







写在前面
写这篇文章的目的是因为在删除重复数据时,遇到了Pg数据库delete语句后面不支持limit关键字。本文适应于有一定工作经验且有SQL基础的同学。
一、场景描述
最近接手了一个老项目,在分析存储过程的时候,发现Pg数据库中有一张配置表出现了 完全相同(所有字段,连id都一样) 的数据。其结果造成前端页面展示时,下拉框出现了重复值。那么面临的问题,很显然就是如何删除重复的数据?
二、问题分析
常规思路:数据重复了,那我把多余的查出来,删了不就完事儿了,开始写sql。首先group by,通过having count(*) > 1的,找到重复数据的id(本文中的这个场景,id值也重复);然后 DELETE FROM table WHERE id = ? LIMIT ?;
select * from table group by ... having count(*) > 1;
delete from table where id = ? limit ?;
但是,在执行delete 语句时报错了,错误是ERROR: syntax error at or near "limit"。经资料查询,MySQL支持delete后面加limit ,而PgSQL 在update/delete后面均不支持limit。 怎么搞?
!注意:数据无价,更新删除操作前,请先备份数据。
三、解决思路
由于行记录没有唯一属性,既然在当前表中不能直接操作数据,那么我就先建立一张临时表,把去除重复发后的数据取出来放到临时表中。然后删除原表中的数据,再把临时表中的数据倒腾回去,最后删除临时表。下面,用一个简单的例子演示一下。
四、具体步骤
1.环境说明
| 名称 | 说明 |
|---|---|
| 数据库版本 | PostgreSQL 12.3 |
2.创建表/初试化数据
CREATE TABLE code
(
id CHARACTER VARYING(255)
);
INSERT INTO code
VALUES
(1),
(2),
(3),
(4),
(3),
(4),
(1),
(1);
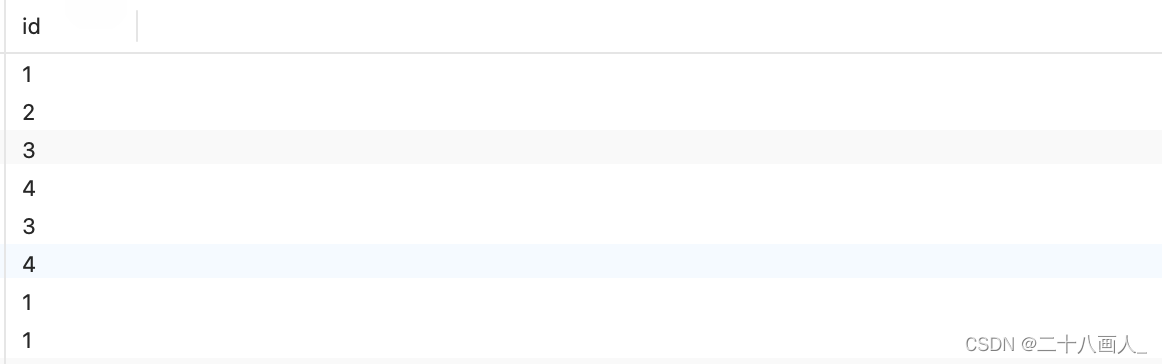
3.查看表数据
SELECT * FROM code;
4.清洗数据
CREATE TABLE temp
(
id CHARACTER VARYING(255)
);
INSERT INTO temp
SELECT * FROM code WHERE id NOT in (
SELECT id FROM code GROUP BY id HAVING COUNT(*) > 1
)
UNION
SELECT * FROM code GROUP BY id HAVING COUNT(*) > 1;
TRUNCATE TABLE code;
INSERT INTO code
SELECT * FROM temp;
DROP TABLE temp;
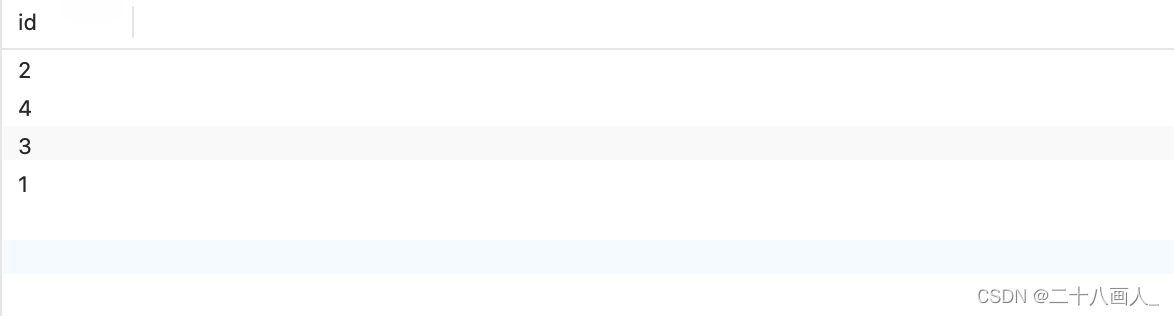
5.查看表数据
SELECT * FROM code;
五、总结
出现以上的问题,根源在于表结构在最初设计时没有考虑唯一约束,导致多人维护出现数据重复,因此在建表时,一定要建主键或者唯一索引保证记录的唯一性。
六、参考资料
写在后面
如果本文内容对您有价值或者有启发的话,欢迎点赞、关注、评论和转发。您的反馈和陪伴将促进我们共同进步和成长。














 1293
1293











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









