







转载 :http://blog.csdn.net/duan19920101/article/details/51579136
在学习rocksdb 时,组件memtable 存储数据的主要数据结构是skiplist,不是太了解,学习后感觉设计很精巧。
1.什么是SkipList跳跃表
跳表是平衡树的一种替代的数据结构,但是和红黑树不相同的是,跳表对于树的平衡的实现是基于一种随机化的算法的,这样也就是说跳表的插入和删除的工作是比较简单的。
2.核心思想
先从链表开始,如果是一个简单的链表,那么我们知道在链表中查找一个元素I的话,需要将整个链表遍历一次。

如果是说链表是排序的,并且节点中还存储了指向前面第二个节点的指针的话,那么在查找一个节点时,仅仅需要遍历N/2个节点即可。

这基本上就是跳表的核心思想,其实也是一种通过“空间来换取时间”的一个算法,通过在每个节点中增加了向前的指针,从而提升查找的效率。

3.相关操作
1、重要数据结构定义
2、初始化表
3、查找
4、插入
5、删除
6、释放表
7、性能比较
1.结构定义:
//定义key和value的类型
typedef int KeyType;
typedef int ValueType;
//定义结点
typedef struct nodeStructure* Node;
struct nodeStructure{
KeyType key;
ValueType value;
Node forward[1];
};
//定义跳跃表
typedef struct listStructure* List;
struct listStructure{
int level;
Node header;
}; 2.初始化跳表
void SkipList::NewList(){
//设置NIL结点
NewNodeWithLevel(0, NIL_);
NIL_->key = 0x7fffffff;
//设置链表List
list_ = (List)malloc(sizeof(listStructure));
list_->level = 0;
//设置头结点
NewNodeWithLevel(MAX_LEVEL,list_->header);
for(int i = 0; i < MAX_LEVEL; ++i){
list_->header->forward[i] = NIL_;
}
//设置链表元素的数目
size_ = 0;
}
void SkipList::NewNodeWithLevel(const int& level,
Node& node){
//新结点空间大小
int total_size = sizeof(nodeStructure) + level*sizeof(Node);
//申请空间
node = (Node)malloc(total_size);
assert(node != NULL);
} 3.查找
我们从头结点开始,首先和9进行判断,此时大于9,然后和21进行判断,小于21,此时这个值肯定在9结点和21结点之间,此时,我们和17进行判断,大于17,然后和21进行判断,小于21,此时肯定在17结点和21结点之间,此时和19进行判断,找到了
bool SkipList::Search(const KeyType& key,
ValueType& value){
Node x = list_->header;
int i;
for(i = list_->level; i >= 0; --i){
while(x->forward[i]->key < key){
x = x->forward[i];
}
}
x = x->forward[0];
if(x->key == key){
value = x->value;
return true;
}else{
return false;
}
} 4.插入
插入包含如下几个操作:1、查找到需要插入的位置 2、申请新的结点 3、调整指针。
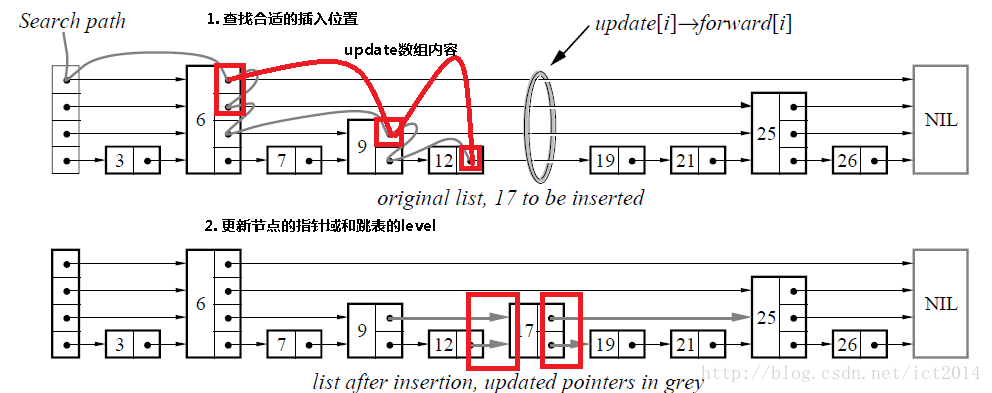
bool SkipList::Insert(const KeyType& key,
const ValueType& value){
Node update[MAX_LEVEL];
int i;
Node x = list_->header;
//寻找key所要插入的位置
//保存大于key的位置信息
for(i = list_->level; i >= 0; --i){
while(x->forward[i]->key < key){
x = x->forward[i];
}
update[i] = x;
}
x = x->forward[0];
//如果key已经存在
if(x->key == key){
x->value = value;
return false;
}else{
//随机生成新结点的层数
int level = RandomLevel();
//为了节省空间,采用比当前最大层数加1的策略
if(level > list_->level){
level = ++list_->level;
update[level] = list_->header;
}
//申请新的结点
Node newNode;
NewNodeWithLevel(level, newNode);
newNode->key = key;
newNode->value = value;
//调整forward指针
for(int i = level; i >= 0; --i){
x = update[i];
newNode->forward[i] = x->forward[i];
x->forward[i] = newNode;
}
//更新元素数目
++size_;
return true;
}
} 5.删除
删除需要3步:1、查找到需要删除的结点 2、删除结点 3、调整指针

bool SkipList::Delete(const KeyType& key,
ValueType& value){
Node update[MAX_LEVEL];
int i;
Node x = list_->header;
//寻找要删除的结点
for(i = list_->level; i >= 0; --i){
while(x->forward[i]->key < key){
x = x->forward[i];
}
update[i] = x;
}
x = x->forward[0];
//结点不存在
if(x->key != key){
return false;
}else{
value = x->value;
//调整指针
for(i = 0; i <= list_->level; ++i){
if(update[i]->forward[i] != x)
break;
update[i]->forward[i] = x->forward[i];
}
//删除结点
free(x);
//更新level的值,有可能会变化,造成空间的浪费
while(list_->level > 0
&& list_->header->forward[list_->level] == NIL_){
--list_->level;
}
//更新链表元素数目
--size_;
return true;
}
}
6.释放表

void SkipList::FreeList(){
Node p = list_->header;
Node q;
while(p != NIL_){
q = p->forward[0];
free(p);
p = q;
}
free(p);
free(list_);
} 7.性能比较
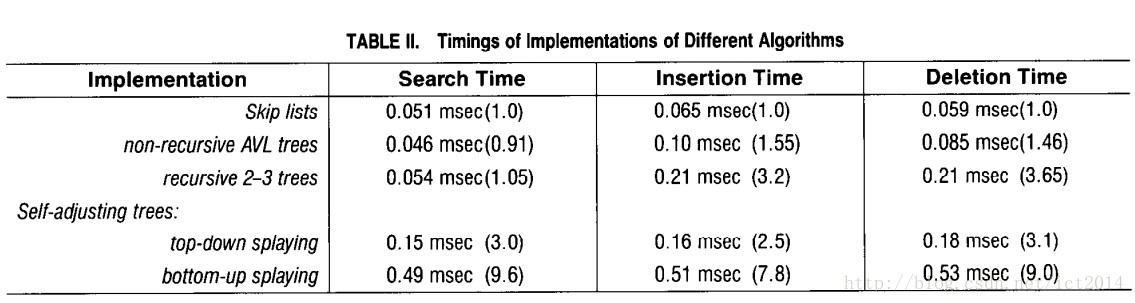
通过“空间来换取时间”的一个算法,通过在每个节点中增加了向前的指针,从而提升查找的效率。















 547
547











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









