







配置 Flink 进程的内存
Apache Flink 基于 JVM 的高效处理能力,依赖于其对各组件内存用量的细致掌控。 考虑到用户在 Flink 上运行的应用的多样性,尽管社区已经努力为所有配置项提供合理的默认值,仍无法满足所有情况下的需求。 为了给用户生产提供最大化的价值, Flink 允许用户在整体上以及细粒度上对集群的内存分配进行调整。为了优化内存需求,参考网络内存调优指南。
本文接下来介绍的内存配置方法适用于 1.10 及以上版本的 TaskManager 进程和 1.11 及以上版本的 JobManager 进程。 Flink 在 1.10 和 1.11 版本中对内存配置部分进行了较大幅度的改动,从早期版本升级的用户请参考升级指南。
配置总内存
Flink JVM 进程的*进程总内存(Total Process Memory)*包含了由 Flink 应用使用的内存(Flink 总内存)以及由运行 Flink 的 JVM 使用的内存。 Flink 总内存(Total Flink Memory)包括 JVM 堆内存(Heap Memory)和堆外内存(Off-Heap Memory)。 其中堆外内存包括直接内存(Direct Memory)和本地内存(Native Memory)。
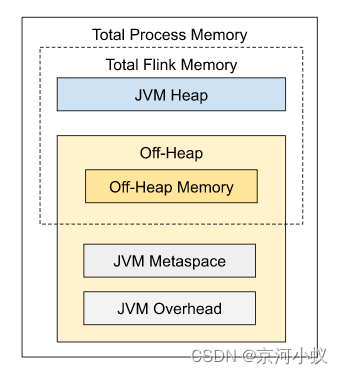
配置 Flink 进程内存最简单的方法是指定以下两个配置项中的任意一个:

提示 关于本地执行,请分别参考 TaskManager 和 JobManager 的相关文档。
Flink 会根据默认值或其他配置参数自动调整剩余内存部分的大小。 关于各内存部分的更多细节,请分别参考 TaskManager 和 JobManager 的相关文档。
对于独立部署模式(Standalone Deployment),如果你希望指定由 Flink 应用本身使用的内存大小,最好选择配置 Flink 总内存。 Flink 总内存会进一步划分为 JVM 堆内存和堆外内存。 更多详情请参考如何为独立部署模式配置内存。
通过配置进程总内存可以指定由 Flink JVM 进程使用的总内存大小。 对于容器化部署模式(Containerized Deployment),这相当于申请的容器(Container)大小,详情请参考如何配置容器内存(Kubernetes 或 Yarn)。
此外,还可以通过设置 Flink 总内存的特定内部组成部分的方式来进行内存配置。 不同进程需要设置的内存组成部分是不一样的。 详情请分别参考 TaskManager 和 JobManager 的相关文档。
提示 以上三种方式中,用户需要至少选择其中一种进行配置(本地运行除外),否则 Flink 将无法启动。 这意味着,用户需要从以下无默认值的配置参数(或参数组合)中选择一个给出明确的配置:
| TaskManager | JobManager |
|---|---|
| taskmanager.memory.flink.size | jobmanager.memory.flink.size |
| taskmanager.memory.process.size | jobmanager.memory.process.size |
| taskmanager.memory.task.heap.size 和 taskmanager.memory.managed.size | jobmanager.memory.heap.size |
提示 不建议同时设置进程总内存和 Flink 总内存。 这可能会造成内存配置冲突,从而导致部署失败。 额外配置其他内存部分时,同样需要注意可能产生的配置冲突。
JVM 参数
Flink 进程启动时,会根据配置的和自动推导出的各内存部分大小,显式地设置以下 JVM 参数:
| JVM 参数 | TaskManager 取值 | JobManager 取值 |
|---|---|---|
| -Xmx 和 -Xms | Framework + Task Heap Memory(框架堆内存 + 任务堆内存) | JVM Heap Memory (JVM 堆内存 (*)) |
| -XX:MaxDirectMemorySize(TaskManager 始终设置,JobManager 见注释) | Framework + Task Off-heap (**) + Network Memory (框架堆外内存 + 任务堆外内存(**) + 网络内存) | Off-heap Memory (**),(***)(堆外内存) |
| -XX:MaxMetaspaceSize | JVM Metaspace | JVM Metaspace |
(*) 请记住,根据所使用的 GC 算法,你可能无法使用到全部堆内存。一些 GC 算法会为它们自身分配一定量的堆内存。这会导致堆的指标返回一个不同的最大值。
(**) 请注意,堆外内存也包括了用户代码使用的本地内存(非直接内存)。
(***) 只有在 jobmanager.memory.enable-jvm-direct-memory-limit 设置为 true 时,JobManager 才会设置 JVM 直接内存限制。
受限的等比内存部分
本节介绍下列内存部分的配置方法,它们都可以通过指定在总内存中所占比例的方式进行配置,同时受限于相应的的最大/最小值范围。
- JVM 开销:可以配置占用进程总内存的固定比例
- 网络内存:可以配置占用 Flink 总内存的固定比例(仅针对 TaskManager)
相关内存部分的配置方法,请同时参考 TaskManager 和 JobManager 的详细内存模型。
这些内存部分的大小必须在相应的最大值、最小值范围内,否则 Flink 将无法启动。 最大值、最小值具有默认值,也可以通过相应的配置参数进行设置。 例如,如果仅配置下列参数:
- total Process memory = 1000Mb,
- JVM Overhead min = 64Mb,
- JVM Overhead max = 128Mb,
- JVM Overhead fraction = 0.1
那么 JVM 开销的实际大小将会是 1000Mb x 0.1 = 100Mb,在 64-128Mb 的范围内。
如果将最大值、最小值设置成相同大小,那相当于明确指定了该内存部分的大小。
如果没有明确指定内存部分的大小,Flink 会根据总内存和占比计算出该内存部分的大小。 计算得到的内存大小将受限于相应的最大值、最小值范围。 例如,如果仅配置下列参数:
- total Process memory = 1000Mb,
- JVM Overhead min = 128Mb,
- JVM Overhead max = 256Mb,
- JVM Overhead fraction = 0.1
那么 JVM 开销的实际大小将会是 128Mb,因为根据总内存和占比计算得到的内存大小 100Mb 小于最小值。
如果配置了总内存和其他内存部分的大小,那么 Flink 也有可能会忽略给定的占比。 这种情况下,受限的等比内存部分的实际大小是总内存减去其他所有内存部分后剩余的部分。 这样推导得出的内存大小必须符合最大值、最小值范围,否则 Flink 将无法启动。 例如,如果仅配置下列参数:
- total Process memory = 1000Mb,
- task heap = 100Mb, (similar example can be for JVM Heap in the JobManager)
- JVM Overhead min = 64Mb,
- JVM Overhead max = 256Mb,
- JVM Overhead fraction = 0.1
进程总内存中所有其他内存部分均有默认大小,包括 TaskManager 的托管内存默认占比或 JobManager 的默认堆外内存。 因此,JVM 开销的实际大小不是根据占比算出的大小(1000Mb x 0.1 = 100Mb),而是进程总内存中剩余的部分。 这个剩余部分的大小必须在 64-256Mb 的范围内,否则将会启动失败。
配置 TaskManager 内存
Flink 的 TaskManager 负责执行用户代码。 根据实际需求为 TaskManager 配置内存将有助于减少 Flink 的资源占用,增强作业运行的稳定性。
本文接下来介绍的内存配置方法适用于 1.10 及以上版本。 Flink 在 1.10 版本中对内存配置部分进行了较大幅度的改动,从早期版本升级的用户请参考升级指南。
提示 本篇内存配置文档仅针对 TaskManager, 与 JobManager 相比,TaskManager 具有相似但更加复杂的内存模型。
配置总内存
Flink JVM 进程的*进程总内存(Total Process Memory)*包含了由 Flink 应用使用的内存(Flink 总内存)以及由运行 Flink 的 JVM 使用的内存。 其中,*Flink 总内存(Total Flink Memory)*包括 JVM 堆内存(Heap Memory)、*托管内存(Managed Memory)*以及其他直接内存(Direct Memory)或本地内存(Native Memory)。
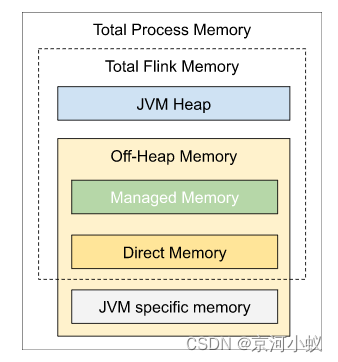
如果你是在本地运行 Flink(例如在 IDE 中)而非创建一个集群,那么本文介绍的配置并非所有都是适用的,详情请参考本地执行。
其他情况下,配置 Flink 内存最简单的方法就是配置总内存。 此外,Flink 也支持更细粒度的内存配置方式。
Flink 会根据默认值或其他配置参数自动调整剩余内存部分的大小。 接下来的章节将介绍关于各内存部分的更多细节。
配置堆内存和托管内存
如配置总内存中所述,另一种配置 Flink 内存的方式是同时设置任务堆内存和托管内存。 通过这种方式,用户可以更好地掌控用于 Flink 任务的 JVM 堆内存及 Flink 的托管内存大小。
Flink 会根据默认值或其他配置参数自动调整剩余内存部分的大小。 关于各内存部分的更多细节,请参考相关文档。
提示 如果已经明确设置了任务堆内存和托管内存,建议不要再设置进程总内存或 Flink 总内存,否则可能会造成内存配置冲突。
任务(算子)堆内存(Task (Operator) Heap Memory )
如果希望确保指定大小的 JVM 堆内存给用户代码使用,可以明确指定任务堆内存(taskmanager.memory.task.heap.size)。 指定的内存将被包含在总的 JVM 堆空间中,专门用于 Flink 算子及用户代码的执行。
托管内存(Managed Memory)
托管内存是由 Flink 负责分配和管理的本地(堆外)内存。 以下场景需要使用托管内存:
- 流处理作业中用于 RocksDB State Backend。
- 流处理和批处理作业中用于排序、哈希表及缓存中间结果。
- 流处理和批处理作业中用于在 Python 进程中执行用户自定义函数。
可以通过以下两种范式指定托管内存的大小:
- 通过 taskmanager.memory.managed.size 明确指定其大小。
- 通过 taskmanager.memory.managed.fraction 指定在Flink 总内存中的占比。
- 当同时指定二者时,会优先采用指定的大小(Size)。 若二者均未指定,会根据默认占比进行计算。
请同时参考如何配置 State Backend 内存以及如何配置批处理作业内存。
- 通过 taskmanager.memory.managed.size 明确指定其大小。
- 通过 taskmanager.memory.managed.fraction 指定在Flink 总内存中的占比。
当同时指定二者时,会优先采用指定的大小(Size)。 若二者均未指定,会根据默认占比进行计算。
请同时参考如何配置 State Backend 内存以及如何配置批处理作业内存。
消费者权重
对于包含不同种类的托管内存消费者的作业,可以进一步控制托管内存如何在消费者之间分配。 通过 taskmanager.memory.managed.consumer-weights 可以为每一种类型的消费者指定一个权重,Flink 会按照权重的比例进行内存分配。 目前支持的消费者类型包括:
- OPERATOR: 用于内置算法。
- STATE_BACKEND: 用于流处理中的 RocksDB State Backend。
- PYTHON:用户 Python 进程。
例如,一个流处理作业同时使用到了 RocksDB State Backend 和 Python UDF,消费者权重设置为 STATE_BACKEND:70,PYTHON:30,那么 Flink 会将 70% 的托管内存用于 RocksDB State Backend,30% 留给 Python 进程。
提示 只有作业中包含某种类型的消费者时,Flink 才会为该类型分配托管内存。 例如,一个流处理作业使用 Heap State Backend 和 Python UDF,消费者权重设置为 STATE_BACKEND:70,PYTHON:30,那么 Flink 会将全部托管内存用于 Python 进程,因为 Heap State Backend 不使用托管内存。
提示 对于未出现在消费者权重中的类型,Flink 将不会为其分配托管内存。 如果缺失的类型是作业运行所必须的,则会引发内存分配失败。 默认情况下,消费者权重中包含了所有可能的消费者类型。 上述问题仅可能出现在用户显式地配置了消费者权重的情况下。
配置堆外内存(直接内存或本地内存)
用户代码中分配的堆外内存被归为任务堆外内存(Task Off-heap Memory),可以通过 taskmanager.memory.task.off-heap.size 指定。
提示 你也可以调整框架堆外内存(Framework Off-heap Memory)。 这是一个进阶配置,建议仅在确定 Flink 框架需要更多的内存时调整该配置。
Flink 将框架堆外内存和任务堆外内存都计算在 JVM 的直接内存限制中,请参考 JVM 参数。
提示 本地内存(非直接内存)也可以被归在框架堆外内存或任务堆外内存中,在这种情况下 JVM 的直接内存限制可能会高于实际需求。
提示 网络内存(Network Memory)同样被计算在 JVM 直接内存中。 Flink 会负责管理网络内存,保证其实际用量不会超过配置大小。 因此,调整网络内存的大小不会对其他堆外内存有实质上的影响。
内存模型详解
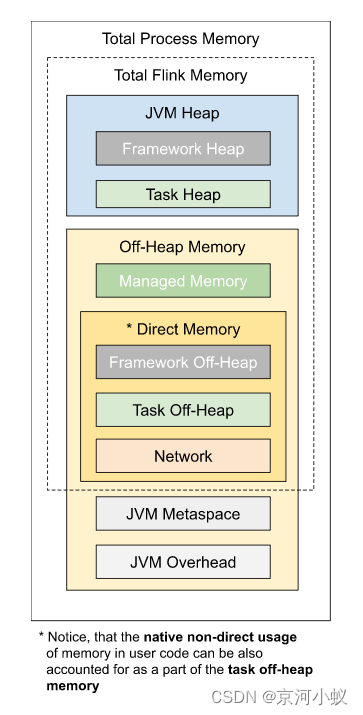
如上图所示,下表中列出了 Flink TaskManager 内存模型的所有组成部分,以及影响其大小的相关配置参数。
| Component | Configuration options | Description |
|---|---|---|
| Framework Heap Memory | taskmanager.memory.framework.heap.size | 用于 Flink 框架的 JVM 堆内存(进阶配置)。 |
| Task Heap Memory | taskmanager.memory.task.heap.size | 用于 Flink 应用的算子及用户代码的 JVM 堆内存 |
| Managed memory | taskmanager.memory.managed.size taskmanager.memory.managed.fraction | 由 Flink 管理的用于排序、哈希表、缓存中间结果及 RocksDB State Backend 的本地内存。 |
| Framework Off-heap Memory | taskmanager.memory.framework.off-heap.size | 用于 Flink 框架的堆外内存(直接内存或本地内存)(进阶配置)。 |
| Task Off-heap Memory | taskmanager.memory.task.off-heap.size | 用于 Flink 应用的算子及用户代码的堆外内存(直接内存或本地内存)。 |
| Network Memory | taskmanager.memory.network.min taskmanager.memory.network.max taskmanager.memory.network.fraction | 用于任务之间数据传输的直接内存(例如网络传输缓冲)。该内存部分为基于 Flink 总内存的受限的等比内存部分。这块内存被用于分配网络缓冲 |
| JVM metaspace | taskmanager.memory.jvm-metaspace.size | Flink JVM 进程的 Metaspace。 |
| JVM Overhead | taskmanager.memory.jvm-overhead.min taskmanager.memory.jvm-overhead.max taskmanager.memory.jvm-overhead.fraction | 用于其他 JVM 开销的本地内存,例如栈空间、垃圾回收空间等。该内存部分为基于进程总内存的受限的等比内存部分。 |
我们可以看到,有些内存部分的大小可以直接通过一个配置参数进行设置,有些则需要根据多个参数进行调整。
框架内存
通常情况下,不建议对框架堆内存和框架堆外内存进行调整。 除非你非常肯定 Flink 的内部数据结构及操作需要更多的内存。 这可能与具体的部署环境及作业结构有关,例如非常高的并发度。 此外,Flink 的部分依赖(例如 Hadoop)在某些特定的情况下也可能会需要更多的直接内存或本地内存。
提示 不管是堆内存还是堆外内存,Flink 中的框架内存和任务内存之间目前是没有隔离的。 对框架和任务内存的区分,主要是为了在后续版本中做进一步优化。
本地执行
如果你是将 Flink 作为一个单独的 Java 程序运行在你的电脑本地而非创建一个集群(例如在 IDE 中),那么只有下列配置会生效,其他配置参数则不会起到任何效果:
| 内存 组成部分 | 配置参数 | 本地执行时的默认值 |
|---|---|---|
| Task heap | taskmanager.memory.task.heap.size | 无穷大 |
| Task off-heap | taskmanager.memory.task.off-heap.size | 无穷大 |
| Managed memory | taskmanager.memory.managed.size | 128Mb |
| Network memory | taskmanager.memory.network.min taskmanager.memory.network.max | 64Mb |
本地执行模式下,上面列出的所有内存部分均可以但不是必须进行配置。 如果未配置,则会采用默认值。 其中,任务堆内存和任务堆外内存的默认值无穷大(Long.MAX_VALUE 字节),以及托管内存的默认值 128Mb 均只针对本地执行模式。
提示 这种情况下,任务堆内存的大小与实际的堆空间大小无关。 该配置参数可能与后续版本中的进一步优化相关。 本地执行模式下,JVM 堆空间的实际大小不受 Flink 掌控,而是取决于本地执行进程是如何启动的。 如果希望控制 JVM 的堆空间大小,可以在启动进程时明确地指定相关的 JVM 参数,即 -Xmx 和 -Xms。
配置 JobManager 内存
JobManager 是 Flink 集群的控制单元。 它由三种不同的组件组成:ResourceManager、Dispatcher 和每个正在运行作业的 JobMaster。 本篇文档将介绍 JobManager 内存在整体上以及细粒度上的配置方法。
本文接下来介绍的内存配置方法适用于 1.11 及以上版本。 Flink 在 1.11 版本中对内存配置部分进行了较大幅度的改动,从早期版本升级的用户请参考升级指南。
提示 本篇内存配置文档仅针对 JobManager! 与 TaskManager 相比,JobManager 具有相似但更加简单的内存模型。
配置总内存
配置 JobManager 内存最简单的方法就是进程的配置总内存。 本地执行模式下不需要为 JobManager 进行内存配置,配置参数将不会生效。
详细配置
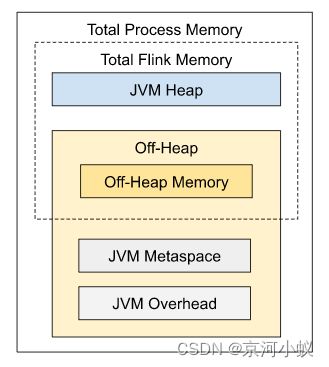
如上图所示,下表中列出了 Flink JobManager 内存模型的所有组成部分,以及影响其大小的相关配置参数。
| 组成部分 | 配置参数 | 描述 |
|---|---|---|
| JVM Heap | jobmanager.memory.heap.size | JobManager 的 JVM 堆内存。 |
| Off-heap Memory | jobmanager.memory.off-heap.size | JobManager 的堆外内存(直接内存或本地内存)。 |
| JVM metaspace | jobmanager.memory.jvm-metaspace.size | Flink JVM 进程的 Metaspace。 |
| JVM Overhead | jobmanager.memory.jvm-overhead.min jobmanager.memory.jvm-overhead.max jobmanager.memory.jvm-overhead.fraction | 用于其他 JVM 开销的本地内存,例如栈空间、垃圾回收空间等。该内存部分为基于进程总内存的受限的等比内存部分。 |
配置 JVM 堆内存
如配置总内存中所述,另一种配置 JobManager 内存的方式是明确指定 JVM 堆内存的大小(jobmanager.memory.heap.size)。 通过这种方式,用户可以更好地掌控用于以下用途的 JVM 堆内存大小。
- Flink 框架
- 在作业提交时(例如一些特殊的批处理 Source)及 Checkpoint 完成的回调函数中执行的用户代码
Flink 需要多少 JVM 堆内存,很大程度上取决于运行的作业数量、作业的结构及上述用户代码的需求。
提示 如果已经明确设置了 JVM 堆内存,建议不要再设置进程总内存或 Flink 总内存,否则可能会造成内存配置冲突。
在启动 JobManager 进程时,Flink 启动脚本及客户端通过设置 JVM 参数 -Xms 和 -Xmx 来管理 JVM 堆空间的大小。 请参考 JVM 参数。
配置堆外内存
堆外内存包括 JVM 直接内存 和 本地内存。 可以通过配置参数 jobmanager.memory.enable-jvm-direct-memory-limit 设置是否启用 JVM 直接内存限制。 如果该配置项设置为 true,Flink 会根据配置的堆外内存大小设置 JVM 参数 -XX:MaxDirectMemorySize。
可以通过配置参数 jobmanager.memory.off-heap.size 设置堆外内存的大小。 如果遇到 JobManager 进程抛出 “OutOfMemoryError: Direct buffer memory” 的异常,可以尝试调大这项配置。 请参考常见问题。
以下情况可能用到堆外内存:
- Flink 框架依赖(例如 Akka 的网络通信)
- 在作业提交时(例如一些特殊的批处理 Source)及 Checkpoint 完成的回调函数中执行的用户代码
提示 如果同时配置了 Flink 总内存和 JVM 堆内存,且没有配置堆外内存,那么堆外内存的大小将会是 Flink 总内存减去JVM 堆内存。 这种情况下,堆外内存的默认大小将不会生效。
本地执行
如果你是在本地运行 Flink(例如在 IDE 中)而非创建一个集群,那么 JobManager 的内存配置将不会生效。
调优指南
本文在的基本的配置指南的基础上,介绍如何根据具体的使用场景调整内存配置,以及在不同使用场景下分别需要重点关注哪些配置参数。
独立部署模式(Standalone Deployment)下的内存配置
独立部署模式下,我们通常更关注 Flink 应用本身使用的内存大小。 建议配置 Flink 总内存(taskmanager.memory.flink.size 或者 jobmanager.memory.flink.size)或其组成部分。 此外,如果出现 Metaspace 不足的问题,可以调整 JVM Metaspace 的大小。
这种情况下通常无需配置进程总内存,因为不管是 Flink 还是部署环境都不会对 JVM 开销 进行限制,它只与机器的物理资源相关。
容器(Container)的内存配置
在容器化部署模式(Containerized Deployment)下(Kubernetes 或 Yarn),建议配置进程总内存(taskmanager.memory.process.size 或者 jobmanager.memory.process.size)。 该配置参数用于指定分配给 Flink JVM 进程的总内存,也就是需要申请的容器大小。
提示 如果配置了 Flink 总内存,Flink 会自动加上 JVM 相关的内存部分,根据推算出的进程总内存大小申请容器。
注意: 如果 Flink 或者用户代码分配超过容器大小的非托管的堆外(本地)内存,部署环境可能会杀掉超用内存的容器,造成作业执行失败。
请参考容器内存超用中的相关描述。
State Backend 的内存配置
本章节内容仅与 TaskManager 相关。
在部署 Flink 流处理应用时,可以根据 State Backend 的类型对集群的配置进行优化。
Heap State Backend
执行无状态作业或者使用 Heap State Backend(MemoryStateBackend 或 FsStateBackend)时,建议将托管内存设置为 0。 这样能够最大化分配给 JVM 上用户代码的内存。
RocksDB State Backend
RocksDBStateBackend 使用本地内存。 默认情况下,RocksDB 会限制其内存用量不超过用户配置的托管内存。 因此,使用这种方式存储状态时,配置足够多的托管内存是十分重要的。 如果你关闭了 RocksDB 的内存控制,那么在容器化部署模式下如果 RocksDB 分配的内存超出了申请容器的大小(进程总内存),可能会造成 TaskExecutor 被部署环境杀掉。 请同时参考如何调整 RocksDB 内存以及 state.backend.rocksdb.memory.managed。
批处理作业的内存配置
Flink 批处理算子使用托管内存来提高处理效率。 算子运行时,部分操作可以直接在原始数据上进行,而无需将数据反序列化成 Java 对象。 这意味着托管内存对应用的性能具有实质上的影响。 因此 Flink 会在不超过其配置限额的前提下,尽可能分配更多的托管内存。 Flink 明确知道可以使用的内存大小,因此可以有效避免 OutOfMemoryError 的发生。 当托管内存不足时,Flink 会优雅地将数据落盘。
常见问题
IllegalConfigurationException
如果遇到从 TaskExecutorProcessUtils 或 JobManagerProcessUtils 抛出的 IllegalConfigurationException 异常,这通常说明您的配置参数中存在无效值(例如内存大小为负数、占比大于 1 等)或者配置冲突。 请根据异常信息,确认出错的内存部分的相关文档及配置信息。
OutOfMemoryError: Java heap space
该异常说明 JVM 的堆空间过小。 可以通过增大总内存、TaskManager 的任务堆内存、JobManager 的 JVM 堆内存等方法来增大 JVM 堆空间。
提示 也可以增大 TaskManager 的框架堆内存。 这是一个进阶配置,只有在确认是 Flink 框架自身需要更多内存时才应该去调整。
OutOfMemoryError: Direct buffer memory
该异常通常说明 JVM 的直接内存限制过小,或者存在直接内存泄漏(Direct Memory Leak)。 请确认用户代码及外部依赖中是否使用了 JVM 直接内存,以及如果使用了直接内存,是否配置了足够的内存空间。 可以通过调整堆外内存来增大直接内存限制。 有关堆外内存的配置方法,请参考 TaskManager、JobManager 以及 JVM 参数的相关文档。
OutOfMemoryError: Metaspace
该异常说明 JVM Metaspace 限制过小。 可以尝试调整 TaskManager、JobManager 的 JVM Metaspace。
IOException: Insufficient number of network buffers
该异常仅与 TaskManager 相关。
该异常通常说明网络内存过小。 可以通过调整以下配置参数增大网络内存:
- taskmanager.memory.network.min
- taskmanager.memory.network.max
- taskmanager.memory.network.fraction
容器(Container)内存超用
如果 Flink 容器尝试分配超过其申请大小的内存(Yarn 或 Kubernetes),这通常说明 Flink 没有预留出足够的本地内存。 可以通过外部监控系统或者容器被部署环境杀掉时的错误信息判断是否存在容器内存超用。
对于 JobManager 进程,你还可以尝试启用 JVM 直接内存限制(jobmanager.memory.enable-jvm-direct-memory-limit),以排除 JVM 直接内存泄漏的可能性。
If RocksDBStateBackend is used:
and memory controlling is disabled: You can try to increase the TaskManager’s managed memory.
and memory controlling is enabled and non-heap memory increases during savepoint or full checkpoints: This may happen due to the glibc memory allocator (see glibc bug). You can try to add the environment variable MALLOC_ARENA_MAX=1 for TaskManagers.
此外,还可以尝试增大 JVM 开销。
请参考如何配置容器内存。
升级指南
在 1.10 和 1.11 版本中,Flink 分别对 TaskManager 和 JobManager 的内存配置方法做出了较大的改变。 部分配置参数被移除了,或是语义上发生了变化。 本篇升级指南将介绍如何将 Flink 1.9 及以前版本的 TaskManager 内存配置升级到 Flink 1.10 及以后版本, 以及如何将 Flink 1.10 及以前版本的 JobManager 内存配置升级到 Flink 1.11 及以后版本。
注意: 请仔细阅读本篇升级指南。 使用原本的和新的内存配制方法可能会使内存组成部分具有截然不同的大小。 未经调整直接沿用 Flink 1.10 以前版本的 TaskManager 配置文件或 Flink 1.11 以前版本的 JobManager 配置文件,可能导致应用的行为、性能发生变化,甚至造成应用执行失败。
提示 在 1.10/1.11 版本之前,Flink 不要求用户一定要配置 TaskManager/JobManager 内存相关的参数,因为这些参数都具有默认值。 新的内存配置要求用户至少指定下列配置参数(或参数组合)的其中之一,否则 Flink 将无法启动。
| TaskManager | JobManager |
|---|---|
| taskmanager.memory.flink.size | jobmanager.memory.flink.size |
| taskmanager.memory.process.size | jobmanager.memory.process.size |
| taskmanager.memory.task.heap.size and taskmanager.memory.managed.size | jobmanager.memory.heap.size |
Flink 自带的默认 flink-conf.yaml 文件指定了 taskmanager.memory.process.size(>= 1.10)和 jobmanager.memory.process.size (>= 1.11),以便与此前的行为保持一致。
可以使用这张电子表格来估算和比较原本的和新的内存配置下的计算结果。
升级 TaskManager 内存配置
配置参数变化
本节简要列出了 Flink 1.10 引入的配置参数变化,并援引其他章节中关于如何升级到新配置参数的相关描述。
下列配置参数已被彻底移除,配置它们将不会产生任何效果。

尽管网络内存的配置参数没有发生太多变化,我们仍建议您检查其配置结果。 网络内存的大小可能会受到其他内存部分大小变化的影响,例如总内存变化时,根据占比计算出的网络内存也可能发生变化。 请参考内存模型详解。
容器切除(Cut-Off)内存相关的配置参数(containerized.heap-cutoff-ratio 和 containerized.heap-cutoff-min)将不再对 TaskManager 进程生效。 请参考如何升级容器切除内存。
总内存(原堆内存)
在原本的内存配置方法中,用于指定用于 Flink 的总内存的配置参数是 taskmanager.heap.size 或 taskmanager.heap.mb。 尽管这两个参数以“堆(Heap)”命名,实际上它们指定的内存既包含了 JVM 堆内存,也包含了其他堆外内存部分。 这两个配置参数目前已被弃用。
如果配置了上述弃用的参数,同时又没有配置与之对应的新配置参数,那它们将按如下规则对应到新的配置参数。
- 独立部署模式(Standalone Deployment)下:Flink 总内存(taskmanager.memory.flink.size)
- 容器化部署模式(Containerized Deployment)下(Yarn):进程总内存(taskmanager.memory.process.size)
建议您尽早使用新的配置参数取代启用的配置参数,它们在今后的版本中可能会被彻底移除。
请参考如何配置总内存.
JVM 堆内存
此前,JVM 堆空间由托管内存(仅在配置为堆上时)及 Flink 用到的所有其他堆内存组成。 这里的其他堆内存是由总内存减去所有其他非堆内存得到的。 请参考如何升级托管内存。
现在,如果仅配置了Flink总内存或进程总内存,JVM 的堆空间依然是根据总内存减去所有其他非堆内存得到的。 请参考如何配置总内存。
此外,你现在可以更直接地控制用于任务和算子的 JVM 的堆内存(taskmanager.memory.task.heap.size),详见任务堆内存。 如果流处理作业选择使用 Heap State Backend(MemoryStateBackend 或 FsStateBackend),那么它同样需要使用 JVM 堆内存。
Flink 现在总是会预留一部分 JVM 堆内存供框架使用(taskmanager.memory.framework.heap.size)。 请参考框架内存。
托管内存
明确的大小
原本用于指定明确的托管内存大小的配置参数(taskmanager.memory.size)已被弃用,与它具有相同语义的新配置参数为 taskmanager.memory.managed.size。 建议使用新的配置参数,原本的配置参数在今后的版本中可能会被彻底移除。
占比
此前,如果不指定明确的大小,也可以将托管内存配置为占用总内存减去网络内存和容器切除内存(仅在 Yarn)之后剩余部分的固定比例(taskmanager.memory.fraction)。 该配置参数已经被彻底移除,配置它不会产生任何效果。 请使用新的配置参数 taskmanager.memory.managed.fraction。 在未通过 taskmanager.memory.managed.size 指定明确大小的情况下,新的配置参数将指定托管内存在 Flink 总内存中的所占比例。
RocksDB State Backend
流处理作业如果选择使用 RocksDBStateBackend,它使用的本地内存现在也被归为托管内存。 默认情况下,RocksDB 将限制其内存用量不超过托管内存大小,以避免在 Yarn 上容器被杀。你也可以通过设置 state.backend.rocksdb.memory.managed 来关闭 RocksDB 的内存控制。 请参考如何升级容器切除内存。
其他变化
此外,Flink 1.10 对托管内存还引入了下列变化:
- 托管内存现在总是在堆外。配置参数 taskmanager.memory.off-heap 已被彻底移除,配置它不会产生任何效果。
- 托管内存现在使用本地内存而非直接内存。这意味着托管内存将不在 JVM 直接内存限制的范围内。
- 托管内存现在总是惰性分配的。配置参数 taskmanager.memory.preallocate 已被彻底移除,配置它不会产生任何效果。
升级 JobManager 内存配置
在原本的内存配置方法中,用于指定 JVM 堆内存 的配置参数是:
- jobmanager.heap.size
- jobmanager.heap.mb
尽管这两个参数以“堆(Heap)”命名,在此之前它们实际上只有在独立部署模式才完全对应于 JVM 堆内存。 在容器化部署模式下(Kubernetes 和 Yarn),它们指定的内存还包含了其他堆外内存部分。 JVM 堆空间的实际大小,是参数指定的大小减去容器切除(Cut-Off)内存后剩余的部分。 容器切除内存在 1.11 及以上版本中已被彻底移除。
从 1.11 版本开始,Flink 将采用与独立部署模式相同的方式设置这些参数。
这两个配置参数目前已被弃用。 如果配置了上述弃用的参数,同时又没有配置与之对应的新配置参数,那它们将按如下规则对应到新的配置参数。
Flink JVM 进程内存限制
从 1.10 版本开始,Flink 通过设置相应的 JVM 参数,对 TaskManager 进程使用的 JVM Metaspace 和 JVM 直接内存进行限制。 从 1.11 版本开始,Flink 同样对 JobManager 进程使用的 JVM Metaspace 进行限制。 此外,还可以通过设置 jobmanager.memory.enable-jvm-direct-memory-limit 对 JobManager 进程的 JVM 直接内存进行限制。 请参考 JVM 参数。
Flink 通过设置上述 JVM 内存限制降低内存泄漏问题的排查难度,以避免出现容器内存溢出等问题。 请参考常见问题中关于 JVM Metaspace 和 JVM 直接内存 OutOfMemoryError 异常的描述。
容器切除(Cut-Off)内存
在容器化部署模式(Containerized Deployment)下,此前你可以指定切除内存。 这部分内存将预留给所有未被 Flink 计算在内的内存开销。 其主要来源是不受 Flink 直接管理的依赖使用的内存,例如 RocksDB、JVM 内部开销等。 相应的配置参数(containerized.heap-cutoff-ratio 和 containerized.heap-cutoff-min)不再生效。 新的内存配置方法引入了新的内存组成部分来具体描述这些内存用量。
TaskManager
流处理作业如果使用了 RocksDBStateBackend,RocksDB 使用的本地内存现在将被归为托管内存。 默认情况下,RocksDB 将限制其内存用量不超过托管内存大小。 请同时参考如何升级托管内存以及如何配置托管内存。
其他堆外(直接或本地)内存开销,现在可以通过下列配置参数进行设置:
- 任务堆外内存(taskmanager.memory.task.off-heap.size)
- 框架堆外内存(taskmanager.memory.framework.off-heap.size)
- JVM Metaspace(taskmanager.memory.jvm-metaspace.size)
- JVM 开销
JobManager
可以通过下列配置参数设置堆外(直接或本地)内存开销:
- 堆外内存(Off-heap memory) (jobmanager.memory.off-heap.size)
- JVM Metaspace (jobmanager.memory.jvm-metaspace.size)
- JVM 开销(JVM overhead)
flink-conf.yaml 中的默认配置
本节描述 Flink 自带的默认 flink-conf.yaml 文件中的变化。
原本的 TaskManager 总内存(taskmanager.heap.size)被新的配置项 taskmanager.memory.process.size 所取代。 默认值从 1024Mb 增加到了 1728Mb。
原本的 JobManager 总内存(jobmanager.heap.size)被新的配置项 jobmanager.memory.process.size 所取代。 默认值从 1024Mb 增加到了 1600Mb。
请参考如何配置总内存。
注意: 使用新的默认 flink-conf.yaml 可能会造成各内存部分的大小发生变化,从而产生性能变化。
网络内存调优指南
概述
Flink 中每条消息都会被放到网络缓冲(network buffer) 中,并以此为最小单位发送到下一个 subtask。 为了维持连续的高吞吐,Flink 在传输过程的输入端和输出端使用了网络缓冲队列。
每个 subtask 都有一个输入队列来接收数据和一个输出队列来发送数据到下一个 subtask。 在 pipeline 场景,拥有更多的中间缓存数据可以使 Flink 提供更高、更富有弹性的吞吐量,但是也会增加快照时间。
只有所有的 subtask 都收到了全部注入的 checkpoint barrier 才能完成快照。 在对齐的 checkpoints 中,checkpoint barrier 会跟着网络缓冲数据在 job graph 中流动。 缓冲数据越多,checkpoint barrier 流动的时间就越长。在非对齐的 checkpoints 中,缓冲数据越多,checkpoint 就会越大,因为这些数据都会被持久化到 checkpoint 中。
缓冲消胀机制(Buffer Debloating)
之前,配置缓冲数据量的唯一方法是指定缓冲区的数量和大小。然而,因为每次部署的不同很难配置一组完美的参数。 Flink 1.14 新引入的缓冲消胀机制尝试通过自动调整缓冲数据量到一个合理值来解决这个问题。
缓冲消胀功能计算 subtask 可能达到的最大吞吐(始终保持繁忙状态时)并且通过调整缓冲数据量来使得数据的消费时间达到配置值。
可以通过设置 taskmanager.network.memory.buffer-debloat.enabled 为 true 来开启缓冲消胀机制。 通过设置 taskmanager.network.memory.buffer-debloat.target 为 duration 类型的值来指定消费缓冲数据的目标时间。 默认值应该能满足大多数场景。
这个功能使用过去的吞吐数据来预测消费剩余缓冲数据的时间。如果预测不准,缓冲消胀机制会导致以下问题:
- 没有足够的缓存数据来提供全量吞吐。
- 有太多缓冲数据对 checkpoint barrier 推进或者非对齐的 checkpoint 的大小造成不良影响。
如果您的作业负载经常变化(即,突如其来的数据尖峰,定期的窗口聚合触发或者 join ),您可能需要调整以下设置:
- taskmanager.network.memory.buffer-debloat.period:这是缓冲区大小重算的最小时间周期。周期越小,缓冲消胀机制的反应时间就越快,但是必要的计算会消耗更多的CPU。
- taskmanager.network.memory.buffer-debloat.samples:调整用于计算平均吞吐量的采样数。采集样本的频率可以通过 taskmanager.network.memory.buffer-debloat.period 来设置。样本数越少,缓冲消胀机制的反应时间就越快,但是当吞吐量突然飙升或者下降时,缓冲消胀机制计算的最佳缓冲数据量会更容易出错。
- taskmanager.network.memory.buffer-debloat.threshold-percentages:防止缓冲区大小频繁改变的优化(比如,新的大小跟旧的大小相差不大)。
更多详细和额外的参数配置,请参考配置参数。
您可以使用以下指标来监控当前的缓冲区大小:
- estimatedTimeToConsumeBuffersMs:消费所有输入通道(input channel)中数据的总时间。
- debloatedBufferSize:当前的缓冲区大小。
限制
当前,有一些场景还没有自动地被缓冲消胀机制处理。
多个输入和合并
当前,吞吐计算和缓冲消胀发生在 subtask 层面。
如果您的 subtask 有很多不同的输入或者有一个合并的输入,缓冲消胀可能会导致低吞吐的输入有太多缓冲数据,而高吞吐输入的缓冲区数量可能太少而不够维持当前吞吐。当不同的输入吞吐差别比较大时,这种现象会更加的明显。我们推荐您在测试这个功能时重点关注这种 subtask。
缓冲区的尺寸和个数
当前,缓冲消胀仅在使用的缓冲区大小上设置上限。实际的缓冲区大小和个数保持不变。这意味着缓冲消胀机制不会减少作业的内存使用。您应该手动减少缓冲区的大小或者个数。
此外,如果您想减少缓冲数据量使其低于缓冲消胀当前允许的量,您可能需要手动的设置缓冲区的个数。
High parallelism
目前,使用默认配置,缓冲区去浮机制可能无法在高并行度(高于 ~200)的情况下正确执行。如果观察到吞吐量降低或高于预期的检查点时间,我们建议将浮动缓冲区 (taskmanager.network.memory.floating-buffers-per-gate) 的数量从默认值增加到至少等于并行度的数量。
发生问题的并行度的实际值因作业而异,但通常应该超过几百个。
网络缓冲生命周期
Flink 有多个本地缓冲区池 —— 每个输出和输入流对应一个。 每个缓冲区池的大小被限制为
#channels * taskmanager.network.memory.buffers-per-channel + taskmanager.network.memory.floating-buffers-per-gate
缓冲区的大小可以通过 taskmanager.memory.segment-size 来设置。
输入网络缓冲
输入通道中的缓冲区被分为独占缓冲区(exclusive buffer)和流动缓冲区(floating buffer)。每个独占缓冲区只能被一个特定的通道使用。 一个通道可以从输入流的共享缓冲区池中申请额外的流动缓冲区。剩余的流动缓冲区是可选的并且只有资源足够的时候才能获取。
在初始阶段:
- Flink 会为每一个输入通道获取配置数量的独占缓冲区。
- 所有的独占缓冲区都必须被满足,否则作业会抛异常失败。
- Flink 至少要有一个流动缓冲区才能运行。
输出网络缓冲
不像输入缓冲区池,输出缓冲区池只有一种类型的缓冲区被所有的 subpartitions 共享。
为了避免过多的数据倾斜,每个 subpartition 的缓冲区数量可以通过 taskmanager.network.memory.max-buffers-per-channel 来限制。
不同于输入缓冲区池,这里配置的独占缓冲区和流动缓冲区只被当作推荐值。如果没有足够的缓冲区,每个输出 subpartition 可以只使用一个独占缓冲区而没有流动缓冲区。
缓冲区的数量
独占缓冲区和流动缓冲区的默认配置应该足以应对最大吞吐。如果想要最小化缓冲数据量,那么可以将独占缓冲区设置为 0,同时减小内存段的大小。
选择缓冲区的大小
在往下游 subtask 发送数据部分时,缓冲区通过汇集 record 来优化网络开销。下游 subtask 应该在接收到完整的 record 后才开始处理它。
如果缓冲区大小太小,或者缓冲区刷新得太频繁(execute.buffer-timeout 配置参数),这可能会导致吞吐量降低,因为每个缓冲区的开销明显高于 Flink 运行时的每记录开销。
根据经验,我们不建议考虑增加缓冲区大小或缓冲区超时,除非您能在实际工作负载中观察到网络瓶颈(下游算子空转、上游背压、输出缓冲区队列已满、下游输入队列为空)。
如果缓冲区太大,会导致:
- 内存使用高
- 大量的 checkpoint 数据量(针对非对齐的 checkpoints)
- 漫长的 checkpoint 时间(针对对齐的 checkpoints)
- execution.buffer-timeout 较小时内存分配使用率会比较低,因为缓冲区还没被塞满数据就被发送下去了。
选择缓冲区的数量
缓冲区的数量是通过 taskmanager.network.memory.buffers-per-channel 和 taskmanager.network.memory.floating-buffers-per-gate 来配置的。
为了最好的吞吐率,我们建议使用独占缓冲区和流动缓冲区的默认值(except you have one of limit cases)。如果缓冲数据量存在问题,更建议打开缓冲消胀。
您可以人工地调整网络缓冲区的个数,但是需要注意:
- 您应该根据期待的吞吐量(单位 bytes/second)来调整缓冲区的数量。协调数据传输量(大约两个节点之间的两个往返消息)。延迟也取决于您的网络。
使用 buffer 往返时间(大概 1ms 在正常的本地网络中),缓冲区大小和期待的吞吐,您可以通过下面的公式计算维持吞吐所需要的缓冲区数量:
number_of_buffers = expected_throughput * buffer_roundtrip / buffer_size
比如,期待吞吐为 320MB/s,往返延迟为 1ms,内存段为默认大小,为了维持吞吐需要使用10个活跃的缓冲区:
number_of_buffers = 320MB/s * 1ms / 32KB = 10
-
流动缓冲区的目的是为了处理数据倾斜。理想情况下,流动缓冲区的数量(默认8个)和每个通道独占缓冲区的数量(默认2个)能够使网络吞吐量饱和。但这并不总是可行和必要的。所有 subtask 中只有一个通道被使用也是非常罕见的。
-
独占缓冲区的目的是提供一个流畅的吞吐量。当一个缓冲区在传输数据时,另一个缓冲区被填充。当吞吐量比较高时,独占缓冲区的数量是决定 Flink 中缓冲数据的主要因素。
当低吞吐量下出现反压时,您应该考虑减少独占缓冲区。
总结
可以通过开启缓冲消胀机制来简化 Flink 网络的内存配置调整。您也可能需要调整它。
如果这不起作用,您可以关闭缓冲消胀机制并且人工地配置内存段的大小和缓冲区个数。针对第二种场景,我们推荐:
- 使用默认值以获得最大吞吐
- 减少内存段大小、独占缓冲区的数量来加快 checkpoint 并减少网络栈消耗的内存量
















 9669
9669











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











