







leveldb头文件结构
include
└── leveldb
├── c.h => c binding
├── cache.h => cache接口
├── comparator.h => 比较器接口
├── db.h => DB接口
├── env.h => 为跨平台准备的env接口
├── filter_policy.h => fliter策略,用于缓存,请看到文档及相应实现
├── iterator.h => 迭代器,用于遍历数据库中存储的数据
├── options.h => 包含控制数据库的Options,控制读的WriteOptions,ReadOptions
├── slice.h => Slice的接口
├── status.h => leveldb中大多接口返回的Status接口
├── table.h => immutable接口
├── table_builder.h => 用于创建table的构建器接口
└── write_batch.h => 使多个写操作成为原子写的接口1.options.h
主要有 Option: Options, ReadOptions, WriteOptions. 可以通过配置相关选项,进行性能的优化。
1.1 option
const Comparator* comparator; 默认字典排序
bool create_if_missing;默认false,如果为true,在数据库丢失的时候,会自动创建。
bool error_if_exists;默认false;true:代表如果数据库存在,会报错误。
bool paranoid_checks;默认false.true:代表检查比较严格,有任何歧义,都会上报错误。
Env* env; 平台兼容性相关, // Default: Env::Default()
Logger* info_log; // Default: NULL
size_t write_buffer_size; // Default: 4MB ,增大该值,可以提升效率,但是会导致在下次数据库打开 ,恢复的时候占用太长时间。
int max_open_files; // Default: 1000 数据库 可以被打开的最大次数,当数据库预计操作的文件数据较大时,可以提高该值
Cache* block_cache; //默认为null 时,leveldb 会创建 一个8M 的内在缓存。
size_t block_size;每一个block 的大小,可以动态改变,实际的数据可能要小些。默认为4k.
int block_restart_interval; // Default: 16 ,差分编码时key 的数目,可以动态改变,建议不修改。
size_t max_file_size; // Default: 2MB, 在 leveldb 写入的最大数量,建议不修改,当你的文件系统在处理大文件效率较高,或者 需要操作一个较大数据库时,可以适当增加。
CompressionType compression; //默认kSnappyCompression,压缩算法配置。
bool reuse_logs;//默认false,true:代表,当数据库打开时,把相关的信息增加到mainfest 和 logfile 中。
const FilterPolicy* filter_policy; //bloom-filter 在levledb 读数据库时,极大 的提升效率。1.2 ReadOptions
ReadOptions()
: verify_checksums(false),//检验
fill_cache(true),
//当用户执行Get操作时,将会把获取到的数据放入cache中.如果数据库中的数据较大,放置在cache中 // 并不合适,就可以设置fill_cache为false,关闭这一特性.
snapshot(NULL) {
}1.3 WriteOptions
WriteOptions()
: sync(false) { //是否要进行同步写,默认false .
}2.c.h
leveldb 中大部分代码,都通过c 语言实现了,常见的增删改查。以及一些不常用的函数接口。
3.cache.h
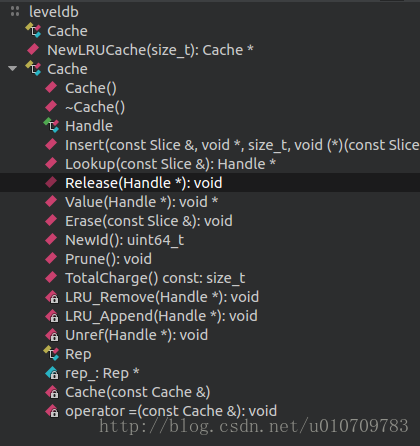
为了提高性能,cache是不可避免的.cache.h中提供了Cache接口.LevelDB提供了基于LRU(least recent used)策略的Cache.如果需要提供自定义的cache方法,可以继承Cache类,并实现其中的纯虚函数.














 320
320











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









