







Java集合框架图
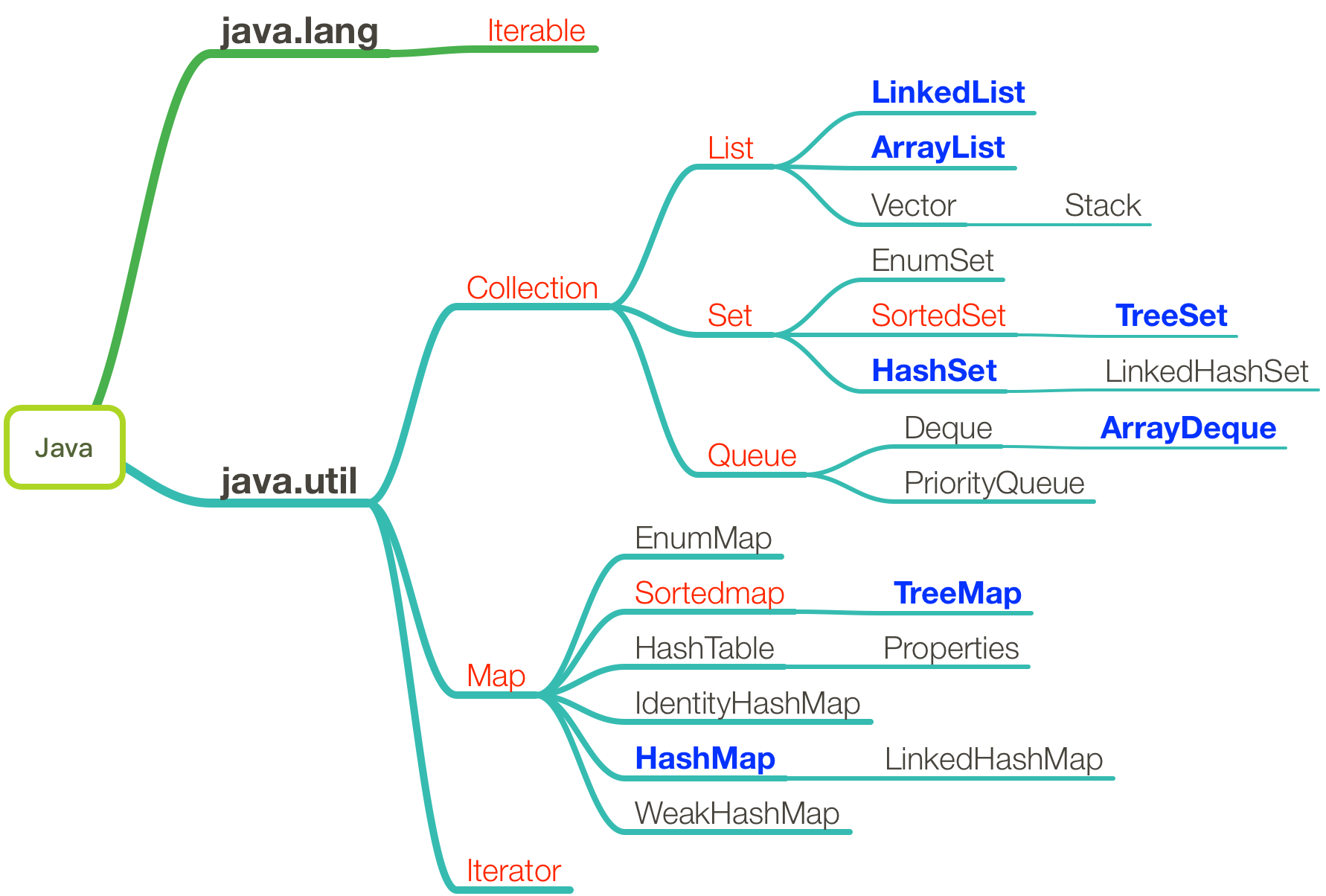
在集合框架图中,红色标记的为接口,蓝色标记的为重要的实现类
在Java集合中大致可分为四个体系:
- Set,代表无序、不可重复的集合
- List,代表有序、重复的集合
- Map,代表具有映射关系的集合
- Queue,代表队列集合
Iterator接口
Iterable是Collection接口的父接口,因此Collection集合可以直接调用Iterable中的方法。
Iterator主要用于迭访问Collection集合中的元素,Iterator对象也被称为迭代器
下面为Iterable接口
public interface Iterable<T> {
Iterator<T> iterator();
default void forEach(Consumer<? super T> action) {
Objects.requireNonNull(action);
for (T t : this) {
action.accept(t);
}
}
default Spliterator<T> spliterator() {
return Spliterators.spliteratorUnknownSize(iterator(), 0);
}
}Iterable接口中:
第一个方法就是返回T类型元素的一个迭代器。
下面的两个默认方法是Java 8新增的功能
- forEach方法所需的参数类型是一个函数式接口,可用Lambda表达式,用于对每个元素执行给定的动作指导
public class CollectionEach { public static void main(String[] args) { // 创建一个集合 Collection c = new HashSet(); c.add("Map"); c.add("Set"); c.add("Queue"); c.add("List"); // 调用forEach()方法遍历集合 c.forEach(obj -> System.out.println("迭代集合元素:" + obj)); } }- spliterator方法实现从iterable的Iterator中创建一个早期绑定的spliterator
Iterator接口隐藏了各种Collection实现类的底层细节,向应用程序提供了遍历Collection集合元素的统一编程接口,下面是Iterator接口的代码
public interface Iterator<E> {
boolean hasNext();
E next();
default void remove() {
throw new UnsupportedOperationException("remove");
}
default void forEachRemaining(Consumer<? super E> action) {
Objects.requireNonNull(action);
while (hasNext())
action.accept(next());
}
}如上面代码所示,Iterator定义了四个方法:
- hasNext方法,如果被迭代的集合元素还没有被遍历完,则返回true
- next方法,返回集合里的下一个元素
- remove方法,删除集合里上一次next方法返回的元素
- forEachRemaining方法,Java 8 新增,可使用Lambda表达式遍历元素
注意:当使用Iterator迭代访问Collection集合元素时,Collection集合里的元素不能被改变,只有通过Iterator的remove()方法删除上一次next()方法返回的集合元素才可以;否则将会引发异常。
Collection接口
Collection接口是Set、List和Queue接口的父接口,下面是Collection接口的代码:
public interface Collection<E> extends Iterable<E> {
int size();//返回集合元素个数
boolean isEmpty();//返回集合是否为空
boolean contains(Object o);//返回集合是否包含o
Iterator<E> iterator();//返回对应的迭代器
Object[] toArray();//把集合转换成Object数组
<T> T[] toArray(T[] a);//把集合转换成对应的数组
boolean add(E e);//添加元素
boolean remove(Object o);//删除元素
boolean containsAll(Collection<?> c);//是否包含c里面的所有元素
boolean addAll(Collection<? extends E> c);//将c中元素全部添加到指定集合
boolean removeAll(Collection<?> c);//删除c中全部的元素
/*Java 8新增的方法,该方法将会批量删除符合filter条件的所有元素,该方法需要Predicate对象作为参数,同样也是函数式接口,可用Lambda表达式*/
default boolean removeIf(Predicate<? super E> filter) {
Objects.requireNonNull(filter);
boolean removed = false;
final Iterator<E> each = iterator();
while (each.hasNext()) {
if (filter.test(each.next())) {
each.remove();
removed = true;
}
}
return removed;
}
boolean retainAll(Collection<?> c);//从集合中删除集合c里不包含的元素
void clear();//清空
int hashCode();//返回hashCode值
default Spliterator<E> spliterator() {
return Spliterators.spliterator(this, 0);
}
/*返回集合对应的流,可通过流式API操作集合元素*/
default Stream<E> stream() {
return StreamSupport.stream(spliterator(), false);
}
default Stream<E> parallelStream() {
return StreamSupport.stream(spliterator(), true);
}
}下面程序示范使用Predicate来过滤集合。
public class PredicateTest
{
public static void main(String[] args)
{
Collection c = new HashSet();
c.add(new String("123456789101112"));
c.add(new String("12345678"));
c.add(new String("123456789"));
c.add(new String("123456"));
c.add(new String("112233445566"));
// 使用Lambda表达式(目标类型是Predicate)过滤集合
books.removeIf(ele -> ((String)ele).length() < 10);
System.out.println(books);
}
}使用Predicate可以充分简化集合的运算,假设有books集合,如果程序有如下三个统计需求:
- 统计书名中出现“数据”字符串的图书数量
- 统计书名中出现“Java”字符串的图书数量
- 统计书名长度大于10的图书数量
import java.util.*;
import java.util.function.*;
public class PredicateTest2
{
public static void main(String[] args)
{
// 创建books集合、为books集合添加元素的代码与前一个程序相同。
Collection books = new HashSet();
books.add(new String("轻量级Java EE企业应用实战"));
books.add(new String("疯狂Java讲义"));
books.add(new String("深入Java虚拟机"));
books.add(new String("数据挖掘"));
books.add(new String("数据结构与算法分析"));
// 统计书名包含“疯狂”子串的图书数量
System.out.println(calAll(books , ele->((String)ele).contains("数据")));
// 统计书名包含“Java”子串的图书数量
System.out.println(calAll(books , ele->((String)ele).contains("Java")));
// 统计书名字符串长度大于10的图书数量
System.out.println(calAll(books , ele->((String)ele).length() > 10));
}
public static int calAll(Collection books , Predicate p)
{
int total = 0;
for (Object obj : books)
{
// 使用Predicate的test()方法判断该对象是否满足Predicate指定的条件
if (p.test(obj))
{
total ++;
}
}
return total;
}
}下面的例子使用Stream来改写上一个例子:
import java.util.*;
import java.util.function.*;
public class CollectionStream
{
public static void main(String[] args)
{
// 创建books集合、为books集合添加元素的代码与8.2.5小节的程序相同。
Collection books = new HashSet();
books.add(new String("轻量级Java EE企业应用实战"));
books.add(new String("疯狂Java讲义"));
books.add(new String("深入Java虚拟机"));
books.add(new String("数据挖掘"));
books.add(new String("数据结构与算法分析"));
// 统计书名包含“疯狂”子串的图书数量
System.out.println(books.stream()
.filter(ele->((String)ele).contains("数据"))
.count()); // 输出4
// 统计书名包含“Java”子串的图书数量
System.out.println(books.stream()
.filter(ele->((String)ele).contains("Java") )
.count()); // 输出2
// 统计书名字符串长度大于10的图书数量
System.out.println(books.stream()
.filter(ele->((String)ele).length() > 10)
.count()); // 输出2
// 先调用Collection对象的stream()方法将集合转换为Stream,
// 再调用Stream的mapToInt()方法获取原有的Stream对应的IntStream
books.stream().mapToInt(ele -> ((String)ele).length())
// 调用forEach()方法遍历IntStream中每个元素
.forEach(System.out::println);// 输出8 11 16 7 8
}
}Set集合
1.HashSet
HashSet具有以下特点:
- 不能保证元素的排列顺序,顺序可能与添加顺序不同,顺序也可能发生变化
- HashSet不是同步的,如果多个线程同时访问一个HashSet,假设有两个或两个以上线程同时修改了HashSet集合时,必须通过代码保证其同步
- 集合元素值可以是null
hashCode()方法可以获得该对象的hashCode值,通过这个值决定该对象在HashCode中的存储位置。
equals()方法判断两个对象是否相等。
当把一个对象放入HashSet中时,如果需要重写该对象对应类的equals()方法,则也应该重写其hashCode()方法,规则是两个对象通过equals()方法比较返回true,这两个对象的hashCode值也相等。
重写hashCode方法的基本规则:
- 在程序运行过程中,同一个对象多次调用hashCode()返回相同的值
- 当两个对象通过equals()方法返回true,这两个对象的hashCode值也应该相等
- 对象中用作equals()方法比较标准的实例变量,都应该用于计算hashCode值
下面程序分别提供了三个类A、B和C,它们分别重写了equals()、和hashCode()
class A
{
public boolean equals(Object obj)
{
return true;
}
}
// 类B的hashCode()方法总是返回1,但没有重写其equals()方法
class B
{
public int hashCode()
{
return 1;
}
}
// 类C的hashCode()方法总是返回2,且重写其equals()方法总是返回true
class C
{
public int hashCode()
{
return 2;
}
public boolean equals(Object obj)
{
return true;
}
}
public class HashSetTest
{
public static void main(String[] args)
{
HashSet books = new HashSet();
// 分别向books集合中添加两个A对象,两个B对象,两个C对象
books.add(new A());
books.add(new A());
books.add(new B());
books.add(new B());
books.add(new C());
books.add(new C());
System.out.println(books);
}
}输出结果为
[B@1,B@1,C@2,A@5483cd,A@9931f5]2.LinkedHashSet
LinkedHashSet同时使用链表维护元素的次序,这样使得元素看起来是以插入的顺序保存的
LinkedHashSet需要维护元素的插入顺序,因此性能略低于HashSet的性能,但在迭代器访问Set里面的全部元素时将有很好的性能,因为它以链表来维护内部顺序
输出LinkedHashSet集合的元素时,元素顺序总与添加顺序一致,并且依然不允许集合元素重复,如下面代码所示:
import java.util.*;
public class LinkedHashSetTest
{
public static void main(String[] args)
{
LinkedHashSet books = new LinkedHashSet();
books.add("疯狂Java讲义");
books.add("数据结构与算法分析");
System.out.println(books);
// 删除 疯狂Java讲义
books.remove("疯狂Java讲义");
// 重新添加 疯狂Java讲义
books.add("疯狂Java讲义");
System.out.println(books);
}
}[疯狂Java讲义,数据结构与算法分析]
[数据结构与算法分析,疯狂Java讲义]3.TreeSet
TreeSet可以确保集合元素处于排序状态。与HashSet集合相比,TreeSet还提供了几个额外的方法
- Comparator comparator()
- Object first()
- Object last()
- Object lower(Object e)
- Object higher(Object e)
- SortedSet subSet(Object fromElement,Object toElement)
- SortedSet headSet(Object toElement)
- SortedSet tailSet(Object fromElement)
因为TreeSet是有序的,所以增加了访问第一个、前一个、后一个、最后一个元素的方法,并提供了三个从TreeSet中截取子TreeSet的方法
1.自然排序
TreeSet会调用集合元素的compareTo(Object obj)方法来比较元素之间的大小关系,然后将集合元素按升序排列,这种方式就是自然排序
如果希望TreeSet能正常工作,TreeSet只能添加同一种类型的元素
如果两个对象compareTo(Object obj)方法比较相等,即返回0,则新对象将无法添加到TreeSet集合中
import java.util.*;
class Z implements Comparable
{
int age;
public Z(int age)
{
this.age = age;
}
// 重写equals()方法,总是返回true
public boolean equals(Object obj)
{
return true;
}
// 重写了compareTo(Object obj)方法,总是返回1
public int compareTo(Object obj)
{
return 1;
}
}
public class TreeSetTest2
{
public static void main(String[] args)
{
TreeSet set = new TreeSet();
Z z1 = new Z(6);
set.add(z1);
// 第二次添加同一个对象,输出true,表明添加成功
System.out.println(set.add(z1)); //①
// 下面输出set集合,将看到有两个元素
System.out.println(set);
// 修改set集合的第一个元素的age变量
((Z)(set.first())).age = 9;
// 输出set集合的最后一个元素的age变量,将看到也变成了9
System.out.println(((Z)(set.last())).age);
}
}重写该对象对应类的equals()方法时,若equals()返回true,应保证该方法与compareTo(Object o)方法有一致的结果,即返回0
import java.util.*;
class R implements Comparable
{
int count;
public R(int count)
{
this.count = count;
}
public String toString()
{
return "R[count:" + count + "]";
}
// 重写equals方法,根据count来判断是否相等
public boolean equals(Object obj)
{
if (this == obj)
{
return true;
}
if(obj != null && obj.getClass() == R.class)
{
R r = (R)obj;
return r.count == this.count;
}
return false;
}
// 重写compareTo方法,根据count来比较大小
public int compareTo(Object obj)
{
R r = (R)obj;
return count > r.count ? 1 :
count < r.count ? -1 : 0;
}
}
public class TreeSetTest3
{
public static void main(String[] args)
{
TreeSet ts = new TreeSet();
ts.add(new R(5));
ts.add(new R(-3));
ts.add(new R(9));
ts.add(new R(-2));
// 打印TreeSet集合,集合元素是有序排列的
System.out.println(ts); // ①
// 取出第一个元素
R first = (R)ts.first();
// 对第一个元素的count赋值
first.count = 20;
// 取出最后一个元素
R last = (R)ts.last();
// 对最后一个元素的count赋值,与第二个元素的count相同
last.count = -2;
// 再次输出将看到TreeSet里的元素处于无序状态,且有重复元素
System.out.println(ts); // ②
// 删除实例变量被改变的元素,删除失败
System.out.println(ts.remove(new R(-2))); // ③
System.out.println(ts);
// 删除实例变量没有被改变的元素,删除成功
System.out.println(ts.remove(new R(5))); // ④
System.out.println(ts);
}
}为了让程序更加健壮,推荐不要修改放入HashSet和TreeSet集合中元素的实例变量
2.定制排序
Comparator接口包含了一个int compare(T o1,T o2)方法,用于比较o1等于o2
import java.util.*;
class M
{
int age;
public M(int age)
{
this.age = age;
}
public String toString()
{
return "M[age:" + age + "]";
}
}
public class TreeSetTest4
{
public static void main(String[] args)
{
// 此处Lambda表达式的目标类型是Comparator
TreeSet ts = new TreeSet((o1 , o2) ->
{
M m1 = (M)o1;
M m2 = (M)o2;
// 根据M对象的age属性来决定大小,age越大,M对象反而越小
return m1.age > m2.age ? -1
: m1.age < m2.age ? 1 : 0;
});
ts.add(new M(5));
ts.add(new M(-3));
ts.add(new M(9));
System.out.println(ts);
}
}[M [age:9], M [age:5], M [age:-3]]4.EnumSet
EnumSet是一个专门为枚举类设计的集合类,EnumSet中的所有元素都必须是指定枚举类型的枚举值,该枚举类型在创建时显示或隐式地指定。EnumSet也是有序的,EnumSet以枚举值在Enum类内的定义顺序来决定集合元素的顺序
EnumSet在内部以位向量的形式存储,这种存储形式非常紧凑高效,因此其占用内存很小,而且运行效率很好
EnumSet不允许加入null元素
EnumSet提供了如下的常用方法来创建EnumSet对:
- EnumSet allOf(Class elementType)
- EnumSet complementOf(EnumSet s)
- EnumSet copyOf(Collection s)
- EnumSet copyOf(EnumSet s)
- EnumSet noneOf(Class elementType)
- EnumSet of(E first,E … rest)
- EnumSet range(E from,E to)
enum Season
{
SPRING,SUMMER,FALL,WINTER
}
public class EnumSetTest
{
public static void main(String[] args)
{
// 创建一个EnumSet集合,集合元素就是Season枚举类的全部枚举值
EnumSet es1 = EnumSet.allOf(Season.class);
System.out.println(es1); // 输出[SPRING,SUMMER,FALL,WINTER]
// 创建一个EnumSet空集合,指定其集合元素是Season类的枚举值。
EnumSet es2 = EnumSet.noneOf(Season.class);
System.out.println(es2); // 输出[]
// 手动添加两个元素
es2.add(Season.WINTER);
es2.add(Season.SPRING);
System.out.println(es2); // 输出[SPRING,WINTER]
// 以指定枚举值创建EnumSet集合
EnumSet es3 = EnumSet.of(Season.SUMMER , Season.WINTER);
System.out.println(es3); // 输出[SUMMER,WINTER]
EnumSet es4 = EnumSet.range(Season.SUMMER , Season.WINTER);
System.out.println(es4); // 输出[SUMMER,FALL,WINTER]
// 新创建的EnumSet集合的元素和es4集合的元素有相同类型,
// es5的集合元素 + es4集合元素 = Season枚举类的全部枚举值
EnumSet es5 = EnumSet.complementOf(es4);
System.out.println(es5); // 输出[SPRING]
}
}当复制Collection集合中的所有元素来创建新的EnumSet集合时,要求Collection集合中的所有元素必须是同一个枚举类的枚举值
public class EnumSetTest2
{
public static void main(String[] args)
{
Collection c = new HashSet();
c.clear();
c.add(Season.FALL);
c.add(Season.SPRING);
// 复制Collection集合中所有元素来创建EnumSet集合
EnumSet enumSet = EnumSet.copyOf(c); // ①
System.out.println(enumSet); // 输出[SPRING,FALL]
c.add("疯狂Java讲义");
c.add("轻量级Java EE企业应用实战");
// 下面代码出现异常:因为c集合里的元素不是全部都为枚举值
enumSet = EnumSet.copyOf(c); // ②
}
}各Set实现类的性能分析
1.HashSet的性能总是比TreeSet好,因为TreeSet需要额外的红黑树算法来维护集合元素的次序。只有需要一个保持排序的Set时,才使用TreeSet,否则使用HashSet
2.对于LinkedHashSet,对于普通的插入删除操作,它比HashSet略慢,这是由于维护链表所带来的额外开销造成的,但遍历LinkedHashSet会更快
3.EnumSet是所有Set实现类中性能最好的,但只能保存同一个枚举类的枚举值作为集合元素
List集合
List集合代表一个元素有序,可重复的集合,集合中每个元素都有其对应的顺序索引。List集合允许使用重复元素,可以通过索引来访问指定位置的集合元素。List集合默认按元素的添加顺序设置元素的索引,例如第一次添加的索引为0,第二次添加的元素索引为1……
由于List是有序集合,因此List集合里增加了一些根据索引来操作集合元素的方法:
- void add(int index,Object element)
- boolean addAll(int index,Collection c)
- Object get(int index)
- int indexOf(Object o)
- int lastIndexIf(Object o)
- Object remove(int index)
- Object set(int index,Object element)
- List subList(int fromIndex,int toIndex)
- void replaceAll(UnaryOperator operator)
- void sort(Comparator c)
Java 8 为List集合增加了sort()和replaceAll()两个常用的默认方法
- sort()方法需要一个Comparator对象来控制元素排序
- replaceAll()方法需要一个UnaryOperator来替换所有集合元素
public class ListTest3
{
public static void main(String[] args)
{
List books = new ArrayList();
// 向books集合中添加4个元素
books.add(new String("轻量级Java EE企业应用实战"));
books.add(new String("疯狂Java讲义"));
books.add(new String("疯狂Android讲义"));
books.add(new String("疯狂iOS讲义"));
// 使用目标类型为Comparator的Lambda表达式对List集合排序
books.sort((o1, o2)->((String)o1).length() - ((String)o2).length());
System.out.println(books);
// 使用目标类型为UnaryOperator的Lambda表达式来替换集合中所有元素
// 该Lambda表达式控制使用每个字符串的长度作为新的集合元素
books.replaceAll(ele->((String)ele).length());
System.out.println(books); // 输出[7, 8, 11, 16]
}
}List还额外提供了一个listIterator()方法,该方法返回一个ListIterator对象,ListIterator接口继承了Iterator接口,并且增加了如下的方法:
- boolean hasPrevious()
- Object previous()
- void add(Object o)
public class ListIteratorTest
{
public static void main(String[] args)
{
String[] books = {
"疯狂Java讲义", "疯狂iOS讲义",
"轻量级Java EE企业应用实战"
};
List bookList = new ArrayList();
for (int i = 0; i < books.length ; i++ )
{
bookList.add(books[i]);
}
ListIterator lit = bookList.listIterator();
while (lit.hasNext())
{
System.out.println(lit.next());
lit.add("-------分隔符-------");
}
System.out.println("=======下面开始反向迭代=======");
while(lit.hasPrevious())
{
System.out.println(lit.previous());
}
}
}1.ArrayList和Vector实现类
ArrayList和Vector类都是基于数组实现的List类,所以都封装了一个动态的,允许再分配的Object[]数组,都使用initialCapacity参数来设置该数组的长度
当需要添加大量元素时,可使用ensureCapacity(int minCapacity)方法一次性增加initialCapacity
如不指定,则initialCapacity默认长度为10
ArratList和Vector提供了如下两个方法来重新分配Object[]数组:
- void ensureCapacity(int minCapacity)
- void trimToSize()
ArrayList是线程不安全的,Vector是线程安全的,即使如此,也不推荐使用Vector,可用Collections工具类,使ArrayList变成线程安全的
Stack类继承Vector,同样不推荐使用,如需使用“栈”,可用ArrayDeque
2.固定长度的List
Arrays,一个操作数组的工具类,提供了asList(Object… a)方法,可以把一个数组或指定个数的对象转换成一个List集合,这个List集合是Arrays内部类ArrayList的实例
Arrays.ArrayList是一个固定长度的List集合,程序只能遍历访问该集合里的元素,不可增加删除该集合里的元素
public class FixedSizeList
{
public static void main(String[] args)
{
List fixedList = Arrays.asList("疯狂Java讲义"
, "轻量级Java EE企业应用实战");
// 获取fixedList的实现类,将输出Arrays$ArrayList
System.out.println(fixedList.getClass());
// 使用方法引用遍历集合元素
fixedList.forEach(System.out::println);
// 试图增加、删除元素都会引发UnsupportedOperationException异常
fixedList.add("疯狂Android讲义");
fixedList.remove("疯狂Java讲义");
}
}3.LinkedList实现类
LinkedList类是List接口的实现类—这意味着它是一个List集合,可以根据索引来随机访问集合中的元素。除此之外,LinkedList还实现了Deque接口,可以被当成双端队列来使用,因此可以被当成“栈”和“队列”
public class LinkedListTest
{
public static void main(String[] args)
{
LinkedList books = new LinkedList();
// 将字符串元素加入队列的尾部
books.offer("疯狂Java讲义");
// 将一个字符串元素加入栈的顶部
books.push("轻量级Java EE企业应用实战");
// 将字符串元素添加到队列的头部(相当于栈的顶部)
books.offerFirst("疯狂Android讲义");
// 以List的方式(按索引访问的方式)来遍历集合元素
for (int i = 0; i < books.size() ; i++ )
{
System.out.println("遍历中:" + books.get(i));
}
// 访问、并不删除栈顶的元素
System.out.println(books.peekFirst());
// 访问、并不删除队列的最后一个元素
System.out.println(books.peekLast());
// 将栈顶的元素弹出“栈”
System.out.println(books.pop());
// 下面输出将看到队列中第一个元素被删除
System.out.println(books);
// 访问、并删除队列的最后一个元素
System.out.println(books.pollLast());
// 下面输出:[轻量级Java EE企业应用实战]
System.out.println(books);
}
}上面代码示范了LinkedList作为List集合、双端队列、栈的用法
Queue集合
Queue集合,模拟“队列”先进先出,对头保存在队列中存放时间最长的元素,队列的尾部保存在队列中存放时间最短的元素。新元素插入到队列尾部,访问元素操作会返回队列头部的元素
Queue定义了如下几个方法:
- void add(Object e) 加入队尾
- Object element() 获取对头不删
- boolean offer(Object e) 加入对尾,若队列有容量限制,则比add更快
- Object peek() 获取对头不删
- Object poll() 获取对头删
- Object remove() 获取对头删
1.PriorityQueue实现类
PriorityQueue保存队列元素顺序并不是按加入队列的顺序,而是按队列元素的大小进行重新排序
public class PriorityQueueTest
{
public static void main(String[] args)
{
PriorityQueue pq = new PriorityQueue();
// 下面代码依次向pq中加入四个元素
pq.offer(6);
pq.offer(-3);
pq.offer(20);
pq.offer(18);
// 输出pq队列,并不是按元素的加入顺序排列
System.out.println(pq); // 输出[-3, 6, 20, 18]
// 访问队列第一个元素,其实就是队列中最小的元素:-3
System.out.println(pq.poll());
}
}看到上面的程序并没有很好地按照大小进行排序是受到toString方法的影响
同样可以自然排序和定制排序
2.Deque接口与ArrayDeque实现类
Deque接口是Queue接口的子接口,代表双端队列,下面是常用的方法
- void addFirst(Object e)
- void addLast(Object e)
- Iterator descendingIterator()
- Object getFirsr()
- Object getLast()
- boolean offerFirst(Object e)
- boolean offerLast(Object e)
- Object peekFirst()
- Object peekLast()
- Object pollFirst()
- Object pollLast()
- Object pop()
- void push(Object e)
- Object removeFirst()
- Object removeFirstOccurrence(Object o)
- Object removeLast()
- Object removeLastOccurrence(Object o)
下面程序把ArrayList当成“栈”来使用
public class ArrayDequeStack
{
public static void main(String[] args)
{
ArrayDeque stack = new ArrayDeque();
// 依次将三个元素push入"栈"
stack.push("疯狂Java讲义");
stack.push("轻量级Java EE企业应用实战");
stack.push("疯狂Android讲义");
// 输出:[疯狂Android讲义, 轻量级Java EE企业应用实战, 疯狂Java讲义]
System.out.println(stack);
// 访问第一个元素,但并不将其pop出"栈",输出:疯狂Android讲义
System.out.println(stack.peek());
// 依然输出:[疯狂Android讲义, 疯狂Java讲义, 轻量级Java EE企业应用实战]
System.out.println(stack);
// pop出第一个元素,输出:疯狂Android讲义
System.out.println(stack.pop());
// 输出:[轻量级Java EE企业应用实战, 疯狂Java讲义]
System.out.println(stack);
}
}下面程序把ArrayList当成“队”来使用
public class ArrayDequeQueue
{
public static void main(String[] args)
{
ArrayDeque queue = new ArrayDeque();
// 依次将三个元素加入队列
queue.offer("疯狂Java讲义");
queue.offer("轻量级Java EE企业应用实战");
queue.offer("疯狂Android讲义");
// 输出:[疯狂Java讲义, 轻量级Java EE企业应用实战, 疯狂Android讲义]
System.out.println(queue);
// 访问队列头部的元素,但并不将其poll出队列"栈",输出:疯狂Java讲义
System.out.println(queue.peek());
// 依然输出:[疯狂Java讲义, 轻量级Java EE企业应用实战, 疯狂Android讲义]
System.out.println(queue);
// poll出第一个元素,输出:疯狂Java讲义
System.out.println(queue.poll());
// 输出:[轻量级Java EE企业应用实战, 疯狂Android讲义]
System.out.println(queue);
}
}各种线性表的定能分析
1.数组在随机访问时性能最好,链表在插入删除时有较好的性能
2.如果需要遍历List集合元素,对于ArrayList、Vector集合,应该使用随机访问方法(get)来遍历集合元素;对于LinkedList集合,则应采用Iterator迭代器来遍历集合
3.如果需要经常插入、删除操作,可使用LinkedList
4.可使用Collections将集合包装成线程安全的集合
Map集合
Map用于保存具有映射关系的数据,因此Map集合里保存着两组值,一组值用于保存Map里的key,另外一组值用于保存Map里的value,key和value都可以是任何引用类型的数据,Map的key不可以重复
- Map里的key集合Set集合里面的存储形式很像
- Map里的value放在一起看,非常类似于一个List
下面是Map集合的源码:
public interface Map<K,V> {
int size();
boolean isEmpty();
boolean containsKey(Object key);
boolean containsValue(Object value);
V get(Object key);
V put(K key, V value);
V remove(Object key);
void putAll(Map<? extends K, ? extends V> m);
void clear();
Set<K> keySet();
Collection<V> values();
Set<Map.Entry<K, V>> entrySet();
interface Entry<K,V> {
K getKey();
V getValue();
V setValue(V value);
boolean equals(Object o);
int hashCode();
public static <K extends Comparable<? super K>, V> Comparator<Map.Entry<K,V>> comparingByKey() {
return (Comparator<Map.Entry<K, V>> & Serializable)
(c1, c2) -> c1.getKey().compareTo(c2.getKey());
}
public static <K, V extends Comparable<? super V>> Comparator<Map.Entry<K,V>> comparingByValue() {
return (Comparator<Map.Entry<K, V>> & Serializable)
(c1, c2) -> c1.getValue().compareTo(c2.getValue());
}
public static <K, V> Comparator<Map.Entry<K, V>> comparingByKey(Comparator<? super K> cmp) {
Objects.requireNonNull(cmp);
return (Comparator<Map.Entry<K, V>> & Serializable)
(c1, c2) -> cmp.compare(c1.getKey(), c2.getKey());
}
public static <K, V> Comparator<Map.Entry<K, V>> comparingByValue(Comparator<? super V> cmp) {
Objects.requireNonNull(cmp);
return (Comparator<Map.Entry<K, V>> & Serializable)
(c1, c2) -> cmp.compare(c1.getValue(), c2.getValue());
}
}
boolean equals(Object o);
int hashCode();
default V getOrDefault(Object key, V defaultValue) {
V v;
return (((v = get(key)) != null) || containsKey(key))
? v
: defaultValue;
}
default void forEach(BiConsumer<? super K, ? super V> action) {
Objects.requireNonNull(action);
for (Map.Entry<K, V> entry : entrySet()) {
K k;
V v;
try {
k = entry.getKey();
v = entry.getValue();
} catch(IllegalStateException ise) {
// this usually means the entry is no longer in the map.
throw new ConcurrentModificationException(ise);
}
action.accept(k, v);
}
}
default void replaceAll(BiFunction<? super K, ? super V, ? extends V> function) {
Objects.requireNonNull(function);
for (Map.Entry<K, V> entry : entrySet()) {
K k;
V v;
try {
k = entry.getKey();
v = entry.getValue();
} catch(IllegalStateException ise) {
// this usually means the entry is no longer in the map.
throw new ConcurrentModificationException(ise);
}
// ise thrown from function is not a cme.
v = function.apply(k, v);
try {
entry.setValue(v);
} catch(IllegalStateException ise) {
// this usually means the entry is no longer in the map.
throw new ConcurrentModificationException(ise);
}
}
}
default V putIfAbsent(K key, V value) {
V v = get(key);
if (v == null) {
v = put(key, value);
}
return v;
}
default boolean remove(Object key, Object value) {
Object curValue = get(key);
if (!Objects.equals(curValue, value) ||
(curValue == null && !containsKey(key))) {
return false;
}
remove(key);
return true;
}
default boolean replace(K key, V oldValue, V newValue) {
Object curValue = get(key);
if (!Objects.equals(curValue, oldValue) ||
(curValue == null && !containsKey(key))) {
return false;
}
put(key, newValue);
return true;
}
default V replace(K key, V value) {
V curValue;
if (((curValue = get(key)) != null) || containsKey(key)) {
curValue = put(key, value);
}
return curValue;
}
default V computeIfAbsent(K key,
Function<? super K, ? extends V> mappingFunction) {
Objects.requireNonNull(mappingFunction);
V v;
if ((v = get(key)) == null) {
V newValue;
if ((newValue = mappingFunction.apply(key)) != null) {
put(key, newValue);
return newValue;
}
}
return v;
}
default V computeIfPresent(K key,
BiFunction<? super K, ? super V, ? extends V> remappingFunction) {
Objects.requireNonNull(remappingFunction);
V oldValue;
if ((oldValue = get(key)) != null) {
V newValue = remappingFunction.apply(key, oldValue);
if (newValue != null) {
put(key, newValue);
return newValue;
} else {
remove(key);
return null;
}
} else {
return null;
}
}
default V compute(K key,
BiFunction<? super K, ? super V, ? extends V> remappingFunction) {
Objects.requireNonNull(remappingFunction);
V oldValue = get(key);
V newValue = remappingFunction.apply(key, oldValue);
if (newValue == null) {
// delete mapping
if (oldValue != null || containsKey(key)) {
// something to remove
remove(key);
return null;
} else {
// nothing to do. Leave things as they were.
return null;
}
} else {
// add or replace old mapping
put(key, newValue);
return newValue;
}
}
default V merge(K key, V value,
BiFunction<? super V, ? super V, ? extends V> remappingFunction) {
Objects.requireNonNull(remappingFunction);
Objects.requireNonNull(value);
V oldValue = get(key);
V newValue = (oldValue == null) ? value :
remappingFunction.apply(oldValue, value);
if(newValue == null) {
remove(key);
} else {
put(key, newValue);
}
return newValue;
}
}Map中包括一个内部类Entry,该类封装了一个key-value对,Entry包括如下方法:
- Object getKey()
- Object getValue()
- Object setValue(V value)
public class MapTest
{
public static void main(String[] args)
{
Map map = new HashMap();
// 成对放入多个key-value对
map.put("疯狂Java讲义" , 109);
map.put("疯狂iOS讲义" , 10);
map.put("疯狂Ajax讲义" , 79);
// 多次放入的key-value对中value可以重复
map.put("轻量级Java EE企业应用实战" , 99);
// 放入重复的key时,新的value会覆盖原有的value
// 如果新的value覆盖了原有的value,该方法返回被覆盖的value
System.out.println(map.put("疯狂iOS讲义" , 99)); // 输出10
System.out.println(map); // 输出的Map集合包含4个key-value对
// 判断是否包含指定key
System.out.println("是否包含值为 疯狂iOS讲义 key:"
+ map.containsKey("疯狂iOS讲义")); // 输出true
// 判断是否包含指定value
System.out.println("是否包含值为 99 value:"
+ map.containsValue(99)); // 输出true
// 获取Map集合的所有key组成的集合,通过遍历key来实现遍历所有key-value对
for (Object key : map.keySet() )
{
// map.get(key)方法获取指定key对应的value
System.out.println(key + "-->" + map.get(key));
}
map.remove("疯狂Ajax讲义"); // 根据key来删除key-value对。
System.out.println(map); // 输出结果不再包含 疯狂Ajax讲义=79 的key-value对
}
}Java 8 为Map新增的方法
Java 8 除了为Map增加了remove(Object key,Object value)默认方法之外,还增加了如下方法:
- Object compute(Object key,BiFunction remappingFunction)
- Object computeIfAnsent(Object key,Function mappingFunction)
- Object computeIfPresent(Object key,BiFunction remappingFunction)
- void forEach(Biconsumer action)
- Object getOrDefault(Object key,V defaultValue)
- Object merge(Object key,Object value,BiFunction remapingFunction)
- Object putIfAbsent(Object key,Object value)
- Object replace(Object key,Object value)
- replaceAll(BiFunction remappingFunction)
public class MapTest2
{
public static void main(String[] args)
{
Map map = new HashMap();
// 成对放入多个key-value对
map.put("疯狂Java讲义" , 109);
map.put("疯狂iOS讲义" , 99);
map.put("疯狂Ajax讲义" , 79);
// 尝试替换key为"疯狂XML讲义"的value,由于原Map中没有对应的key,
// 因此对Map没有改变,不会添加新的key-value对
map.replace("疯狂XML讲义" , 66);
System.out.println(map);
// 使用原value与参数计算出来的结果覆盖原有的value
map.merge("疯狂iOS讲义" , 10 ,
(oldVal , param) -> (Integer)oldVal + (Integer)param);
System.out.println(map); // "疯狂iOS讲义"的value增大了10
// 当key为"Java"对应的value为null(或不存在时),使用计算的结果作为新value
map.computeIfAbsent("Java" , (key)->((String)key).length());
System.out.println(map); // map中添加了 Java=4 这组key-value对
// 当key为"Java"对应的value存在时,使用计算的结果作为新value
map.computeIfPresent("Java",
(key , value) -> (Integer)value * (Integer)value);
System.out.println(map); // map中 Java=4 变成 Java=16
}
}1.Java 8改进的HashMap实现类
Hahsmap可以使用null作为key或value
由于HashMap的key不能重复,所以最多只有一个key为null,可以有多个value为null
public class NullInHashMap
{
public static void main(String[] args)
{
HashMap hm = new HashMap();
// 试图将两个key为null的key-value对放入HashMap中
hm.put(null , null);
hm.put(null , null); // ①
// 将一个value为null的key-value对放入HashMap中
hm.put("a" , null); // ②
// 输出Map对象
System.out.println(hm);
}
}判断两个key相等的标准是:
两个key通过equals()判断返回true,两个key的hashCode值也相等
如果使用可变对象作为HashMap的key,并且程序修改了作为key的可变对象,则可能出现程序再也无法准确访问到Map中被修改过的key
public class HashMapErrorTest
{
public static void main(String[] args)
{
HashMap ht = new HashMap();
// 此处的A类与前一个程序的A类是同一个类
ht.put(new A(60000) , "疯狂Java讲义");
ht.put(new A(87563) , "轻量级Java EE企业应用实战");
// 获得Hashtable的key Set集合对应的Iterator迭代器
Iterator it = ht.keySet().iterator();
// 取出Map中第一个key,并修改它的count值
A first = (A)it.next();
first.count = 87563; // ①
// 输出{A@1560b=疯狂Java讲义, A@1560b=轻量级Java EE企业应用实战}
System.out.println(ht);
// 只能删除没有被修改过的key所对应的key-value对
ht.remove(new A(87563));
System.out.println(ht);
// 无法获取剩下的value,下面两行代码都将输出null。
System.out.println(ht.get(new A(87563))); // ② 输出null
System.out.println(ht.get(new A(60000))); // ③ 输出null
}
}2.LinkedHashMap实现类
LinkedHashMap也使用双向链表来维护Key-Value对的次序,该链表负责维护Map的迭代顺序,迭代顺序与key-value对的插入顺序保持一致,所以性能略低于HashMap的性能,但因为以链表来维护内部顺序,所以在迭代访问Map全部元素时将有较好的性能
public class LinkedHashMapTest
{
public static void main(String[] args)
{
LinkedHashMap scores = new LinkedHashMap();
scores.put("语文" , 80);
scores.put("英文" , 82);
scores.put("数学" , 76);
// 调用forEach方法遍历scores里的所有key-value对
scores.forEach((key, value) -> System.out.println(key + "-->" + value));
}
}3.使用Properties读写属性文件
Properties类在处理属性文件时特别方便,相当于一个ket、value都是String类型的Map:
- String getProperty(String key)
- String getProperty(String key,String defaultValue)
- Object setProperty(String key,String value)
- void load(InputStream inStream)
- void store(OutputStream out,String comments)
public class PropertiesTest
{
public static void main(String[] args)
throws Exception
{
Properties props = new Properties();
// 向Properties中增加属性
props.setProperty("username" , "yeeku");
props.setProperty("password" , "123456");
// 将Properties中的key-value对保存到a.ini文件中
props.store(new FileOutputStream("a.ini")
, "comment line"); //①
// 新建一个Properties对象
Properties props2 = new Properties();
// 向Properties中增加属性
props2.setProperty("gender" , "male");
// 将a.ini文件中的key-value对追加到props2中
props2.load(new FileInputStream("a.ini") ); //②
System.out.println(props2);
}
}4.SortedMap接口和TreeMap实现类
Map接口派生出SortedMap子接口,SortedMap接口有一个TreeMap实现类
TreeMap就是红黑树数据结构,同样可以自然排序和定制排序
重写compareTo()方法时,应保证两个key通过equals()方法比较返回true时,他们通过compareTo()方法比较应该返回0
TreeMap也提供了一系列根据key顺序访问key-value对的方法:
- Map.Entry firstEntry()
- Object firstKey()
- Map.Entry lastEntry()
- Object lastKey()
- Map.Entry higherEntry(Object key)
- Object higherKey(Object key)
- Map.Entry lowerEntry(Object key)
- Object lowerKey(Object key)
- Navigable subMap(Object fromKey,boolean fromInclusive,Object toKey,boolean toInclusive)
- SortedMap subMap(Object fromKey,Object toKey)
- SortedMap tailMap(Object fromKey)
- Navigable tailMap(Object fromKey,boolean inclusive)
- SortedMap headMap(Object toKey)
- Navigable headMap(Object toKey,boolean inclusive)
class R implements Comparable
{
int count;
public R(int count)
{
this.count = count;
}
public String toString()
{
return "R[count:" + count + "]";
}
// 根据count来判断两个对象是否相等。
public boolean equals(Object obj)
{
if (this == obj)
return true;
if (obj != null && obj.getClass() == R.class)
{
R r = (R)obj;
return r.count == this.count;
}
return false;
}
// 根据count属性值来判断两个对象的大小。
public int compareTo(Object obj)
{
R r = (R)obj;
return count > r.count ? 1 :
count < r.count ? -1 : 0;
}
}
public class TreeMapTest
{
public static void main(String[] args)
{
TreeMap tm = new TreeMap();
tm.put(new R(3) , "轻量级Java EE企业应用实战");
tm.put(new R(-5) , "疯狂Java讲义");
tm.put(new R(9) , "疯狂Android讲义");
System.out.println(tm);
// 返回该TreeMap的第一个Entry对象
System.out.println(tm.firstEntry());
// 返回该TreeMap的最后一个key值
System.out.println(tm.lastKey());
// 返回该TreeMap的比new R(2)大的最小key值。
System.out.println(tm.higherKey(new R(2)));
// 返回该TreeMap的比new R(2)小的最大的key-value对。
System.out.println(tm.lowerEntry(new R(2)));
// 返回该TreeMap的子TreeMap
System.out.println(tm.subMap(new R(-1) , new R(4)));
}
}5.WeakHashMap实现类
WeakHashMap的key只保留了对实际对象的弱引用,这意味着如果weakHashMap对象的key所引用的对象没有被其他强引用变量所引用,则这些key所引用的对象可能被垃圾回收,weakHashMap也可能自动删除这些key所对应的key-value对
public class WeakHashMapTest
{
public static void main(String[] args)
{
WeakHashMap whm = new WeakHashMap();
// 将WeakHashMap中添加三个key-value对,
// 三个key都是匿名字符串对象(没有其他引用)
whm.put(new String("语文") , new String("良好"));
whm.put(new String("数学") , new String("及格"));
whm.put(new String("英文") , new String("中等"));
//将 WeakHashMap中添加一个key-value对,
// 该key是一个系统缓存的字符串对象。
whm.put("java" , new String("中等")); // ①
// 输出whm对象,将看到4个key-value对。
System.out.println(whm);
// 通知系统立即进行垃圾回收
System.gc();
System.runFinalization();
// 通常情况下,将只看到一个key-value对。
System.out.println(whm);
}
}6.IdentityHashMap实现类
在IdentityHashMap中,当且仅当两个key严格相等(key1 == key2)时,IdentityHashMap才认为两个key相等;对于普通的HashMap,只需要equals()返回true且hashCode值相等即可
public class IdentityHashMapTest
{
public static void main(String[] args)
{
IdentityHashMap ihm = new IdentityHashMap();
// 下面两行代码将会向IdentityHashMap对象中添加两个key-value对
ihm.put(new String("语文") , 89);
ihm.put(new String("语文") , 78);
// 下面两行代码只会向IdentityHashMap对象中添加一个key-value对
ihm.put("java" , 93);
ihm.put("java" , 98);
System.out.println(ihm);
}
}7.EnumMap实现类
EnumMap有如下特征:
- EnumMap在内部以数组形式保存,所以这种实现形式非常紧凑、高效
- EnumMap根据key的自然顺序(即枚举值在枚举类中的定义顺序)来维护key-value对的顺序
- EnumMap不允许null作为key
enum Season
{
SPRING,SUMMER,FALL,WINTER
}
public class EnumMapTest
{
public static void main(String[] args)
{
// 创建EnumMap对象,该EnumMap的所有key都是Season枚举类的枚举值
EnumMap enumMap = new EnumMap(Season.class);
enumMap.put(Season.SUMMER , "夏日炎炎");
enumMap.put(Season.SPRING , "春暖花开");
System.out.println(enumMap);
}
}各Map实现类的性能分析
1.HashMap比HashTable要快
2.TreeMap通常比HashMap要慢,但TreeMap中的key-value总是有序状态。当TreeMap被填充后,就可以调用keySet(),取得由key组成的Set,然后使用toArray()方法生成key的数组,接下来使用Arrays的binarySearch()方法在已排序的数组中快速地查询对象
3.对于一般的应用场景,程序应多多考虑使用HashMap















 644
644











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









