







文章目录
前言
参考:https://blog.csdn.net/u013870094/article/details/78880498
mysql是我们经常使用的关系型数据库,我们常用的业务中也会涉及到分页的场景,limit使我们经常使用的函数,了解其原理也有助于我们工作当中的sql优化。
1.只有limit:
当sql覆盖索引的时候会走索引:
例如:
EXPLAIN SELECT id FROM `wx_login` LIMIT 100,2
索引不覆盖的时候全表扫描:
EXPLAIN SELECT * FROM `wx_login` LIMIT 100,2
2.limit和order by:
如果两者一起使用,找到最初的row_count之后就完成这条语句,而不是对整个结果集去排序如果使用到索引字段排序排序的话,会非常快的完成。
解决排序结果集不固定的问题:
把查询列都进行排序:
SELECT id,openid,nickname FROM `wx_pay` ORDER BY openid,id LIMIT 5
替代:
SELECT id,openid,nickname FROM `wx_pay` ORDER BY openid LIMIT 5
3.limit和distinct配合使用:
当两者一起使用的时候,也是类似于order by和limit,当查询到结果集就会停止检索。
4.limit和group by配合使用:
group by 进行汇总的时候,如果有limit,那么当查询到row_count后不会计算额外的group by的值,是一个比较不错的可以利用的优化点。
5.limit 0:
当我们想要监测sql的合法性的时候,limit 0会非常快的返回一个空结果, 当然select 1也是可以的
6.sort_buffer_size的利用:
sort_buffer_size是一个connection级参数,在每个connection第一次需要使用这个buffer的时候,一次性分配设置的内存。并不是越大越好,由于是connection级的参数,过大的设置+高并发可能会耗尽系统内存资源。官方文档推荐范围为256KB~2MB,一般设置为2M。
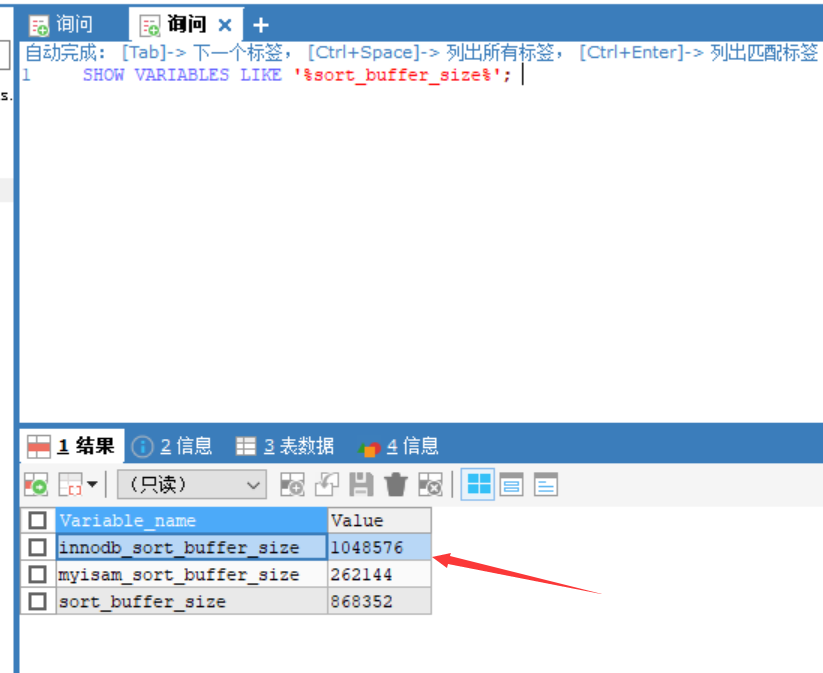
查询命令:
SHOW VARIABLES LIKE '%sort_buffer_size%';
查询结果:
查询语句:
select * from tb limit m,n
排序缓存的参数sort_buffer_size,如果m+n的结果集小于参数,那么服务器会避免一个文件排序操作,使得完全在内存中完成,来提升性能。
| 排序方式 | 原理 | 特点 |
|---|---|---|
| 内存排序+limit | 扫描表,在内存中维护数据队列,如果队列满了,则把末尾的进行移除,知道满足m、n的数据记录 | 扫描表,消耗的是cpu资源 |
| 文件排序+limit | 扫描表,跟上面一样,写入排序文件中满足排序结果集筛选 | 消耗磁盘io的资源 |
考虑n的值大小来平衡性能
结尾
上面就是这篇文章要写的limit的相关的知识点,当然是用limit的时候我们要结合业务去优化,比方说我们可以利用limit的一些条件值筛选调大部分的数据比方说利用id>1000或者时间过滤,这就是其中的原理,如果你有什么其他补充的,欢迎给我进行留言。希望喜欢这篇文章的朋友转载、点赞、赞赏。















 1109
1109











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









