







1.redis的基本操作
redis支持的存储主要有5种:string(字符串)、list(链表)、set(集合)、zset(sorted set --有序集合)和hash(哈希类型)。
字符串类型是Redis中最为基础的数据存储类型,它在Redis中是二进制安全的,这便意味着该类型可以接受任何格式的数据,如JPEG图像数据或Json对象描述信息等。在Redis中字符串类型的Value最多可以容纳的数据长度是512M。
1)字符串的操作
命令:set key value
设定该Key持有指定的字符串Value,如果该Key已经存在,则覆盖其原有值。返回值:“OK”。
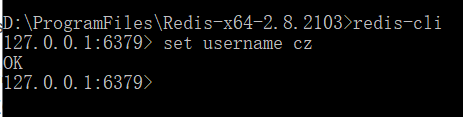
命令:get key
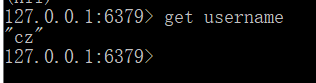
2)list数据类型的操作
在Redis中,List类型是按照插入顺序排序的字符串链表。和数据结构中的普通链表一样,我们可以在其头部(left)和尾部(right)添加新的元素。在插入时,如果该键并不存在,Redis将为该键创建一个新的链表。与此相反,如果链表中所有的元素均被移除,那么该键也将会被从数据库中删除。List中可以包含的最大元素数量是4294967295。
从元素插入和删除的效率视角来看,如果我们是在链表的两头插入或删除元素,这将会是非常高效的操作,即使链表中已经存储了百万条记录,该操作也可以在常量时间内完成。然而需要说明的是,如果元素插入或删除操作是作用于链表中间,那将会是非常低效的。
命令:LPUSH key value [value ...]
在指定Key所关联的List Value的头部插入参数中给出的所有Values。如果该Key不存在,该命令将在插入之前创建一个与该Key关联的空链表,之后再将数据从链表的头部插入。如果该键的Value不是链表类型,该命令将返回相关的错误信息。
返回值:插入后链表中元素的数量。
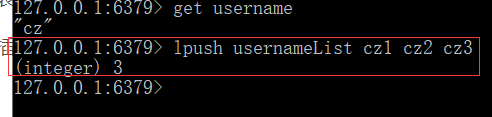
命令:LPUSHX key value
仅有当参数中指定的Key存在时,该命令才会在其所关联的List Value的头部插入参数中给出的Value,否则将不会有任何操作发生。
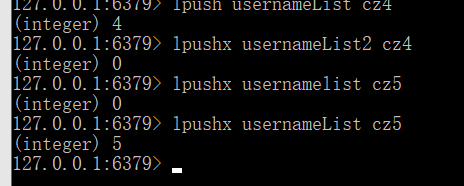
可以看到使用lpushx时如果key不存在将不会创建。
命令:LRANGE key start stop
该命令的参数start和end都是0-based。即0表示链表头部(leftmost)的第一个元素。其中start的值也可以为负值,-1将表示链表中的最后一个元素,即尾部元素,-2表示倒数第二个并以此类推。该命令在获取元素时,start和end位置上的元素也会被取出。如果start的值大于链表中元素的数量,空链表将会被返回。如果end的值大于元素的数量,该命令则获取从start(包括start)开始,链表中剩余的所有元素。

命令:LSET key index value
设定链表中指定位置的值为新值,其中0表示第一个元素,即头部元素,-1表示尾部元素。如果索引值Index超出了链表中元素的数量范围,该命令将返回相关的错误信息。

命令:LINDEX key index
该命令将返回链表中指定位置(index)的元素,index是0-based,表示头部元素,如果index为-1,表示尾部元素。如果与该Key关联的不是链表,该命令将返回相关的错误信息。
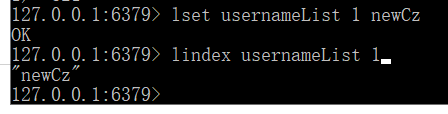
如上查看修改的新值。
3)hash数据类型的操作
Hashes类型可以看成具有String Key和String Value的map容器。所以该类型非常适合于存储值对象的信息。如用户信息:Username、Password和Age等。每一个Hash可以存储4294967295个键值对。
命令:HSET key field value
为指定的Key设定Field/Value对,如果Key不存在,该命令将创建新Key以参数中的Field/Value对,如果参数中的Field在该Key中已经存在,则用新值覆盖其原有值。
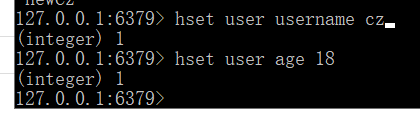
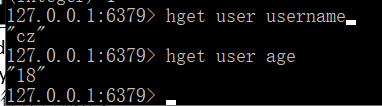
命令:HGET key field
返回指定Key中指定Field的关联值。
命令:HDEL key field [field ...]
从指定Key的Hashes Value中删除参数中指定的多个字段,如果不存在的字段将被忽略。

3)set数据类型操作
在Redis中,我们可以将Set类型看作为没有排序的字符串集合。Set可包含的最大元素数量是4294967295。
Set类型在功能上还存在着一个非常重要的特性,即在服务器端完成多个Sets之间的聚合计算操作,如unions(并集)、intersections(交集)和differences(差集)。由于这些操作均在服务端完成,因此效率极高,而且也节省了大量的网络IO开销。
命令:SADD key member [member ...]
如果在插入的过程用,参数中有的成员在Set中已经存在,该成员将被忽略,而其它成员仍将会被正常插入。如果执行该命令之前,该Key并不存在,该命令将会创建一个新的Set,此后再将参数中的成员陆续插入。
返回值:本次操作实际插入的成员数量。

命令:SCARD key
获取Set中成员的数量。返回值:返回Set中成员的数量,如果该Key并不存在,返回0。

命令:SISMEMBER key member
判断参数中指定成员是否已经存在于与Key相关联的Set集合中。 返回值:1表示已经存在,0表示不存在,或该Key本身并不存在。

其他命令可以参考官方文档。
2.redis和springboot整合
本案例整合方式采用的是springboot2.xx
1)导入依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>2)在application.yml 配置redis
spring:
redis:
database: 0 # Redis服务器数据库
host: 127.0.0.1 # Redis服务器地址
port: 6379 # Redis服务器连接端口
password: 123456 # Redis服务器连接密码(默认为空)
timeout: 6000ms # 连接超时时间(毫秒)
jedis:
pool:
max-active: 200 # 连接池最大连接数(使用负值表示没有限制)
max-wait: -1 # 连接池最大阻塞等待时间(使用负值表示没有限制)
max-idle: 10 # 连接池中的最大空闲连接
min-idle: 0 # 连接池中的最小空闲连接3)写一个redis配置类
springboot自带一个RedisTemplate的配置类RedisAutoConfiguration,但不好用,具体可以可能源码就知道了。
import org.springframework.cache.annotation.EnableCaching;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.data.redis.connection.RedisConnectionFactory;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.data.redis.serializer.Jackson2JsonRedisSerializer;
import org.springframework.data.redis.serializer.StringRedisSerializer;
import com.fasterxml.jackson.annotation.JsonAutoDetect;
import com.fasterxml.jackson.annotation.PropertyAccessor;
import com.fasterxml.jackson.databind.ObjectMapper;
import com.fasterxml.jackson.databind.jsontype.impl.LaissezFaireSubTypeValidator;
@Configuration
@EnableCaching
public class RedisTemplateConfig {
@Bean("redis")
public RedisTemplate<String, Object> redisTemplate(RedisConnectionFactory factory) {
RedisTemplate<String, Object> template = new RedisTemplate<String, Object>();
template.setConnectionFactory(factory);
Jackson2JsonRedisSerializer jackson2JsonRedisSerializer = new Jackson2JsonRedisSerializer(Object.class);
ObjectMapper om = new ObjectMapper();
om.setVisibility(PropertyAccessor.ALL, JsonAutoDetect.Visibility.ANY);
om.activateDefaultTyping(LaissezFaireSubTypeValidator.instance, ObjectMapper.DefaultTyping.NON_FINAL);
jackson2JsonRedisSerializer.setObjectMapper(om);
StringRedisSerializer stringRedisSerializer = new StringRedisSerializer();
// key采用String的序列化方式
template.setKeySerializer(stringRedisSerializer);
// hash的key也采用String的序列化方式
template.setHashKeySerializer(stringRedisSerializer);
// value序列化方式采用jackson
template.setValueSerializer(stringRedisSerializer);
// hash的value序列化方式采用jackson
template.setHashValueSerializer(jackson2JsonRedisSerializer);
template.afterPropertiesSet();
return template;
}
}
4)测试
@Autowired
@Qualifier("redis")
private RedisTemplate<String, Object> redisTemplate;
public void test() throws Exception {
String username = (String) redisTemplate.opsForValue().get("username");
System.out.println(username);
redisTemplate.opsForHash().put("user", "age", 18);
String age = redisTemplate.opsForHash().get("user", "age").toString();
System.out.println(age);
}结果如下:

3.缓存避坑
1)缓存穿透
缓存穿透是指缓存和数据库中都没有的数据,而用户不断发起请求,如发起为id为“-1”的数据或id为特别大不存在的数据。这时的用户很可能是攻击者,攻击会导致数据库压力过大。
解决方案:
- 接口层增加校验,如用户鉴权校验,id做基础校验,id<=0的直接拦截;
- 从缓存取不到的数据,在数据库中也没有取到,这时也可以将key-value对写为key-null,缓存有效时间可以设置短点,如30秒(设置太长会导致正常情况也没法使用)。这样可以防止攻击用户反复用同一个id暴力攻击。
2)缓存击穿
缓存击穿是指缓存中没有但数据库中有的数据(一般是缓存时间到期),这时由于并发用户特别多,同时读缓存没读到数据,又同时去数据库去取数据,引起数据库压力瞬间增大,造成过大压力。
解决方案:
- 设置热点数据永远不过期。
- 加互斥锁
3)缓存雪崩
缓存雪崩是指缓存中数据大批量到过期时间,而查询数据量巨大,引起数据库压力过大甚至down机。和缓存击穿不同的是, 缓存击穿指并发查同一条数据,缓存雪崩是不同数据都过期了,很多数据都查不到从而查数据库。
解决方案:
- 缓存数据的过期时间设置随机,防止同一时间大量数据过期现象发生。
- 如果缓存数据库是分布式部署,将热点数据均匀分布在不同搞得缓存数据库中。
- 设置热点数据永远不过期。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









