







 本文介绍了Hadoop Streaming的使用,包括一个完整的shell执行脚本,展示了如何使用Combiner优化MapReduce任务,以及数据分割的方法。通过设置Combiner减少网络传输,提高程序效率,并讨论了数据倾斜问题。同时,讲解了如何通过-D选项定制Map和Reduce的输出字段分隔符,实现二次排序。
本文介绍了Hadoop Streaming的使用,包括一个完整的shell执行脚本,展示了如何使用Combiner优化MapReduce任务,以及数据分割的方法。通过设置Combiner减少网络传输,提高程序效率,并讨论了数据倾斜问题。同时,讲解了如何通过-D选项定制Map和Reduce的输出字段分隔符,实现二次排序。
1,前言 --- 先上干货:hadoop.streaming 的一个完整的shell脚本;hadoop streaming (shell执行脚本实例 & combiner初探 & 数据分割)
### 2--- tasks
22 HADOOP=/usr/bin/hadoop
23
24 local_file="./wc.data"
25 #input="yapeng/WC/input/*.txt"
26 input="yapeng/WC/input2"
27 output="yapeng/WC/output"
28
29 $HADOOP fs -rm -r -skipTrash $input
30 $HADOOP fs -put $local_file $input
31 $HADOOP fs -rm -r -skipTrash $output
32 #-inputformat com.hadoop.mapred.DeprecatedLzoTextInputFormat \
33 #-D stream.map.input.ignoreKey='true' \
34 $HADOOP org.apache.hadoop.streaming.HadoopStreaming \
35 -D mapred.job.name="WC_TEST" \
36 -D mapred.reduce.tasks=4 \
37 -D mapred.output.compress=true \
38 -D mapred.output.compression.type=BLOCK \
39 -D mapred.output.compression.codec=com.hadoop.compression.lzo.LzopCodec \
40 -input $input \
41 -output $output \
42 -file ./interval.json \
43 -file ./2016112917_badmid.data \
44 -mapper "python wc_mapper.py ./2016112917_badmid.data" -file ./wc_mapper.py \
45 -combiner "python wc_reducer.py" -file ./wc_reducer.py \
46 -reducer "python wc_reducer.py" -file ./wc_reducer.py
47
48 exit -1
49 ### 3--- judge
50 $HADOOP fs -test -e "$OUTPUT/_SUCCESS"
51 if [ $? -eq 0 ]; then
52 echo "Succ!!!"
53 else
54 echo "hadoop task fail!"
55 fi
56
57 ### 4--- cp from remote to local
58 $HADOOP fs -cat "$OUTPUT/part-*" |lzop -dc > wap_wuid_keywordtag.${DAY}
2 -- combiner初探
2.1 为什么需要进行Map规约操作
众所周知,Hadoop框架使用Mapper将数据处理成一个个的<key,value>键值对,在网络节点间对其进行整理(shuffle),然后使用Reducer处理数据并进行最终输出。
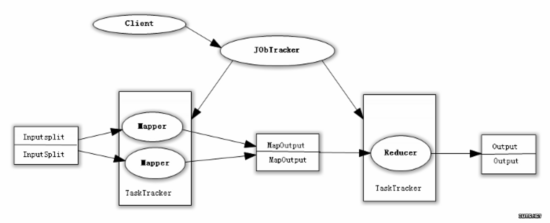
在上述过程中,我们看到至少两个 性能瓶颈 :
(1)如果我们有10亿个数据,Mapper会生成10亿个键值对在网络间进行传输,但如果我们只是对数据求最大值,那么很明显的Mapper只需要输出它所知道的最大值即可。这样做不仅可以减轻网络压力,同样也可以大幅度提高程序效率。
总结: 网络带宽严重被占降低程序效率;
(2)假设使用美国专利数据集中的国家一项来阐述 数据倾斜 这 个定义,这样的数据远远不是一致性的或者说平衡分布的,由于大多数专利的国家都属于美国,这样不仅Mapper中的键值对、中间阶段(shuffle)的 键值对等,大多数的键值对最终会聚集于一个单一的Reducer之上,压倒这个Reducer,从而大大降低程序的性能。
总结: 单一节点承载过重降低程序性能;那么,有木有一种方案能够解决这两个问题呢?
在MapReduce编程模型中,在Mapper和Reducer之间有一个非常重要的组件,它解决了上述的性能瓶颈问题,它就是 Combiner 。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2346
2346

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









