







1.Mean Rating: Calculate the mean rating for each movie, order with the highest rating listed first, and submit the top three (along with the mean scores for the top two).
import pandas as pd
import numpy as np
calculationCSV = pd.read_csv(r'D:\BaiduNetdiskDownload\Recommender Systems 专项课程\1、Introduction to Recommender Systems\03_non-personalized-and-stereotype-based-recommenders\05_module-assessments\HW1-data.csv')
calculationCSV.shape
print(list(calculationCSV.columns))
calculation = calculationCSV.drop(['User','Gender (1 =F, 0=M)'], axis=1)
print(calculation)
#mean rating
mean = calculation.mean()
print(mean.sort_values(axis = 0, ascending=False).head(3))
output:
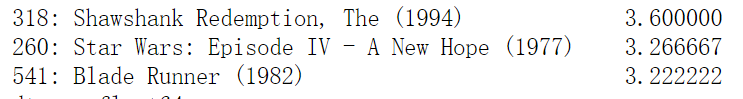
2.Rating Count (popularity): Count the number of ratings for each movie, order with the most number of ratings first, and submit the top three (along with the counts for the top two).
#rating count
count = calculation.count()
print(count.sort_values(axis = 0, ascending=False).head(3))
output:
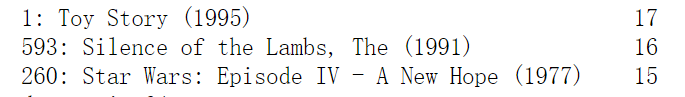
3.% of ratings 4+ (liking): Calculate the percentage of ratings for each movie that are 4 or higher. Order with the highest percentage first, and submit the top three (along with the percentage for the top two). Notice that the three different measures of “best” reflect different priorities and give different results; this should help you see why you need to be thoughtful about what metrics you use.
#% of ratings 4+
def ifgreaterthan4(x):
if (x >= 4):
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 133
133











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









