







Every row in an HBase table has a unique identifier called its rowkey. Other coordinates
are used to locate a piece of data in an HBase table, but the rowkey is primary. Just like
a primary key in a table in a relational database, rowkey values are distinct across all
rows in an HBase table. Every interaction with data in a table begins with the rowkey.
Every user in TwitBase is unique, so the user’s name makes a convenient rowkey for
the users table; that’s what you’ll use.
The HBase API is broken into operations called commands. There are five primitive
commands for interacting with HBase: Get, Put, Delete, Scan, and Increment. The
command used to store data is Put. To store data in a table, you’ll need to create a Put
instance. Creating a Put instance from a rowkey looks like this:
Put p = new Put(Bytes.toBytes("Mark Twain"));
Why can’t you store the user’s name directly? All data in HBase is stored as raw data in
the form of a byte array, and that includes the rowkeys. The Java client library provides
a utility class, Bytes, for converting various Java data types to and from byte[] so you
don’t have to worry about doing it yourself. Note that this Put instance has not been
inserted into the table yet. You’re only building the object right now.
一.Storing data
Now that you’ve staged a command for adding data to HBase, you still need to provide
data to store. You can start by storing basic information about Mark, such as his email
address and password. What happens if another person comes along whose name is
also Mark Twain? They’ll conflict, and you won’t be able to store data about them in
TwitBase. Instead of using the person’s real name as the rowkey, let’s use a unique
username and store their real name in a column. Putting (no pun intended!) it
all together:
<span style="font-size:14px;">Put p = new Put(Bytes.toBytes("<strong>TheRealMT</strong>"));
</span><span style="font-size:14px;">p.add(Bytes.toBytes("info"),
Bytes.toBytes("name"),
Bytes.toBytes("Mark Twain"));
p.add(Bytes.toBytes("info"),
Bytes.toBytes("email"),
Bytes.toBytes("samuel@clemens.org"));
p.add(Bytes.toBytes("info"),
Bytes.toBytes("password"),
Bytes.toBytes("Langhorne"));</span>Remember, HBase uses coordinates to locate a piece of data within a table. The rowkey
is the first coordinate, followed by the column family. When used as a data coordinate,
the column family serves to group columns. The next coordinate is the column qualifier,
often called simply column, or qual, once you’re versed in HBase vernacular. The column
qualifiers in this example are name, email, and password. Because HBase is schema-less,
you never need to predefine the column qualifiers or assign them types. They’re
dynamic; all you need is a name that you give them at write time. These three coordinates
define the location of a cell. The cell is where HBase stores data as a value. A cell
is identified by its [rowkey, column family, column qualifier] coordinate within a
table. The previous code stores three values in three cells within a single row. The cell
storing Mark’s name has the coordinates [TheRealMT, info, name].
The last step in writing data to HBase is sending the command to the table. That
part is easy:
HTableInterface usersTable = pool.getTable("users");
Put p = new Put(Bytes.toBytes("TheRealMT"));
p.add(...);
usersTable.put(p);
usersTable.close();二、Modifying data
Changing data in HBase is done the same way you store new data: create a Put object,
give it some data at the appropriate coordinates, and send it to the table. Let’s update
Mark’s password to something more secure.
Put p = new Put(Bytes.toBytes("TheRealMT"));
p.add(Bytes.toBytes("info"),
Bytes.toBytes("password"),
Bytes.toBytes("abc123"));
usersTable.put(p);Under the hood: the HBase write path
Whether you use Put to record a new row in HBase or to modify an existing row, the
internal process is the same. HBase receives the command and persists the change, or
throws an exception if the write fails. When a write is made, by default, it goes into two
places: the write-ahead log (WAL), also referred to as the HLog, and the MemStore
(figure 2.1). The default behavior of HBase recording the write in both places is in
order to maintain data durability. Only after the change is written to and confirmed in
both places is the write considered complete.
The MemStore is a write buffer where HBase accumulates data in memory before a
permanent write. Its contents are flushed to disk to form an HFile when the MemStore
fills up. It doesn’t write to an existing HFile but instead forms a new file on every flush.
The HFile is the underlying storage format for HBase. HFiles belong to a column family,
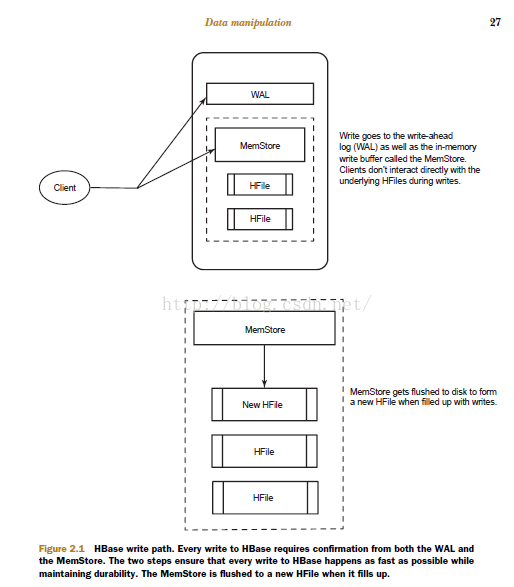
and a column family can have multiple HFiles. But a single HFile can’t have data for multiple
column families. There is one MemStore per column family.1
Failures are common in large distributed systems, and HBase is no exception.
Imagine that the server hosting a MemStore that has not yet been flushed crashes.
You’ll lose the data that was in memory but not yet persisted. HBase safeguards against
that by writing to the WAL before the write completes. Every server that’s part of theHBase cluster keeps a WAL to record changes as they happen. The WAL is a file on the
underlying file system. A write isn’t considered successful until the new WAL entry is
successfully written. This guarantee makes HBase as durable as the file system backing
it. Most of the time, HBase is backed by the Hadoop Distributed Filesystem (HDFS).
If HBase goes down, the data that was not yet flushed from the MemStore to the
HFile can be recovered by replaying the WAL. You don’t have to do this manually. It’s
all handled under the hood by HBase as a part of the recovery process. There is a single
WAL per HBase server, shared by all tables (and their column families) served from
that server.
As you can imagine, skipping the WAL during writes can help improve write performance.
There’s one less thing to do, right? We don’t recommend disabling the WAL
unless you’re willing to lose data when things fail. In case you want to experiment, you
can disable the WAL like this:
Put p = new Put();
p.setWriteToWAL(false);NOTE Not writing to the WAL comes at the cost of increased risk of losing data
in case of RegionServer failure. Disable the WAL, and HBase can’t recover your
data in the face of failure. Any writes that haven’t flushed to disk will be lost.
三、Reading data
Reading data back out of HBase is as easy as writing. Make a Get command instance,
tell it what cells you’re interested in, and send it to the table:
Get g = new Get(Bytes.toBytes("TheRealMT"));
Result r = usersTable.get(g);The table gives you back a Result instance containing your data. This instance contains
all the columns from all the column families that exist for the row. That’s potentially
far more data than you need. You can limit the amount of data returned by
placing restrictions on the Get instance. To retrieve only the password column, execute
addColumn(). The same can be done per column family using addFamily(), in
which case it’ll return all the columns in the specified column family:
Get g = new Get(Bytes.toBytes("TheRealMT"));
g.addColumn(
Bytes.toBytes("info"),
Bytes.toBytes("password"));
Result r = usersTable.get(g);
Retrieve the specific value and convert it back from bytes like so:
Get g = new Get(Bytes.toBytes("TheRealMT"));
g.addFamily(Bytes.toBytes("info"));
byte[] b = r.getValue(
Bytes.toBytes("info"),
Bytes.toBytes("email"));
String email = Bytes.toString(b); // "samuel@clemens.org"Under the hood: the HBase read path
As a general rule, if you want fast access to data, keep it ordered and keep as much of
it as possible in memory. HBase accomplishes both of these goals, allowing it to serve
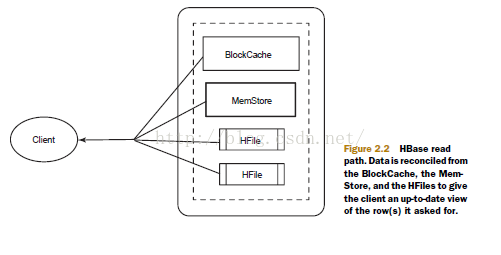
millisecond reads in most cases. A read against HBase must be reconciled between the
persisted HFiles and the data still in the MemStore. HBase has an LRU cache for reads.
This cache, also called the BlockCache, sits in the JVM heap alongside the MemStore.
The BlockCache is designed to keep frequently accessed data from the HFiles in memory
so as to avoid disk reads. Each column family has its own BlockCache.
Understanding the BlockCache is an important part of understanding how to run
HBase at optimal performance. The “Block” in BlockCache is the unit of data that
HBase reads from disk in a single pass. The HFile is physically laid out as a sequence of
blocks plus an index over those blocks. This means reading a block from HBase requires
only looking up that block’s location in the index and retrieving it from disk. The block
is the smallest indexed unit of data and is the smallest unit of data that can be read from
disk. The block size is configured per column family, and the default value is 64 KB. You
may want to tweak this value larger or smaller depending on your use case. If you primarily
perform random lookups, you likely want a more granular block index, so a
smaller block size is preferred. Having smaller blocks creates a larger index and thereby
consumes more memory. If you frequently perform sequential scans, reading many
blocks at a time, you can afford a larger block size. This allows you to save on memory
because larger blocks mean fewer index entries and thus a smaller index.
Reading a row from HBase requires first checking the MemStore for any pending
modifications. Then the BlockCache is examined to see if the block containing this
row has been recently accessed. Finally, the relevant HFiles on disk are accessed. There
are more things going on under the hood, but this is the overall outline. Figure 2.2
illustrates the read path.
Note that HFiles contain a snapshot of the MemStore at the point when it was
flushed. Data for a complete row can be stored across multiple HFiles. In order to read
a complete row, HBase must read across all HFiles that might contain information for
that row in order to compose the complete record.
四、 Deleting data
Deleting data from HBase works just like storing it. You make an instance of the
Delete command, constructed with a rowkey:
Delete d = new Delete(Bytes.toBytes("TheRealMT"));
usersTable.delete(d);You can delete only part of a row by specifying additional coordinates:
Delete d = new Delete(Bytes.toBytes("TheRealMT"));
d.deleteColumns(
Bytes.toBytes("info"),
Bytes.toBytes("email"));
usersTable.delete(d);The method deleteColumns() removes a cell entirely from the row. This is a distinct
method from deleteColumn() (notice the missing s at the end of the method name),
which operates on the content of a cell.
五、Compactions: HBase housekeeping
The Delete command doesn’t delete the value immediately. Instead, it marks the
record for deletion. That is, a new “tombstone” record is written for that value, marking
it as deleted. The tombstone is used to indicate that the deleted value should no
longer be included in Get or Scan results. Because HFiles are immutable, it’s not until
a major compaction runs that these tombstone records are reconciled and space is truly
recovered from deleted records.
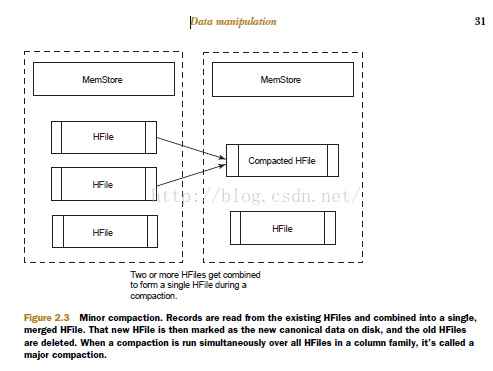
Compactions come in two flavors: minor and major. Both types result in a consolidation
of the data persisted in HFiles. A minor compaction folds HFiles together,
creating a larger HFile from multiple smaller HFiles, as shown in figure 2.3. Restricting
the number of HFiles is important for read performance, because all of them
must be referenced to read a complete row. During the compaction, HBase reads the
content of the existing HFiles, writing records into a new one. Then, it swaps in the
new HFile as the current active one and deletes the old ones that formed the new
one.2 HBase decides which HFiles to compact based on their number and relative
sizes. Minor compactions are designed to be minimally detrimental to HBase performance,
so there is an upper limit on the number of HFiles involved. All of these settings
are configurable.
When a compaction operates over all HFiles in a column family in a given region, it’s
called a major compaction. Upon completion of a major compaction, all HFiles in the
column family are merged into a single file. Major compactions can also be triggered
for the entire table (or a particular region) manually from the shell. This is a relatively
expensive operation and isn’t done often. Minor compactions, on the other hand, are
relatively lightweight and happen more frequently. Major compactions are the only
chance HBase has to clean up deleted records. Resolving a delete requires removing
both the deleted record and the deletion marker. There’s no guarantee that both the
record and marker are in the same HFile. A major compaction is the only time when
HBase is guaranteed to have access to both of these entries at the same time.
The compaction process is described in greater detail, along with incremental
illustrations, in a post on the NGDATA blog.3
六、Versioned data
In addition to being a schema-less database, HBase is also versioned. For example, you
can look back in time for the original password:
List<KeyValue> passwords = r.getColumn(
Bytes.toBytes("info"),
Bytes.toBytes("password"));
b = passwords.get(0).getValue();
String currentPasswd = Bytes.toString(b); // "abc123"
b = passwords.get(1).getValue();
String prevPasswd = Bytes.toString(b); // "Langhorne"Every time you perform an operation on a cell, HBase implicitly stores a new version.
Creating, modifying, and deleting a cell are all treated identically; they’re all new versions.
Get requests reconcile which version to return based on provided parameters.
The version is used as the final coordinate when accessing a specific cell value. HBase
uses the current time4 in milliseconds when a version isn’t specified, so the version
number is represented as a long. By default, HBase stores only the last three versions;
this is configurable per column family. Each version of data within a cell contributes
one KeyValue instance to the Result. You can inspect the version information in a
KeyValue instance with its getTimestamp() method:
long version =passwords.get(0).getTimestamp(); // 1329088818321When a cell exceeds the maximum number of versions, the extra records are dropped
during the next major compaction.
Instead of deleting an entire cell, you can operate on a specific version or versions
within that cell. The deleteColumns() method (with the s) described previously operates
on all KeyValues with a version less than the provided version. If no version is provided,
the default of now is used. The deleteColumn() method (without the s) deletes
a specific version of a cell. Be careful which method you call; they have identical calling
signatures and only subtly different semantics.















 366
366











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









