







调试窗口与事件时间
监控当前事件时间(Event Time)
Flink 的事件时间和 watermark 支持对于处理乱序事件是十分强大的特性。然而,由于是系统内部跟踪时间进度,所以很难了解究竟正在发生什么。
可以通过 Flink web 界面或指标系统访问 task 的 low watermarks。
Flink 中的 task 通过调用 currentInputWatermark 方法暴露一个指标,该指标表示当前 task 所接收到的 the lowest watermark。这个 long 类型值表示“当前事件时间”。该值通过获取上游算子收到的所有 watermarks 的最小值来计算。这意味着用 watermarks 跟踪的事件时间总是由最落后的 source 控制。
使用 web 界面可以访问 low watermark 指标,在指标选项卡中选择一个 task,然后选择 <taskNr>.currentInputWatermark 指标。在新的显示框中,你可以看到此 task 的当前 low watermark。
获取指标的另一种方式是使用指标报告器之一,如指标系统文档所述。对于本地集群设置,我们推荐使用 JMX 指标报告器和类似于 VisualVM 的工具。
处理散乱的事件时间
- 方式 1:延迟的 Watermark(表明完整性),窗口提前触发
- 方式 2:具有最大延迟启发式的 Watermark,窗口接受迟到的数据
调试类加载
Flink中的类加载概述
在运行Flink应用程序时,JVM将随着时间的推移加载各种类。根据它们的起源,这些类别可以分为三类:
-
Java类路径:这是Java的公共类路径,它包括JDK库和Flink的/lib文件夹中的所有代码(Apache Flink的类和一些依赖项)。它们由AppClassLoader加载。
-
Flink插件组件:插件代码在Flink /plugins文件夹下的文件夹中。Flink的插件机制将在启动时动态加载它们一次。
-
动态用户代码:这些都包含在动态提交作业的JAR文件中(通过REST、CLI、web UI)。它们由FlinkUserCodeClassLoader动态加载(和卸载)每个作业。
一般来说,只要先启动Flink进程,然后提交作业,作业的类就会被动态加载。如果Flink进程与作业/应用程序一起启动,或者应用程序生成了Flink组件(JobManager、TaskManager等),那么所有作业的类都在Java类路径中。
插件组件中的代码由每个插件的专用类加载器动态加载一次。
以下是不同部署模式的详细信息:
Session Mode (Standalone/Yarn/Kubernetes)
当启动一个Flink会话(Standalone/Yarn/Kubernetes)集群时,JobManagers和TaskManagers会在Java类路径中使用Flink框架类启动。根据会话(通过REST / CLI)提交的所有作业/应用程序的类都是由FlinkUserCodeClassLoader动态加载的。
Per-Job Mode (deprecated) (Yarn)
目前,只有Yarn支持Per-Job模式。默认情况下,在Per-Job模式下运行Flink集群将把用户JAR文件(在启动命令中指定的JAR文件和Flink的usrlib文件夹中的所有JAR文件)包含到系统类路径(AppClassLoader)中。这种行为可以通过yarn.classpath进行控制。include-user-jar配置选项。当设置为DISABLED时,Flink将在用户类路径中包含用户jar文件,并通过FlinkUserCodeClassLoader动态加载它们。请参阅Flink on Yarn了解更多细节。
Application Mode (Standalone/Yarn/Kubernetes)
当在应用模式下运行独立/Kubernetes Flink集群时,用户JAR(在启动命令中指定的JAR文件和Flink的usrlib文件夹中的所有JAR文件)将由FlinkUserCodeClassLoader动态加载。
当在应用模式下运行Yarn Flink集群时,用户JAR(在启动命令中指定的JAR文件和Flink的usrlib文件夹中的所有JAR文件)将默认包含在系统类路径(AppClassLoader)中。当设置yarn.classpath时,与Per-Job模式相同。include-user-jar到DISABLED, Flink将把用户jar包含在用户类路径中,并通过FlinkUserCodeClassLoader动态加载它们。
反向类装入和类装入器解析顺序
在涉及动态类加载的设置中(插件组件,会话设置中的Flink任务),有一个典型的两个classloader层次结构:(1)Java应用程序类加载器,它在类路径中包含所有类;(2)动态插件/用户代码类加载器。用于从插件或用户代码jar中加载类。动态ClassLoader以应用程序类加载器作为它的父类。
默认情况下,Flink转换类加载顺序,这意味着它首先查看动态类加载器,只有在类不是动态加载代码的一部分时才查看父类(应用程序类加载器)。
反向类加载的好处是插件和作业可以使用不同于Flink核心本身的库版本,这在库的不同版本不兼容时非常有用。该机制有助于避免常见的依赖冲突错误,如IllegalAccessError或NoSuchMethodError。代码的不同部分只是有类的单独副本(Flink的核心或它的一个依赖项可以使用不同于用户代码或插件代码的副本)。在大多数情况下,这工作得很好,不需要用户进行额外的配置。
但是,在某些情况下,反向类加载会导致问题(参见下面的“X不能转换为X”)。对于用户代码类加载,您可以通过类加载器配置ClassLoader解析顺序来恢复到Java的默认模式。在Flink配置中将resolve-order转换为parent-first(来自Flink默认的child-first)。
请注意,某些类总是以父类优先的方式解析(首先通过父类加载器),因为它们在Flink的核心和插件/用户代码或面向插件/用户代码的api之间共享。这些类的包是通过类加载器配置的。parent-first-patterns-default classloader.parent-first-patterns-additional。要添加父级优先加载的新包,请设置类加载器。parent-first-patterns-additional配置选项。
避免用户代码的动态类加载
所有组件(JobManager, TaskManager, Client, ApplicationMaster,…)在启动时记录它们的类路径设置。它们可以在日志开头作为环境信息的一部分找到。
当运行JobManager和TaskManagers专用于一个特定作业的设置时,可以将用户代码JAR文件直接放入/lib文件夹,以确保它们是类路径的一部分,并且不是动态加载的。
通常将作业的JAR文件放入/lib目录。JAR将是类路径(AppClassLoader)和动态类加载器(FlinkUserCodeClassLoader)的一部分。因为AppClassLoader是FlinkUserCodeClassLoader的父类(默认情况下,Java加载parent-first),这应该导致类只加载一次。
对于不能将作业的JAR文件放入/lib文件夹的设置(例如,因为设置是一个由多个作业使用的会话),仍然可以将公共库放入/lib文件夹,并避免为这些设置动态加载类。
在用户代码中手动加载类
在某些情况下,转换函数、源或接收器需要手动加载类(通过反射动态加载)。为此,它需要能够访问作业类的类加载器。
在这种情况下,函数(或源或接收)可以被制成RichFunction(例如RichMapFunction或RichWindowFunction),并通过getRuntimeContext(). getusercodeclassloader()访问用户代码类加载器。
X不能被强制转换为X异常
在动态类加载的设置中,您可能会看到这样的异常:com.foo.X不能转换为com.foo.X。这意味着不同的类加载器加载了类com.foo.X的多个版本,并且试图将该类的类型分配给彼此。
一个常见的原因是库与Flink的反向类加载方法不兼容。您可以关闭反向类加载来验证这一点(设置类加载器。在Flink配置中resolve-order: parent-first)或从反向类加载中排除该库(设置classloader)。parent-first模式—Flink配置中的附加内容)。
另一个原因可能是缓存对象实例,如Apache Avro等库产生的,或通过内部的对象(如通过Guava的Interners)产生的。这里的解决方案是,要么建立一个没有任何动态类加载的设置,要么确保各自的库完全是动态加载代码的一部分。后者意味着库不能被添加到Flink的/lib文件夹,而必须是应用程序的fat-jar/ super -jar的一部分
卸载用户代码中动态加载的类
所有涉及到动态用户代码类加载(会话)的场景都依赖于再次卸载类。类卸载意味着垃圾收集器发现类中不存在对象或更多对象,从而删除类(代码、静态变量、元数据等)。
每当TaskManager启动(或重启)一个任务时,它都会加载那个特定任务的代码。除非可以卸载类,否则这会造成内存泄漏,因为会加载新版本的类,并且加载的类总数会随着时间的推移而积累。这通常通过OutOfMemoryError:元空间来显示。
类泄漏的常见原因和修复建议:
-
延迟线程:确保应用程序函数/源/接收关闭所有线程。逗留的线程本身消耗资源,而且通常保存对(用户代码)对象的引用,从而阻止了垃圾收集和类的卸载。
-
Interners:避免在特殊的结构中缓存对象,这些结构会超过函数/源/接收器的生命周期。例如Guava的内部程序,或者Avro的类/对象缓存在序列化器中。
-
JDBC: JDBC驱动程序在用户代码类加载器外泄漏引用。要确保这些类只加载一次,你应该将驱动程序jar添加到Flink的lib/文件夹中,或者通过classloader.parent-first-patterns-additional将驱动程序类添加到父-first加载的类列表中。
卸载动态加载的类的一个有用工具是用户代码类加载器释放钩子。这些钩子是在卸载类加载器之前执行的。通常建议在常规函数生命周期中关闭和卸载资源(通常是close()方法)。但在某些情况下(例如对于静态字段),最好在确定不再需要类加载器时卸载。
类加载器释放钩子可以通过RuntimeContext.registerUserCodeClassLoaderReleaseHookIfAbsent()方法注册。
使用maven-shade-plugin解决Flink的依赖冲突。
从应用程序开发人员的角度解决依赖冲突的一种方法是通过隐藏它们来避免暴露依赖。
Apache Maven提供Maven -shade-plugin,它允许在编译后更改类的包(因此正在编写的代码不受阴影的影响)。例如,如果你有com。Amazonaws软件包从aws SDK在你的用户代码jar,阴影插件会重新安置他们到org.myorg.shaded.com Amazonaws软件包,这样你的代码调用你的aws SDK版本。
本文档页面解释了如何使用shage plugin重新定位类。
请注意,Flink的大多数依赖项,如guava, netty, jackson等,都被Flink的维护者遮蔽了,所以用户通常不必担心它。
火焰图
火焰图是一种可视化,可以有效地解答如下问题:
- 哪些方法目前正在消耗CPU资源?
- 一种方法的消耗与其他方法相比如何?
- 堆栈上的哪一系列调用导致执行特定的方法?

火焰图是通过多次采样叠加轨迹来构建的。每个方法调用都由一个条来表示,条的长度与它在样本中出现的次数成正比。
从Flink 1.13开始,Flink就原生支持火焰图形。为了生成火焰图,导航到正在运行的作业的作业图,选择感兴趣的算子,在菜单中右键单击火焰图选项卡:
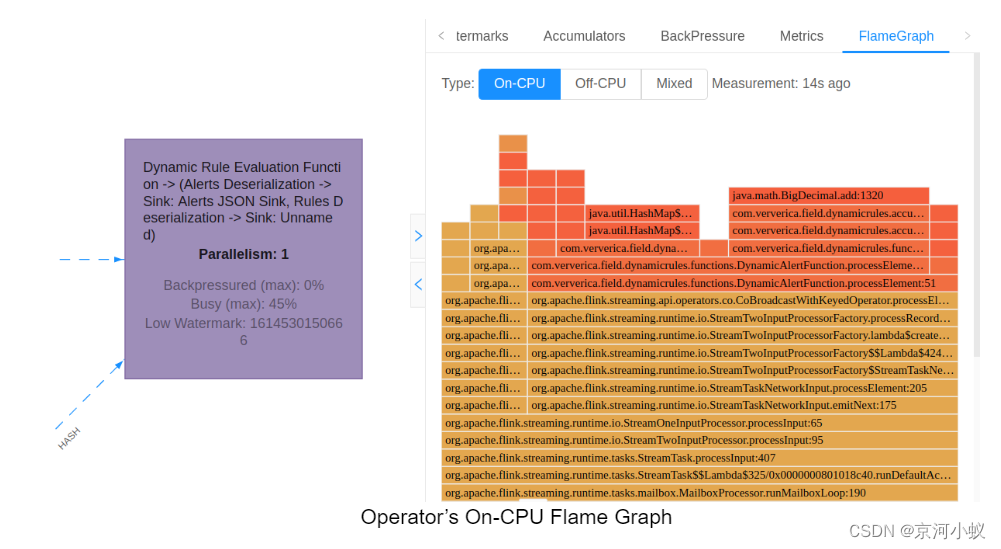
任何测量过程本身不可避免地会影响测量对象(见双分裂实验)。采样CPU堆栈跟踪也不例外。为了防止对生产环境的意外影响,Flame Graphs目前是一个可选择的功能。要启用它,你需要在conf/flink-conf.yaml中设置rest.flamegraph.enabled: true。我们建议在开发和预生产环境中启用它,但您应该将其作为生产环境中的一个实验性特性。
除了On-CPU火焰图形之外,Off-CPU和Mixed可视化也可以使用面板顶部的选择器进行切换:

Off-CPU Flame Graph可视化样本中发现的阻塞调用。区别如下:
- On-CPU: Thread.State in [RUNNABLE, NEW]
- Off-CPU: Thread.State in [TIMED_WAITING, WAITING, BLOCKED]

混合模式火焰图由线程在所有可能状态下的堆栈轨迹构造而成。

抽样过程
堆栈跟踪的集合纯粹是在JVM中完成的,因此只有Java运行时中的方法调用是可见的(没有系统调用)。
火焰图构造是在单个算子的层次上执行的,即该算子的所有任务线程并行采样,并将它们的堆栈轨迹组合起来。
注意:一个算子的所有线程的堆栈跟踪示例被组合在一起。如果一个方法调用在一个并行任务中消耗了100%的资源,而在其他并行任务中却没有,那么这个瓶颈可能会被平均化。
未来计划通过提供任务级别的“下钻”可视化来解决这一限制。
应用程序分析和调试
使用Apache Flink自定义日志记录概述
每个独立的JobManager、TaskManager、HistoryServer和ZooKeeper守护进程都将stdout和stderr重定向到一个后缀为.out的文件,并将内部日志写到后缀为.log的文件。由用户在env.java中配置的Java选项。选择,env.java.opts。jobmanager env.java.opts。同样地,env.java.opts.historyserver和env.java.opts.client也可以使用脚本变量FLINK_LOG_PREFIX来定义日志文件,并将选项括在双引号中以供后期计算。使用FLINK_LOG_PREFIX的日志文件与默认的.out和. Log文件一起旋转。
使用Java Flight Recorder进行分析
Java Flight Recorder是一个内置在Oracle JDK中的分析和事件收集框架。Java任务控制是一套先进的工具,支持对Java Flight Recorder收集的大量数据进行高效和详细的分析。示例配置:
env.java.opts: "-XX:+UnlockCommercialFeatures -XX:+UnlockDiagnosticVMOptions -XX:+FlightRecorder -XX:+DebugNonSafepoints -XX:FlightRecorderOptions=defaultrecording=true,dumponexit=true,dumponexitpath=${FLINK_LOG_PREFIX}.jfr"
Profiling with JITWatch
JITWatch是Java HotSpot JIT编译器的日志分析器和可视化工具,用于检查内联决策、热方法、字节码和汇编。示例配置:
env.java.opts: "-XX:+UnlockDiagnosticVMOptions -XX:+TraceClassLoading -XX:+LogCompilation -XX:LogFile=${FLINK_LOG_PREFIX}.jit -XX:+PrintAssembly"
分析内存不足问题
如果在Flink应用程序中遇到outofmemoryexception异常,那么在内存不足错误时启用堆转储是一个好主意。
env.java.opts: "-XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=${FLINK_LOG_PREFIX}.hprof"
通过堆转储,您可以分析用户代码中的潜在内存泄漏。如果内存泄漏应该是由Flink引起的,那么请联系开发人员的邮件列表。
分析内存和垃圾收集行为
内存使用和垃圾收集会对应用程序产生深远的影响。其影响范围从轻微的性能下降到GC暂停太长时的完全集群故障。如果您想更好地理解应用程序的内存和GC行为,那么您可以在TaskManagers上启用内存日志记录。
taskmanager.debug.memory.log: true
taskmanager.debug.memory.log-interval: 10000 // 10s interval
如果您对更详细的GC统计数据感兴趣,那么您可以通过以下方式激活JVM的GC日志:
env.java.opts: "-Xloggc:${FLINK_LOG_PREFIX}.gc.log -XX:+PrintGCApplicationStoppedTime -XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:+UseGCLogFileRotation -XX:NumberOfGCLogFiles=10 -XX:GCLogFileSize=10M -XX:+PrintPromotionFailure -XX:+PrintGCCause"

















 2049
2049











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











