







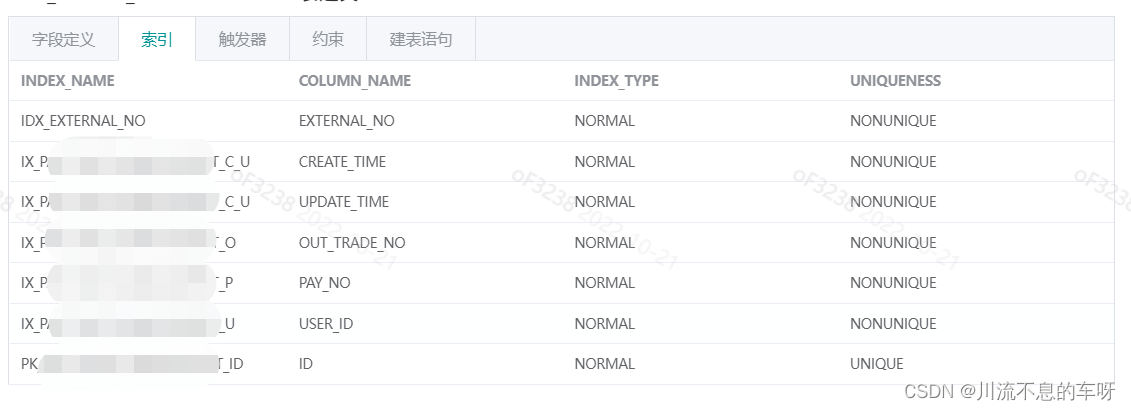
一:表数据量较大时
1:首先看一个表的索引建立如上图,CREATE_TIME和UPDATE_TIME 是复合索引,USER_ID独立索引
目前此表的数据量: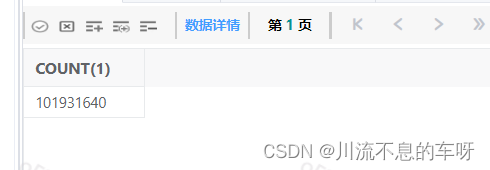
常用的sql,默认查询时间范围1个月的店铺的数据(出发点是为了减少慢查询)。但随着表数量的增加,返回数据越来越慢,已经达到3s以上,甚至更多
1:查看执行计划,发现走的是复合索引,然后进行了回表查询
拆解上面sql:
1:只通过时间范围查询,返回数据量
2:时间范围加店铺编号查询:返回数据量: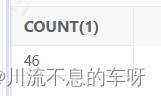
发现满足条件的数据量很少,按强制走USER_ID字段的单独索引走,速度明显就快很多,主要是filter的量变少了
Tips:
当对一个列创建索引之后,索引会包含该列的键值以及键值对应行所在的rowid。通过索引中记录的rowid访问表中的数据就叫回表。回表一般是单块读,回表次数太多会严重影响SQL性能
执行计划中框出来的部分(TABLE ACCESS BY INDEX ROWID)就是回表。索引返回多少行数据,回表就要回多少次。每次回表都是单块读(因为一个rowid对应一个数据块)该SQL返回了2791415行数据,那么回表一共就需要2791415次(回表的过程中进行filter条件过滤)。所以要尽量减少回表的量
select /*+INDEX(表名,表索引名)*/ * from 表名 where user_id='店铺编号' and CREATE_TIME BETWEEN TO_DATE('2022-10-01 00:00:00','yyyy-mm-dd hh24:mi:ss') and TO_DATE('2022-10-30 23:59:59','yyyy-mm-dd hh24:mi:ss')


通过以上强制执行索引发现查询从2.69秒变成了380毫秒
但是这种强制查询也只符合当前店铺编号的数据量比较少的情况下适合使用,当店铺编号数量达到一定基础后,又会变的很慢。所以单独强制某个索引也不合适
二:表数据量较少时
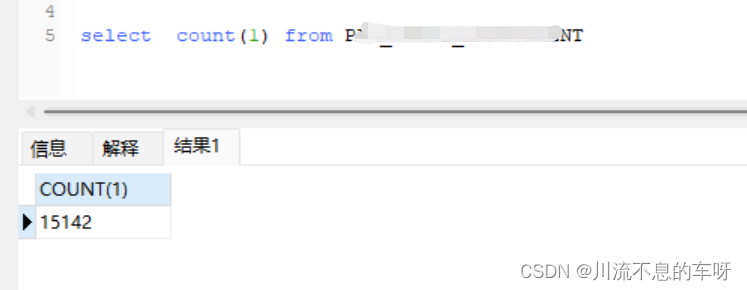
查看执行计划走的还是复合索引
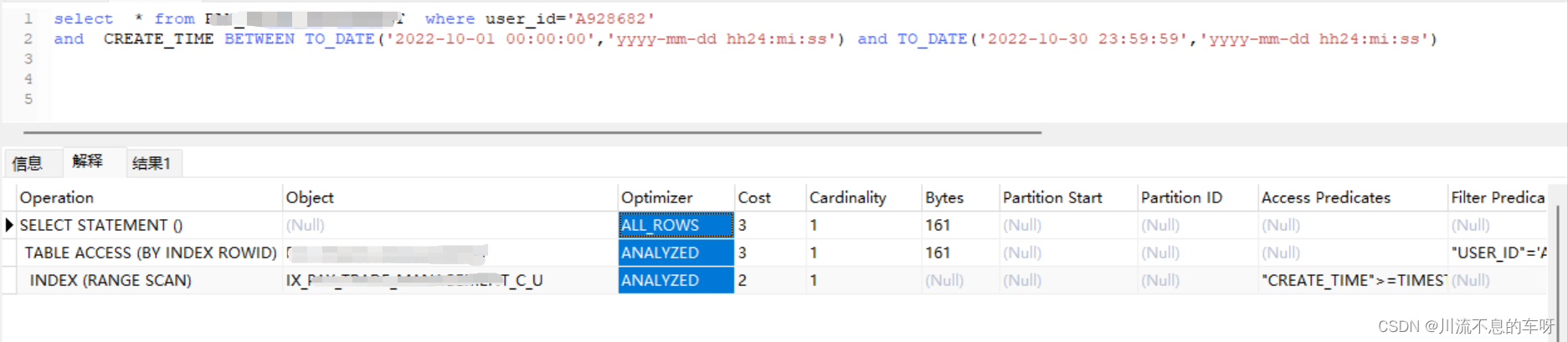
Tips:当查询条件包含复合索引+单独独立索引时,更倾向走复合索引
三:查询无店铺信息数据时
1:查看执行计划,数据量小时发现走的是独立索引
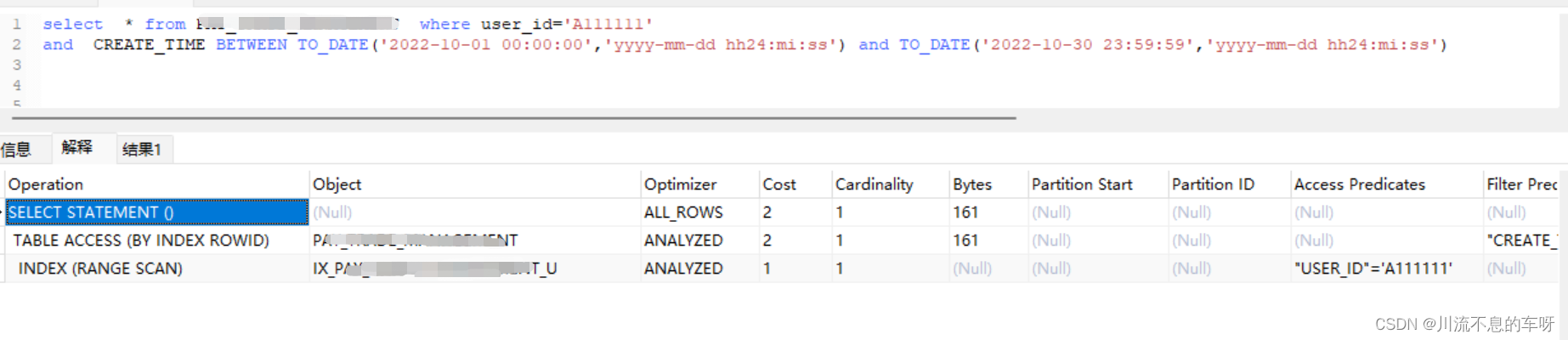
2:数量大时发现还是走的复合索引
Tips:
一般页面查询条件比较多时,有可能会有复合索引和单独索引一起存在的情况。建立索引时就考虑好后面数据量大小的问题,来决定哪些字段可以建立复合索引,减少回表,物理I/O次数
四:最终解决方法
又把上文提到的user_id 和create_time 建了联合索引,后续查询大约400多毫秒
















 7857
7857











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









