐失去了严格的界限。若用微型计算机作为终端使用,按上述定义,则早期的那种面向终端的网络也可称为计算机网络。另外,从逻辑功能上看,计算机网络是以传输信息为基础目的,用通信线路将多个计算机连接起来的计算机系统的集合,一个计算机网络组成包括传输介质和通信设备。", "relations": [], "entities": [{"id": 1, "start_offset": 8, "end_offset": 12, "label": "实体"}, {"id": 2, "start_offset": 29, "end_offset": 33, "label": "实体"}, {"id": 3, "start_offset": 36, "end_offset": 40, "label": "实体"}, {"id": 4, "start_offset": 51, "end_offset": 57, "label": "实体"}, {"id": 5, "start_offset": 58, "end_offset": 64, "label": "实体"}, {"id": 6, "start_offset": 65, "end_offset": 71, "label": "实体"}, {"id": 7, "start_offset": 81, "end_offset": 85, "label": "实体"}, {"id": 8, "start_offset": 86, "end_offset": 90, "label": "实体"}, {"id": 9, "start_offset": 91, "end_offset": 96, "label": "实体"}, {"id": 10, "start_offset": 216, "end_offset": 222, "label": "实体"}, {"id": 11, "start_offset": 247, "end_offset": 251, "label": "实体"}, {"id": 12, "start_offset": 299, "end_offset": 303, "label": "实体"}, {"id": 13, "start_offset": 377, "end_offset": 382, "label": "实体"}, {"id": 3, "start_offset": 447, "end_offset": 451, "label": "实体"}, {"id": 14, "start_offset": 482, "end_offset": 486, "label": "实体"}, {"id": 15, "start_offset": 487, "end_offset": 491, "label": "实体"}]}二、人工标注
因为百度词条中仅对一部分实体进行了标注,重复实体被忽略,因此我们首先使用代码对相同实体进行了补充标注,并人工对一些代码忽略的实体进行了标注
Doccano 是一个用于文本标注的开源工具,支持多种语言任务如命名实体识别、情感分析和文本分类。以下是详细的本地部署步骤。
数据标注
先导入刚刚代码标注的json文件
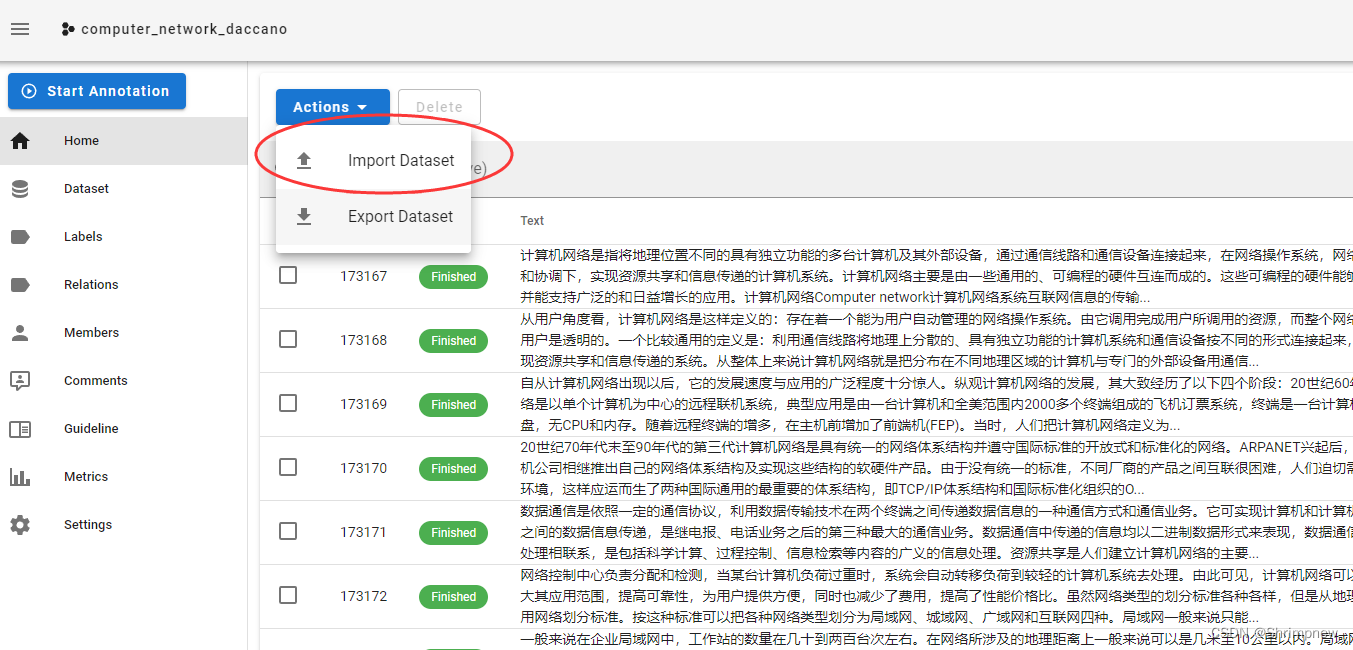
可以看到我们刚刚使用代码进行的自动标注已经导入了daccano的系统之中,我们在这个基础上对遗落的实体进行了标注
最终我们取得了约50条500字长度的标注数据对UIE模型进行微调

三、数据格式转换
使用paddle提供的数据格式转换代码
PaddleNLP/model_zoo/uie at develop · PaddlePaddle/PaddleNLP · GitHub
python doccano.py \
--doccano_file ./data/doccano_ext.json \
--task_type ext \
--save_dir ./data \
--splits 0.8 0.2 0 \
--schema_lang ch转换后的数据格式
{"id":0,"text":"计算机网络是指将地理位置不同的具有独立功能的多台计算机及其外部设备,通过通信线路和通信设备连接起来,在网络操作系统,网络管理软件及网络通信协议的管理和协调下,实现资源共享和信息传递的计算机系统。计算机网络主要是由一些通用的、可编程的硬件互连而成的。这些可编程的硬件能够用来传送多种不同类型的数据,并能支持广泛的和日益增长的应用。计算机网络Computer network计算机网络系统互联网信息的传输与共享网络操作系统计算机网络也称计算机通信网。关于计算机网络的最简单定义是:一些相互连接的、以共享资源为目的的、自治的计算机的集合。若按此定义,则早期的面向终端的网络都不能算是计算机网络,而只能称为联机系统(因为那时的许多终端不能算是自治的计算机)。但随着硬件价格的下降,许多终端都具有一定的智能,因而“终端”和“自治的计算机”逐渐失去了严格的界限。若用微型计算机作为终端使用,按上述定义,则早期的那种面向终端的网络也可称为计算机网络。另外,从逻辑功能上看,计算机网络是以传输信息为基础目的,用通信线路将多个计算机连接起来的计算机系统的集合,一个计算机网络组成包括传输介质和通信设备。","entities":[{"id":350447,"label":"实体","start_offset":8,"end_offset":12},{"id":350448,"label":"实体","start_offset":29,"end_offset":33},{"id":350449,"label":"实体","start_offset":36,"end_offset":40},{"id":350450,"label":"实体","start_offset":51,"end_offset":57},{"id":350451,"label":"实体","start_offset":58,"end_offset":64},{"id":350452,"label":"实体","start_offset":65,"end_offset":71},{"id":350453,"label":"实体","start_offset":81,"end_offset":85},{"id":350454,"label":"实体","start_offset":86,"end_offset":90},{"id":350455,"label":"实体","start_offset":91,"end_offset":96},{"id":350456,"label":"实体","start_offset":216,"end_offset":222},{"id":350457,"label":"实体","start_offset":247,"end_offset":251},{"id":350458,"label":"实体","start_offset":299,"end_offset":303},{"id":350459,"label":"实体","start_offset":377,"end_offset":382},{"id":350460,"label":"实体","start_offset":447,"end_offset":451},{"id":350461,"label":"实体","start_offset":482,"end_offset":486},{"id":350462,"label":"实体","start_offset":487,"end_offset":491},{"id":350885,"label":"实体","start_offset":0,"end_offset":5},{"id":350886,"label":"实体","start_offset":41,"end_offset":45},{"id":350887,"label":"实体","start_offset":24,"end_offset":27},{"id":350888,"label":"实体","start_offset":209,"end_offset":214},{"id":350889,"label":"实体","start_offset":473,"end_offset":478},{"id":350890,"label":"实体","start_offset":454,"end_offset":457}],"relations":[{"id":222,"from_id":350885,"to_id":350453,"type":"功能"},{"id":223,"from_id":350885,"to_id":350454,"type":"功能"},{"id":224,"from_id":350885,"to_id":350455,"type":"定义"},{"id":225,"from_id":350888,"to_id":350456,"type":"别名"},{"id":226,"from_id":350889,"to_id":350461,"type":"包含"},{"id":227,"from_id":350889,"to_id":350462,"type":"包含"},{"id":228,"from_id":350460,"to_id":350890,"type":"连接"},{"id":229,"from_id":350449,"to_id":350887,"type":"连接"},{"id":230,"from_id":350449,"to_id":350448,"type":"连接"},{"id":231,"from_id":350886,"to_id":350887,"type":"连接"},{"id":232,"from_id":350886,"to_id":350448,"type":"连接"},{"id":233,"from_id":350885,"to_id":350450,"type":"包含"},{"id":234,"from_id":350885,"to_id":350451,"type":"包含"},{"id":235,"from_id":350885,"to_id":350452,"type":"包含"}],"Comments":[]}四、模型微调
继续使用paddle提供的微调代码,设置微调参数
export finetuned_model=./checkpoint/model_best
python finetune.py \
--device gpu \
--logging_steps 10 \
--save_steps 100 \
--eval_steps 100 \
--seed 42 \
--model_name_or_path uie-base \
--output_dir $finetuned_model \
--train_path data/train.txt \
--dev_path data/dev.txt \
--max_seq_length 512 \
--per_device_eval_batch_size 16 \
--per_device_train_batch_size 16 \
--num_train_epochs 20 \
--learning_rate 1e-5 \
--label_names "start_positions" "end_positions" \
--do_train \
--do_eval \
--do_export \
--export_model_dir $finetuned_model \
--overwrite_output_dir \
--disable_tqdm True \
--metric_for_best_model eval_f1 \
--load_best_model_at_end True \
--save_total_limit 1
五、模型效果评估
python evaluate.py \
--model_path ./checkpoint/model_best \
--test_path ./data/dev.txt \
--batch_size 16 \
--max_seq_len 512 \
--multilingual
模型在实体识别任务上取得了Evaluation Precision: 0.61081 | Recall: 0.58020 | F1: 0.59511的成绩,我认为已经满足我们的实体识别标注需求。
前端开发
前端开发方面相关的工作已经做了以下几个方面
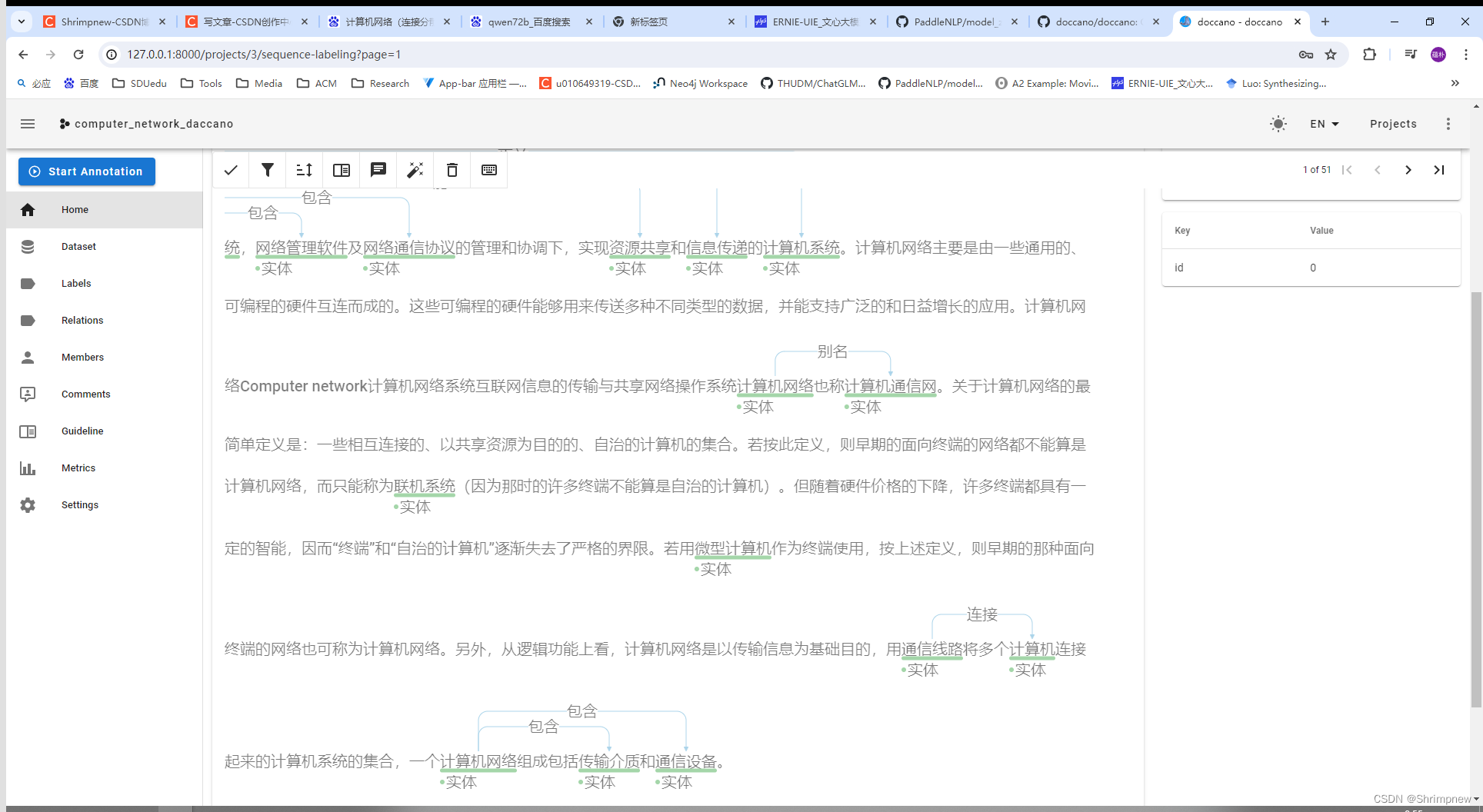
首先,使用streamlit前端框架实现了一个简易的对话界面,通过本地部署大语言模型对该功能进行了测试,能够正确的进行对话,后续将连接小组自己训练和微调的大语言模型。并将streamlit的对话界面嵌入到vue框架中。
其次是搭建好了vue前端框架,写了几个具有更加灵活的使用方法且更加美观的vue组件,例如card.vue,SideBar.vue, SideBarLink.vue,BaseInput.vue。这几个组件可以使系统的展示结构更加鲜明,条理,美观。同时通过组件添加的插槽和属性,可以很方便地创建和定制各种组件,使其适应不同的使用场景和需求。
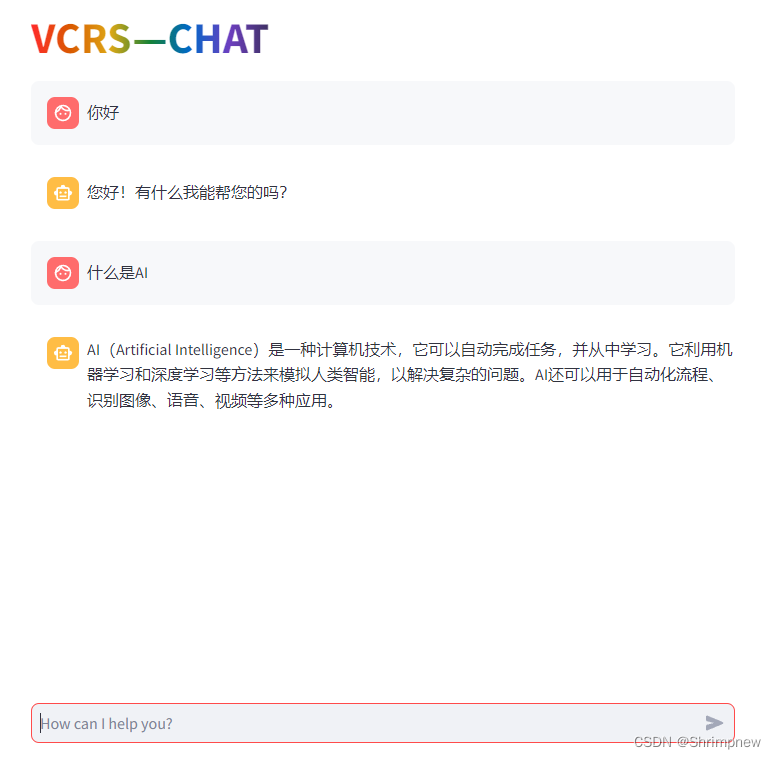
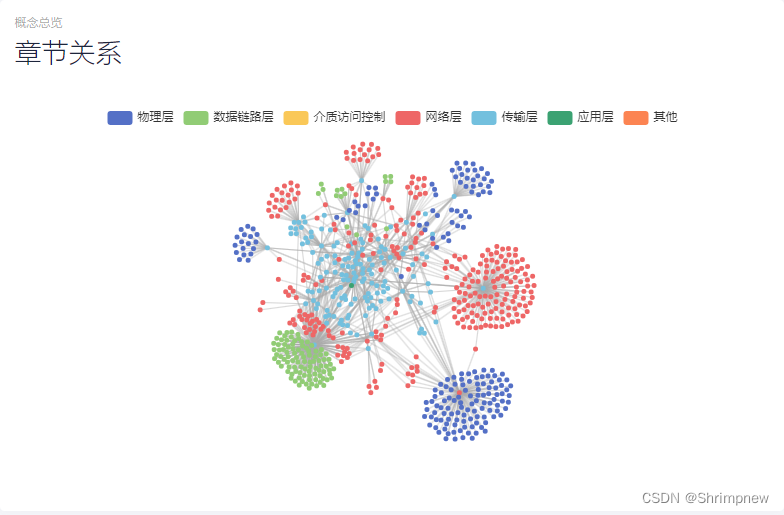
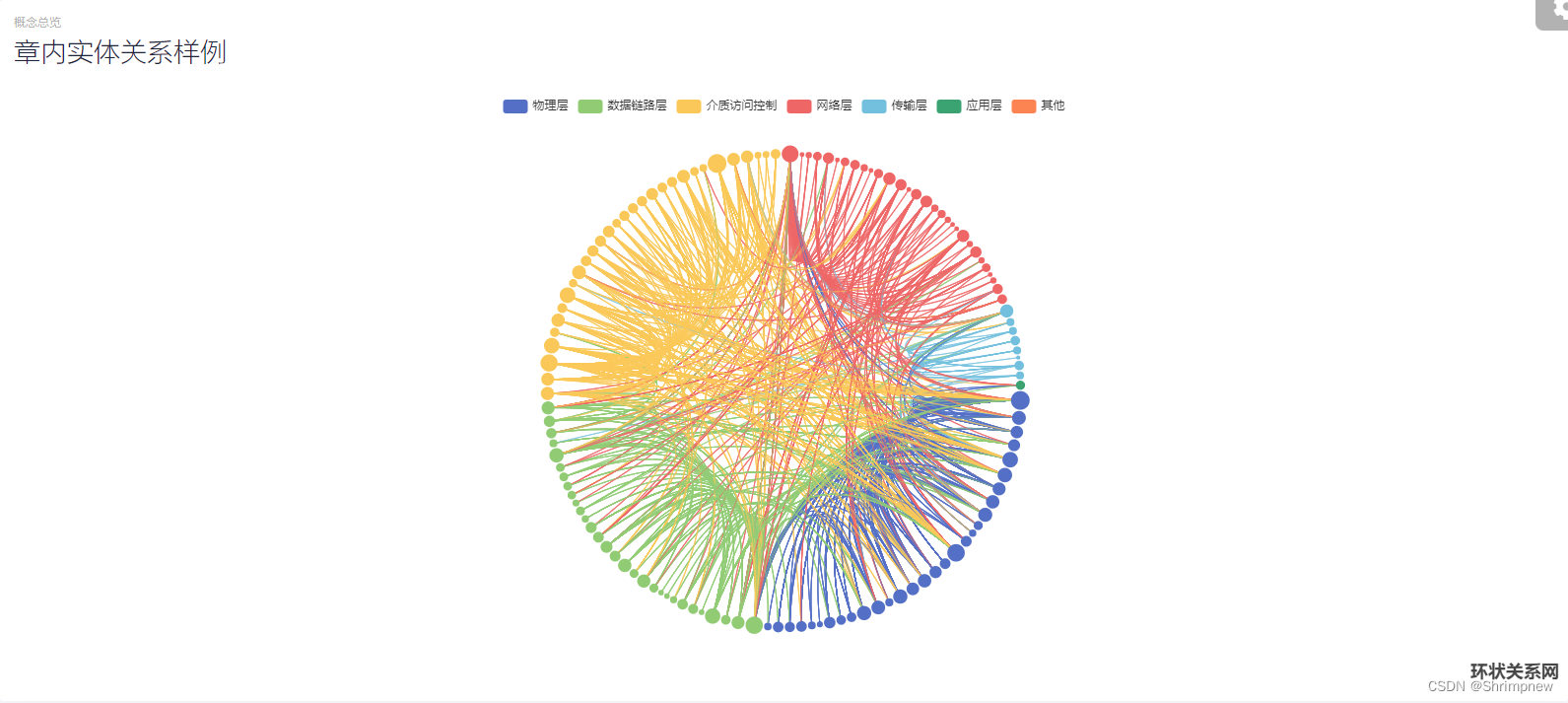
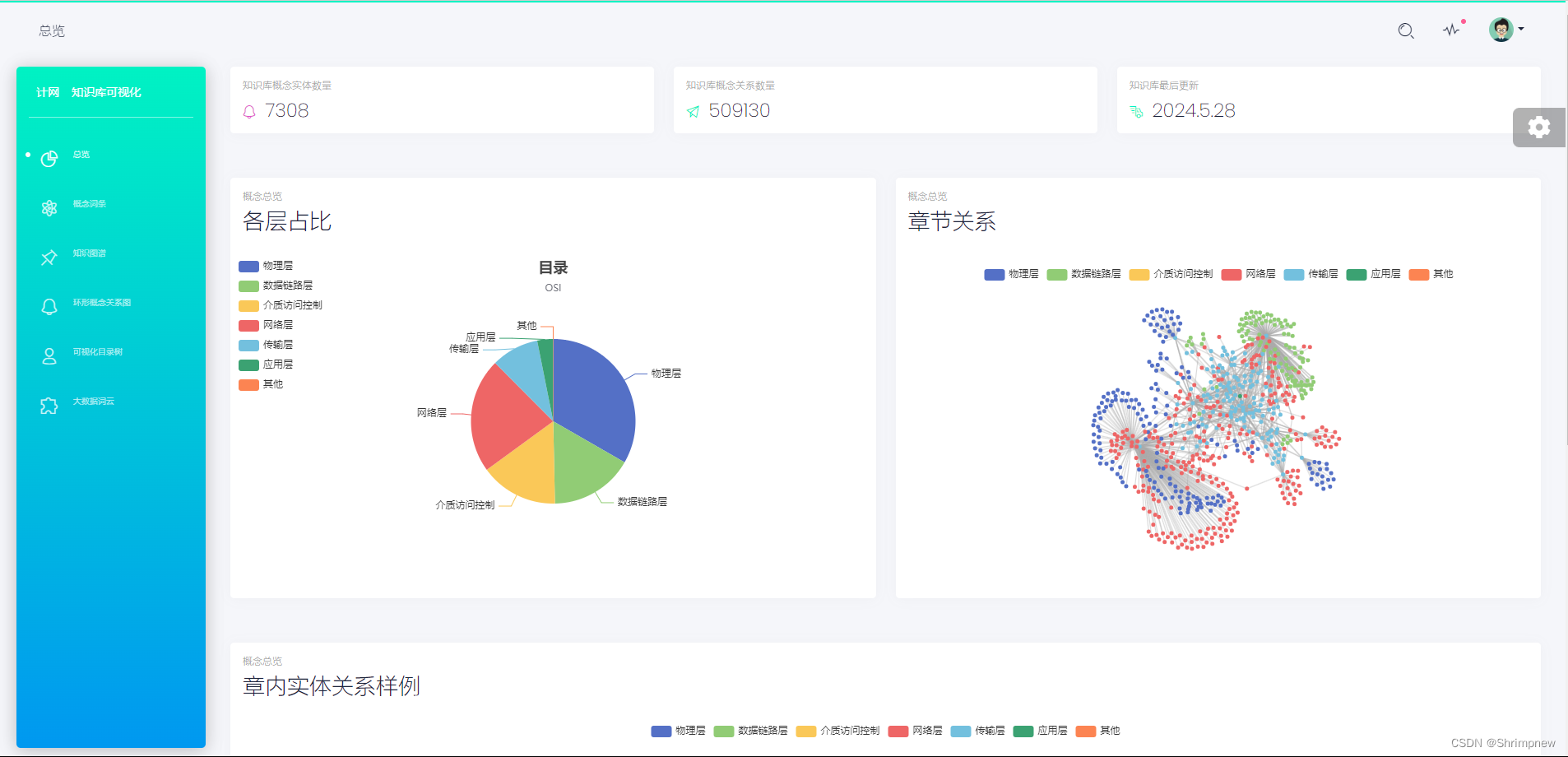
然后以计算机网络的相关知识为例,做了几个方面的数据分析和可视化。首先统计分析了计算机网络知识库里的所有知识在计算机网络分层架构上的分布情况。然后以层为分类做了章节关系的知识图谱的可视化,再对每个章节内部的知识点根据他们之间的关系做了章节内部的知识图谱的可视化。
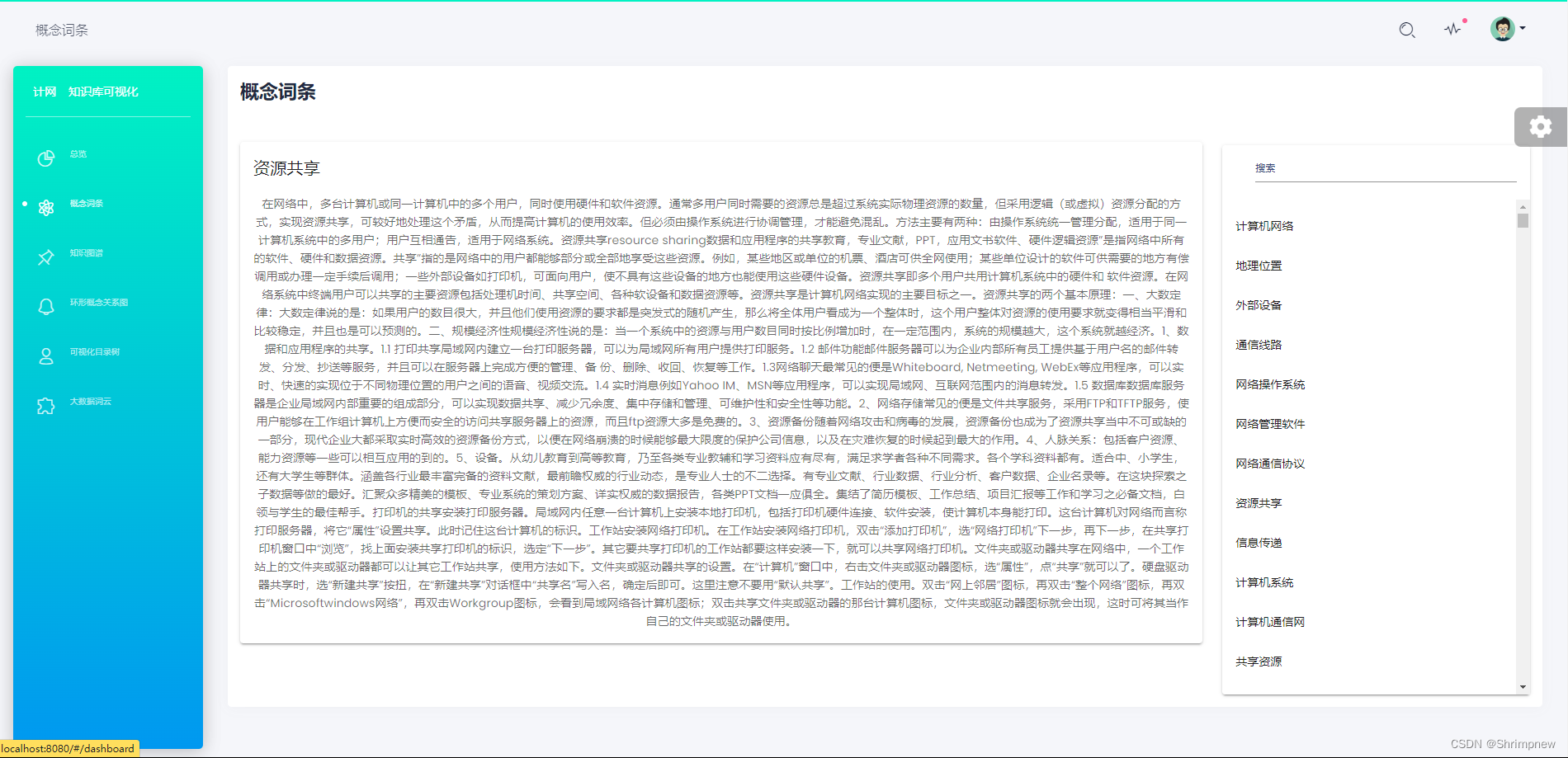
然后实现了对计算机网络所有知识实体的概念词条的展示。
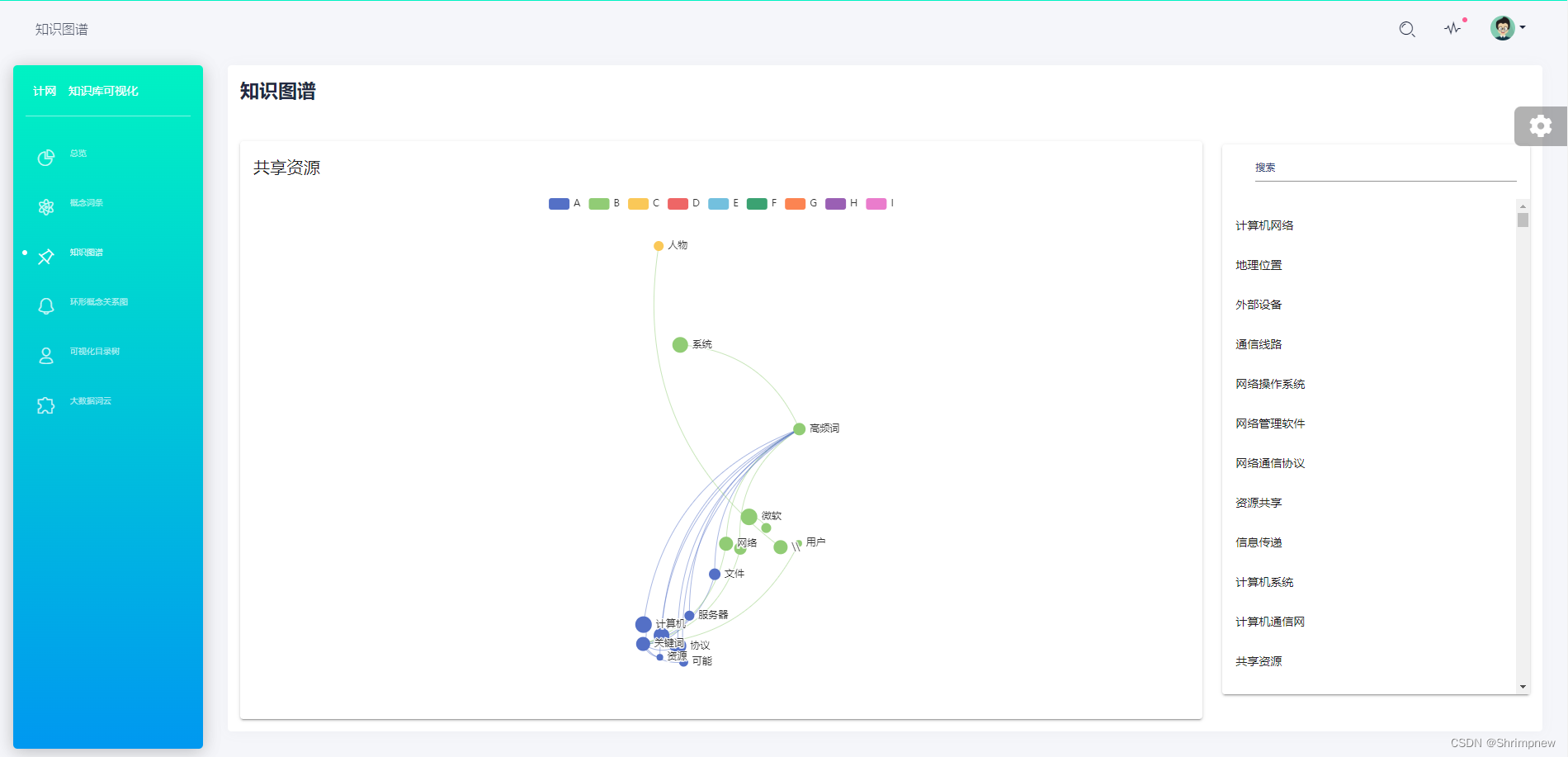
再对每一个知识实体进行进一步分析,由它们与其他各实体之间的关系出发为每一个实体进行了知识图谱的构建和可视化。可以搜索任意一个实体展示其与其他实体之间的联系。可以快速浏览整个知识体系,理解各个知识点的全貌和具体细节,而无需逐一阅读文本描述。
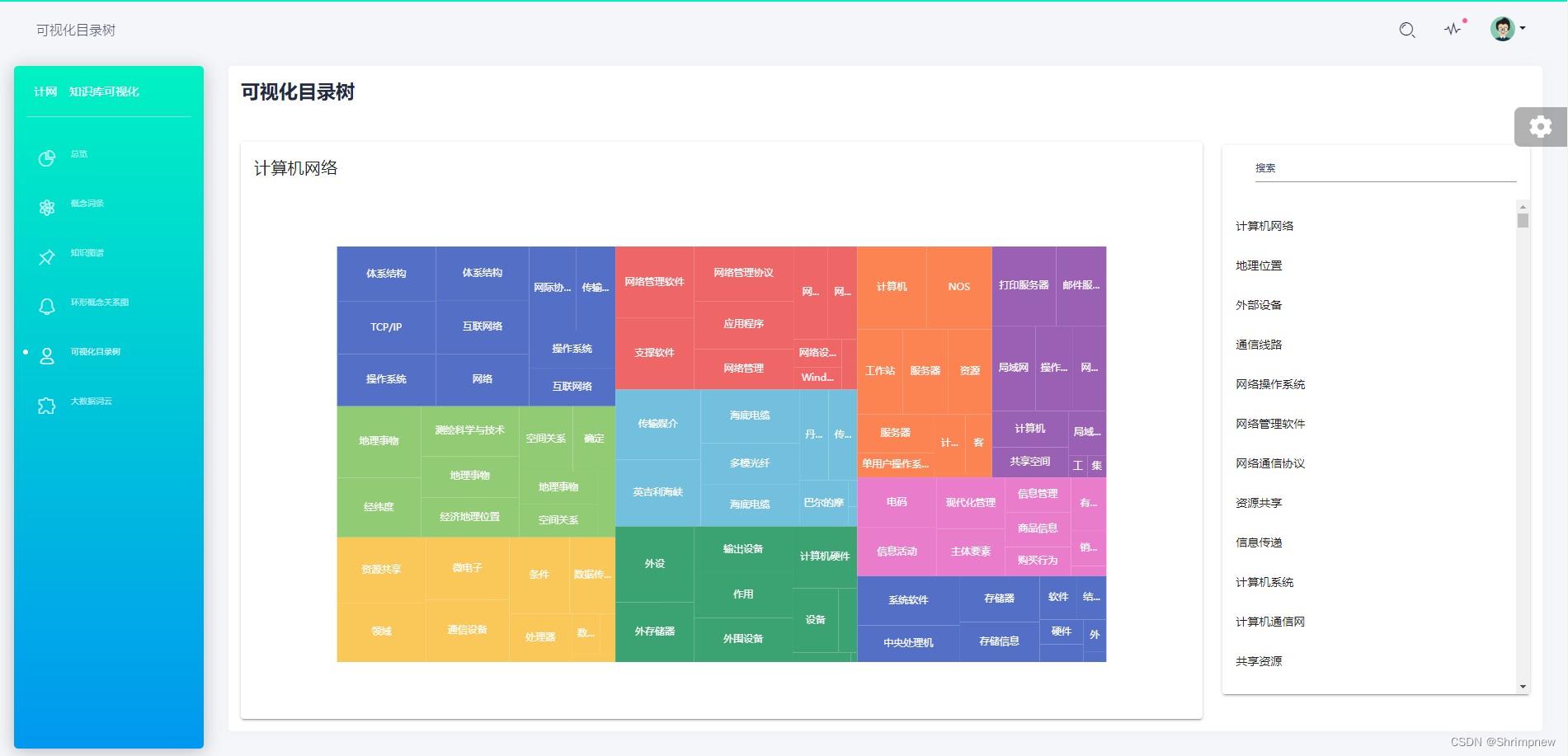
再根据实体之间的联系,具有描述实体之间包含与被包含关系的数据。对每一个实体实现一个矩形目录的可视化,可以通过看每个实体的矩形目录,清楚的获取该实体包含哪些内容,以及这些内容之间的并列或者嵌套包含的关系。有大到小,有简入深,掌握知识的整体性和条理性。
最后对每一个实体,根据它的概念词条,使用python的jieba库进行分词,使用wordcloud库生成词云。并进行了展示。

RAG文本向量化检索
可视化问答系统的向量化是非常重要的一环.
可视化问答系统数据库的向量化主要考虑将数据预处理部分得到的纯txt文件通过faiss向量库标准化为向量以便后续进行RAG增强检索.
Faiss向量化的基本步骤:
文本向量化:将查询文本转换为向量形式,以便与存储在Faiss数据库中的向量进行比较。
相似度搜索:在Faiss数据库中搜索与查询向量最相似的向量。
返回结果:根据搜索结果返回对应的文档或信息。
文本嵌入
首先需要使用Embedding模型将文本转化为嵌入向量, 才能在后续将这些向量存储到向量库中.
为什么使用Embedding模型对文本数据进行处理?
Embedding将高维度、非结构化的文本转换为固定维度的向量表示,从而便于计算和分析。
Embedding模型通过在大规模语料库上进行训练,能够捕捉词汇和句子之间的语义关系,使得相似含义的文本在向量空间中距离更近。这种向量化表示不仅简化了文本处理的复杂性,还能显著提高后续任务(如文本分类、聚类和搜索)的效率和准确性。
代码示例 (使用sentence-transformer库)
使用Embedding模型:all-MiniLM-L6-v2
该模型基于微软的 MiniLM 架构, 是一种轻量级、低延迟的语言模型,专门设计用于高效的文本嵌入生成。
all-MiniLM-L6-v2 是一个双塔模型,包含 6 层 Transformer 网络,能够将句子或文本片段编码为固定大小的高维向量(嵌入向量)。
这些向量保留了文本的语义信息,使得相似含义的句子在向量空间中距离更近。该模型在大规模多语料库上进行了预训练,具备较强的跨领域和跨语言的适应能力。
all-MiniLM-L6-v2 的参数量较少,因此在计算资源有限的环境中也能高效运行。它在嵌入质量和计算速度之间提供了良好的权衡,非常适合需要快速生成高质量文本嵌入的应用场景,如语义搜索、文本聚类和文本分类等。通过使用 all-MiniLM-L6-v2,开发者可以在保持高精度的同时,实现高效的文本处理和相似性计算。
文本嵌入后,考虑对嵌入的向量归入Faiss库 创建L2距离的Faiss索引,使用Faiss索引查找5个最近邻向量。
将知识嵌入模型Prompt中
检索到的文档内容:
Document 1: "Paris is the capital and most populous city of France."
Document 2: "France, officially the French Republic, is a country primarily located in Western Europe."
Document 3: "The capital city of France is Paris, which is known for its art, fashion, and culture."
模型Prompt模板:
You should answer the Query by these contexts
Context:通过用户输入在向量库中检索到的相关文档
Query:用户输入
Answer:模型回复
最终提交给模型的回复:
You should answer the Query by these contexts
Context:
Document 1:
Paris is the capital and most populous city of France.
Document 2:
France, officially the French Republic, is a country primarily located in Western Europe.
Document 3:
The capital city of France is Paris, which is known for its art, fashion, and culture.
Query: What is the capital of France?
Answer:


























 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









